These days, a lot of businesses rely on AI to enhance their products and services. Because of this, we currently live in a world where people get to experience awesome self-driving cars and highly personalized shopping experiences. However, this advanced technology depends on a critical yet frequently overlooked process known as data annotation. AI models require high-quality labeled data to learn and perform tasks effectively.
Big companies like Google, Facebook, and Amazon heavily rely on data annotation to power their AI applications. For instance, Google uses annotated data to train its image recognition software, allowing users to search for information simply by snapping a picture. Facebook employs annotated data to personalize news feeds and identify potentially harmful content, while Amazon utilizes it to recommend products you might be interested in. In essence, data annotation bridges the gap between raw data and intelligent systems, shaping the future of AI-powered business solutions. In this blog post, we’ll discuss everything you need to know about data annotation, exploring its different types, the tools used, and the core principles behind how it works.
What is Data Annotation?
Data annotation is the essential process of labeling raw data, such as images, text, or audio, to add context and meaning to machine learning models. This involves marking specific features within the data, essentially training the AI on what to look for. This labeled data becomes the building block for algorithms to learn patterns and make predictions, ultimately fueling the development of intelligent business solutions across various industries.
For instance, a company developing a self-driving car might use data annotation to label images and identify pedestrians, traffic signs, and lane markings. This annotated data would then be used to train the car’s AI system to recognize these elements in real time, enabling it to navigate roads safely. Data annotation bridges the gap between raw data and intelligent systems, empowering businesses to leverage the power of AI for smarter decision-making, improved customer experiences, and, ultimately, significant growth.
Key Market Takeaways for Data Annotation Tools
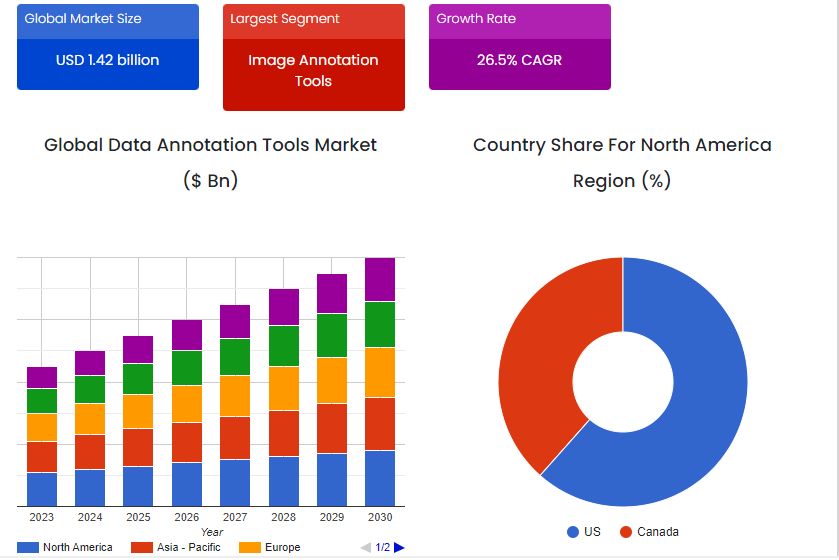
Source: SkyQuest
This surge aligns perfectly with the recent boom in AI and ML applications across various industries. However, for these powerful technologies to function effectively, they require vast amounts of meticulously labeled data. This is where data annotation tools come in!
According to a recent press release by Custom Market Insights, the increasing significance of high-quality, well-labeled data is a key driver for the data annotation market. These tools enable businesses to streamline the data annotation process, guaranteeing the quality and accuracy of data used for training AI models. This can be really beneficial in sectors such as healthcare, where even minor errors in data labeling can have substantial consequences.
Take the Mayo Clinic, for instance, which uses a lot of data annotation tools to train its AI models for medical image analysis. These tools empower teams of medical professionals to efficiently label vast amounts of X-ray, MRI, and CT scan data. This labeled data is then used to train AI algorithms to identify abnormalities and diseases with high accuracy, potentially leading to earlier diagnoses and improved patient outcomes.
What are the Types of Data Annotation?
Data annotation is the lifeblood of AI, meticulously transforming raw data into a language machines can understand. Did you know a single self-driving car can require millions of labeled images for its AI systems to navigate the road safely?
This annotated data acts as the “ground truth” for AI, allowing it to make informed decisions and power advancements across various fields.
There are two primary domains that rely on data annotation the most,
Computer Vision (CV)
Here, data annotation focuses on labeling visual elements within images, photos, and videos. Businesses across various sectors utilize CVs for tasks like object recognition in self-checkout systems, facial detection for security purposes, and motion tracking in athletic performance analysis. The accuracy of these applications hinges on the quality of data annotation. Precisely labeled data, achieved through annotation tools, empowers CV models to interpret visual information with exceptional accuracy.
Natural Language Processing (NLP)
Natural language processing (NLP) is another field where data annotation thrives. Here, the focus shifts to textual information and language-related elements. Businesses can utilize annotation tools for tasks like text classification, sentiment analysis, and named entity recognition. For instance, a social media company might use NLP annotation to categorize customer reviews as positive, negative, or neutral. This empowers the company to understand customer sentiment and make data-driven decisions regarding product development or marketing strategies.
What are the Types of Data Annotation in Computer Visions?
Here are some types of data annotations used for refining computer vision technologies,
1. Image Categorization
Several key tasks within CV rely heavily on data annotation. One such task is image categorization, which involves labeling or classifying entire photos. Businesses might leverage this for applications like content moderation on social media platforms, where images are automatically categorized to identify inappropriate content. Techniques like bounding box annotation, where a box is drawn around an object, or semantic segmentation, where each pixel is assigned a category label (e.g., “sky” or “car”), are commonly used for this purpose.
2. Object Recognition/Detection
Object recognition and detection is another crucial CV task fueled by data annotation. Here, the focus is on identifying and labeling specific objects within an image. This is essential for businesses developing self-driving cars, where AI models need to recognize and react to pedestrians, traffic lights, and other objects on the road. Bounding boxes and polygon annotations, where a more precise shape is drawn around the object, are common methods for this task. Businesses can utilize specialized annotation tools like CVAT or LabelBox to streamline this process.
3. Segmentation
Segmentation is a powerful approach that goes beyond simply identifying objects. Here, the image is meticulously divided into distinct segments, with each segment assigned a specific label. This allows for a more precise understanding of the scene. There are three main types of commonly used segmentation:
Semantic Segmentation
This technique assigns a category label to each individual pixel in the image. For instance, a self-driving car company can use semantic segmentation to label every pixel in a street scene. The road would be labeled as “asphalt,” pedestrians as “people,” and traffic lights as “traffic signals.” This comprehensive labeling empowers the AI model to understand the entire visual environment.
Instance Segmentation
This technique takes segmentation a step further by differentiating between individual instances of the same object class. For example, in an image containing multiple cars, instance segmentation would not only label all the cars but also distinguish between them, allowing the AI model to count the number of cars or track their movements.
Panoptic Segmentation
This cutting-edge technique combines the strengths of both semantic and instance segmentation. It provides a complete picture, labeling every pixel in the image and differentiating between object instances. This is particularly valuable for applications in autonomous vehicles or robotics, where a nuanced understanding of the environment is critical.
4. Boundary Recognition
While segmentation excels at labeling image regions, boundary recognition focuses on annotating specific lines or borders within an image. This provides crucial data for tasks requiring a precise understanding of spatial relationships. For instance, self-driving car companies leverage boundary recognition to label traffic lanes. Here, annotators meticulously trace lane markings, creating a digital map for the AI model to navigate. Similarly, construction companies might utilize this technique to identify property boundaries in aerial photos. Specialized tools allow for drawing precise polylines or leveraging existing geospatial data to streamline the process.
5. Video Labeling
Video labeling tackles the challenge of extracting information from dynamic visual data. Here, videos are broken down into individual frames, each requiring meticulous annotation. Techniques like background subtraction isolate moving objects from the static background, while foreground detection focuses on identifying and labeling the objects themselves. This detailed frame-by-frame annotation is essential for applications in video surveillance. Security companies can leverage video labeling to train AI models for anomaly detection, allowing them to flag suspicious activity. Similarly, in medical imaging analysis, subtle changes in movement patterns within a video sequence, like blood flow variations, might be crucial for diagnosing health issues.
Data Annotation in Natural Language Processing
Data annotation in NLP involves tagging text or speech data to create labeled datasets for machine learning models. It is essential to develop supervised NLP models for various tasks. Here are the important types of data annotation methods used in NLP:
1. Entity Annotation
Entity annotation forms the cornerstone of NLP data annotation. Here, unstructured sentences are transformed by adding labels to specific elements like names, locations, and key phrases. This labeled data is crucial for tasks like chatbot development. For instance, a customer service chatbot can use entity annotation to recognize names, locations of service centers, and product types within customer queries, enabling the chatbot to provide accurate responses.
Businesses can even customize entity annotation based on their specific needs. For instance, a social media company might focus on identifying sentiment-rich words like “happy” or “frustrated” to understand customer opinions.
There are also some subsets of entity annotation you should know about,
Named Entity Recognition (NER):
Named Entity Recognition (NER) is a critical subset of entity annotation. It focuses on identifying and labeling specific entities within the text, such as people (Elon Musk), organizations (Tesla), locations (Paris), dates (July 4th), monetary values ($10), and more. This labeled data is instrumental in information extraction tasks. An NLP model trained on news articles with NER annotations can pinpoint these entities, facilitating further analysis or retrieval of specific information. NER empowers machines to understand the “who, what, when, and where” of textual data.
Keyphrase Extraction:
Extracting key themes and ideas is another cornerstone of NLP. Keyphrase extraction tackles this challenge by identifying and labeling the most important phrases within a document. This empowers businesses to automatically grasp the central content of reviews, articles, or social media posts. For instance, an online retailer can analyze customer reviews, where keyphrase extraction can pinpoint phrases like “long battery life” or “disappointed with screen quality.” This enables businesses to comprehend customer preferences and enhance their products or services.
Part-of-Speech (POS) Tagging:
Part-of-speech (POS) tagging delves deeper than entity annotation, assigning grammatical labels (parts of speech) to each word in a sentence. This detailed breakdown, including nouns, verbs, adjectives, adverbs, etc., is essential for tasks like sentiment analysis or machine translation. By understanding the grammatical role of each word, NLP models can decipher the sentence structure and meaning. For instance, POS tagging allows an NLP model analyzing reviews to differentiate between positive adjectives (“great”) and negative adjectives (“disappointed”), leading to a more accurate understanding of customer sentiment.
Entity Linking:
Entity linking, the final piece of the entity annotation puzzle, connects named entities in the text to relevant entries within a knowledge base. Imagine a news article mentioning “Elon Musk.” Entity linking can connect “Elon Musk” to a database entry containing his biography, the companies he leads, or even his social media profiles. This injects real-world context into the data. Businesses can leverage this for tasks like building virtual assistants or chatbots. A virtual assistant equipped with entity linking can understand your request to “find information about Elon Musk” and utilize the linked knowledge base to provide a comprehensive response.
2. Text Classification
Natural Language Processing doesn’t just focus on understanding individual words – it also needs to grasp the overall meaning and purpose of text. This is where text classification comes into play. It’s the process of assigning a single label to a piece of text, like an entire document, email, or social media post. This labeled data empowers NLP models to categorize and organize large volumes of textual information efficiently.
There are several key applications of text classification that benefit businesses across various sectors.
Document Categorization:
A prominent application of text classification is document categorization. Here, the goal is to sort documents into pre-defined categories based on their content automatically. For instance, companies dealing with a high volume of customer reviews can leverage this. Text classification can categorize these reviews as positive, negative, or neutral, enabling faster response times and sentiment analysis of customer feedback. Similarly, businesses can utilize this technique for content recommendation or information retrieval. A news website, for instance, can automatically categorize incoming articles by topic using text classification. This allows for efficient organization and content delivery tailored to users with specific interests.
Sentiment Annotation:
Another important application is sentiment analysis, which examines the emotional tone of the text. It involves identifying and labeling the sentiment expressed in a piece of text. This can be positive, negative, or neutral. This can be really valuable for businesses that rely on customer feedback. By analyzing social media posts or online reviews, businesses can assess customer satisfaction and pinpoint areas for improvement. For example, a travel company can utilize sentiment analysis to evaluate hotel reviews. Understanding which aspects receive positive or negative sentiment enables businesses to customize their offerings for an enhanced customer experience.
Intent Annotation:
Finally, intent annotation focuses on uncovering the intended purpose or meaning behind text or user input. This is vital for tasks like chatbot development. Businesses can leverage intent annotation to train chatbots to recognize the user’s objective within a message. For instance, the text “Book a flight from Los Angeles to London for next Monday” would be classified as a flight booking request. This empowers chatbots to provide targeted responses and streamline user interactions.
Some Important Data Annotation Tools
| Tool | Overview | Key Features | Ideal For |
| Labelbox | Cloud-based platform with advanced features | User-friendly interface, AI-assisted labeling, QA/QC tools, Python SDK | Businesses & organizations |
| CVAT (Computer Vision Annotation Tool) | Open-source, web-based platform | Polygon, bounding box, key point labeling, semantic segmentation | Researchers & developers |
| Diffgram | Data labeling & management platform | Polygons, bounding boxes, lines, segmentation masks, collaboration features | Collaborative projects & data management |
| Prodigy | Speeds up the labeling process | Text, image, audio annotation, active learning, collaboration features | Projects with advanced needs & existing workflows |
| Brat | Open-source tool for text data annotation | Entity, relation, event, temporal expression annotation | NLP researchers & developers |
What Are the Popular Data Annotation Techniques?
To make your AI algorithms run smoothly, you have to choose the right annotation techniques; otherwise, things might go south pretty fast!
Let’s explore some of the most common techniques used to make machines smarter,
1. Bounding Boxes: A Simple and Adaptable Approach
Rectangular or square boxes drawn around target objects in images or video frames are a fundamental technique known as bounding boxes. This straightforward approach is widely used in object detection tasks, particularly for simple items like food packaging or traffic signs. Its adaptability makes it a popular choice when the precise shape of the object is not critical. However, bounding boxes have limitations. They become less effective for complex objects lacking right angles and struggle to capture detailed shapes.
2. Polygonal Segmentation: Enhancing Precision for Complex Objects
For scenarios where intricate shapes demand greater accuracy, polygonal segmentation comes into play. This technique utilizes polygons – shapes with multiple connected sides – to depict complex objects more accurately than bounding boxes. Car manufacturers, for instance, might leverage polygonal segmentation to annotate training data for self-driving cars. This allows for precise delineation of car boundaries, removing unnecessary pixels and improving model performance. While offering a significant advantage in precision, polygonal segmentation can encounter challenges with overlapping objects or highly complex scenes.
3. Polylines: Capturing Linear Features with Accuracy
When dealing with linear features like lanes or sidewalks in datasets for autonomous vehicles, polylines offer a valuable technique. This method involves plotting continuous lines or segments to indicate the positions or boundaries of objects. Compared to bounding boxes, polylines provide a more accurate representation of linear characteristics. However, their application is limited to non-linear objects or features with significant width.
4. Landmarking: Precisely Identifying Key Points of Interest
Landmarking is a technique employed for tasks like facial recognition, human body posture analysis, and aerial imagery annotation. Here, small dots are placed on specific locations of interest within an image. This meticulous approach is ideal for identifying precise points like facial features or body joints. However, it can be time-consuming, especially for large datasets or intricate images, and prone to errors.
5. Tracking: Capturing Movement Across Frames
Tracking is an essential technique for tasks involving motion analysis. This method involves annotating the movement of objects across multiple frames within a video or image sequence. Applications include surveillance systems, action recognition in sports videos, and autonomous driving projects. Tracking can significantly save time with interpolation techniques, where the system automatically fills in gaps between annotated frames. However, it can be time-consuming, especially for lengthy recordings or complex scenes with numerous moving objects.
6. 2D vs. 3D Bounding Boxes: Adding Depth to Object Detection
Bounding boxes come in two flavors: 2D and 3D. 2D bounding boxes are drawn to locate and categorize objects within an image. Their simplicity and ease of implementation make them a common choice in object detection tasks. However, they may not capture fine-grained features or be suitable for precise object localization in intricate situations.
3D bounding boxes expand this concept into the third dimension. This technique is used in 3D object detection, scene understanding, and robotics applications. By incorporating depth information, 3D bounding boxes provide detailed data about an object’s 3D spatial characteristics. While offering a significant advantage for tasks involving spatial reasoning, 3D bounding boxes are more difficult and time-consuming to annotate due to the need for precise estimation of 3D attributes from 2D images or videos.
7. Polygonal Annotation
While both polygonal annotation and segmentation techniques focus on capturing object shapes, they differ in approach. Polygonal annotation involves tracing the outline of objects using an intricate network of connected vertices to create a closed polygon shape. This method is ideal for capturing complex object shapes that bounding boxes cannot depict accurately. For instance, e-commerce companies might use polygonal annotation to precisely label clothing items in product images. However, this technique can be time-consuming, especially for intricate objects, and requires meticulous delineation of item boundaries.
Why Should You Care about Data Annotation?
If you are still unsure about whether you should really care about data annotation or not, remember that a recent study by Stanford University showed that well-annotated data can improve the accuracy of image recognition models by up to 20%.
Let us explain why they are right,
1. Building Models with Laser Focus: The Accuracy Advantage
Accurate data annotation is crucial for developing precise machine-learning models. Just as a student benefits from clear instructions, models trained on well-annotated data learn effectively and accurately. Conversely, poorly labeled data can result in misinterpretations, leading to decreased performance and inaccurate predictions. For example, in image recognition, a model might mistake a cat for a dog. This can have significant implications for businesses, such as in the case of a social media platform using poorly annotated data for sentiment analysis. Misclassifying positive comments as negative could skew customer insights and lead to ineffective marketing strategies.
2. Generalization: Expanding the Model’s Universe
The power of AI lies in its ability to adapt and learn from new situations. High-quality data annotation plays a vital role in achieving this. By training models on well-labeled data, businesses can foster a process called generalization. Here, the model learns the underlying patterns and relationships within the data, allowing it to perform well even when encountering unseen data. For example, the ability of an autonomous vehicle to navigate diverse road conditions and recognize various objects beyond its specific training data is crucial to its success. Precisely annotated data ensures the model can be generalized effectively, making autonomous driving a safer and more reliable reality.
3. Saving Time and Resources: A Smarter Investment
Investing in high-quality data annotation upfront can lead to significant cost and time savings down the line. Models trained on clean and accurate data require fewer training iterations and less fine-tuning. This translates to faster deployment and reduced retraining costs – a win for any business. For instance, a well-annotated dataset for a medical diagnosis model can significantly expedite the development process. This reduces the need for extensive post-deployment adjustments and updates, allowing healthcare companies to implement the model sooner and improve patient care.
4. Building Trustworthy AI: The Cornerstone of Adoption
For AI models to be truly impactful, they need to be reliable and trustworthy. High-quality data annotation plays a crucial role in achieving this. By ensuring the data used to train models is accurate and unbiased, businesses can create trustworthy AI systems that users can rely on for critical applications. In the financial services industry, for instance, accurate data annotation is paramount for models used in credit scoring or fraud detection. High-quality data ensures these models provide reliable results, increasing user trust and adoption of these financial technologies.
How to Ensure the Consistency and Accuracy of Annotated Data?
As we all know, when it comes to data annotation, inconsistent or inaccurate data can lead to biased models that perform poorly, ultimately hindering your AI initiatives. Here, we’ll explore key strategies that businesses can implement to guarantee high-quality data annotation.
1. Inter-annotator Agreement: Measuring Consistency
One critical strategy is inter-annotator agreement. This metric measures the level of consistency between annotators working on the same data. Businesses can establish clear annotation guidelines and provide training for annotators to ensure they understand the labeling criteria. IAA scores, often calculated using metrics like Cohen’s kappa, can then be used to evaluate consistency. For instance, a social media company using data annotation to train a sentiment analysis model might achieve a high IAA score by ensuring all annotators consistently label positive and negative customer reviews.
2. Quality Control Measures: A Multi-Layered Approach
Beyond IAA, a robust quality control process is essential. This might involve assigning multiple annotators to the same data points, with any discrepancies flagged for review by a senior team member. Additionally, businesses can leverage tools that automatically detect inconsistencies, further safeguarding the accuracy of the labeled data. For example, a company developing an autonomous vehicle might utilize quality control measures to ensure all images used to train the car’s object recognition model are consistently labeled with accurate bounding boxes for pedestrians, traffic signs, and other crucial elements.
3. Active Learning: Optimizing Efforts
Active learning is a technique that can further enhance data annotation efficiency and accuracy. Here, the machine learning model itself plays a role in the labeling process. The model identifies data points where it’s least confident and requests those for annotation. This prioritizes labeling the most valuable data for the model’s learning, saving time and resources. An e-commerce company using data annotation to train its image recognition model for product searches might leverage active learning to prioritize labeling of ambiguous product images, ensuring the model can accurately categorize a wider range of products.
How Can Bias Be Mitigated in the Data Annotation Process?
Sometimes, biased data annotation practices can lead to biased AI models, potentially causing unfair or inaccurate outcomes. For businesses looking to build trustworthy and ethical AI systems, mitigating bias in data annotation is essential. Let’s explore key strategies to achieve this:
1. Diverse Annotation Teams
The composition of your data annotation team significantly impacts the potential for bias. By fostering diversity in ethnicity, gender, age, and other relevant factors, businesses can create a team with a broader range of perspectives. This diversity allows for the identification and mitigation of potential biases that might exist within the data itself. For example, a company developing a facial recognition system might assemble a team with individuals from various ethnicities to ensure the model accurately recognizes faces across different demographics.
2. Blind Annotation Techniques
Another strategy involves implementing “blind” annotation techniques. This means removing any information from the data that could potentially influence the annotator’s labeling decisions. Consider a company building an automated resume screening tool. By removing details like applicant names and universities from resumes during annotation, the company can mitigate bias based on factors unrelated to job qualifications.
3. Data Augmentation: Expanding the Training Universe
Data augmentation involves artificially expanding the labeled data to include variations and edge cases that might not be present in the original dataset. This helps the model learn from a broader range of scenarios and reduces the influence of any inherent biases within the original data. For instance, a company training a self-driving car’s object recognition model might use data augmentation to create variations of traffic light images with different lighting conditions or angles. This ensures the model can recognize traffic lights accurately regardless of real-world variations.
4. Continuous Monitoring and Improvement
Mitigating bias is an ongoing process. Businesses should continuously monitor their data annotation practices and the performance of their AI models to identify and address any emerging bias issues. This might involve analyzing model outputs for signs of bias and refining annotation guidelines based on new findings. For example, a social media platform using data annotation to train a content moderation system might regularly evaluate the system’s ability to identify hate speech across different languages and cultures. By adjusting annotation practices based on these evaluations, the platform can strive for fair and unbiased content moderation.
A Detailed Stepwise Guide to Annotate Text Data
Let’s explore a step-by-step approach to annotating text data using Python, a popular programming language for AI development.
This process involves labeling specific elements within text data to provide context and meaning for the machine learning model.
1. Gearing Up
The first step is to set up the development environment. Utilize Python libraries such as streamlit and st-annotated-text. These libraries can be effortlessly installed using the pip package manager, ensuring a smooth start to the annotation process.
2. Highlighting Key Elements
The annotated_text function serves as the heart of this process. This function takes plain text data or a series of tuples as input. Each tuple comprises an annotated word and its corresponding label. The function then displays the text with these annotated words highlighted, along with their labels positioned beside them. This visual representation simplifies the annotation process and clarifies the relationship between specific words and their assigned categories.
3. Building Complexity
The ability to pass lists, including nested lists, to the annotated_text function empowers the creation of intricate annotations. This allows for structured highlighting and labeling within the text data.
4. Customizing the Look and Feel
For enhanced clarity and visual appeal, annotations can be customized with background and foreground colors. The third element within a tuple specifies the background color, while the fourth element (if provided) sets the foreground color. This allows businesses to tailor the annotation display to match their unique branding or specific project requirements.
5. Defining the Perfect Look
The visual presentation of annotated text can be further customized by overriding default parameters. These parameters include color, font size, border radius, and padding. This level of control empowers businesses to create distinct styles for their annotated text, ensuring it aligns seamlessly with their workflow and preferences.
6. Beyond the Basics
For projects demanding exceptionally detailed customization, businesses can leverage the power of CSS styles. The annotation function allows for the application of custom CSS properties to the annotated text, providing granular control over its appearance. This is particularly valuable for companies with specific design requirements or intricate annotation schemes.
Top 5 Case Studies of Businesses Using Data Annotation
Data annotation isn’t just about fancy tech – it’s having a real impact on businesses across industries. So, let’s discuss some real-world examples of how companies are using data annotation to unlock the true potential of AI!
1. Autonomous Vehicles: Seeing the Road Ahead – Waymo’s Latest Advancements
Waymo remains a leader in self-driving car technology, and its commitment to data annotation continues to be a driving force. A recent article in Forbes highlights their progress in reducing disengagements, where a human driver needs to take control. This advancement can be attributed in part to the quality and scale of their annotated datasets. Waymo utilizes massive datasets containing images and videos captured from their self-driving vehicles. Annotators meticulously label these datasets, identifying objects like pedestrians, traffic signs, and lanes. This labeled data trains Waymo’s machine learning models to “see” the world around them with ever-increasing accuracy, paving the way for a future of autonomous transportation.
2. Healthcare: Unlocking Medical Insights with Paige.ai’s Growing Impact
Paige.ai, a healthcare AI company, is a prime example of how data annotation is revolutionizing medical diagnosis. A recent press release details their FDA clearance for Paige Pathfinder, an AI-powered tool for cancer diagnosis. This achievement is a testament to the power of data annotation. Medical professionals annotate pathology images – digital slides of tissue samples – highlighting cancerous cells and other relevant features. This annotated data empowers Paige.ai’s models to analyze new pathology images with high accuracy, potentially helping doctors in faster and more accurate diagnoses, ultimately improving patient outcomes.
3. E-commerce: Amazon’s Continued Focus on Customer Experience
E-commerce giant Amazon remains at the forefront of personalization, and data annotation plays a crucial role in this strategy. A recent CNBC article sheds light on the company’s extensive use of data to personalize the shopping experience. They annotate product images with various attributes like color, size, and brand. This labeled data trains image recognition models that can recommend similar products to customers based on their browsing history and past purchases with remarkable accuracy. Data annotation also helps Amazon improve its product search function by ensuring accurate image-based product retrieval, leading to a more satisfying customer experience.
4. Social Media: Content Moderation and Beyond – Facebook’s Ongoing Efforts
Facebook (now Meta) is still dealing with the challenges of content moderation, and data annotation plays a crucial role in this ongoing effort. Facebook uses annotators which label content like hate speech, violent imagery, and misinformation. These labeled datasets train algorithms to automatically identify and flag potentially harmful content, helping to maintain a safer online environment. However, a recent Reuters article highlights the ongoing challenges of bias and the need for continuous improvement. As social media platforms face increasing pressure to address harmful content, data annotation will likely play an even more significant role in the future, requiring ongoing investment in high-quality, unbiased datasets.
5. Robotics: Learning from Experience – Boston Dynamics Pushes the Boundaries
Boston Dynamics, a company renowned for its advanced robots, continues to push the boundaries of what’s possible. Their commitment to data annotation is a key factor in their success. A recent IEEE Spectrum article details their latest advancements in robot agility. For instance, annotators might label video footage of robots performing tasks, highlighting successful actions and areas for improvement. This labeled data trains machine-learning models that can analyze the robots’ performance.
Conclusion
Accurately labeling data, whether it’s text, images, or audio, allows businesses to provide the necessary context and meaning for machines to learn and perform effectively. It’s similar to teaching a new language – the more precise the instructions, the better the AI will understand. The real benefit for businesses is that high-quality data annotation leads to smarter AI models. This results in fewer errors, faster processing, and, ultimately, happier customers.
Nowadays, AI is everywhere. However, to unlock its true potential, you need to provide your AI with the right knowledge base. Data annotation is the secret weapon that ensures your AI becomes a valuable asset, not a source of frustration. So, embrace the power of well-annotated data – your AI will thank you for it!
Are You a Fan of Data Annotation? Need Help Leveraging This Technology for Your AI Projects?
At Idea Usher, we bring over 500,000 hours of coding experience to the table, helping businesses like yours leverage data annotation to create powerful AI projects. We’ll be your partner in building a strong foundation for your AI so you can focus on innovation and watch your machine-learning models soar. Start annotating with us today!


FAQs
Q1: What are data annotation tools?
A1: Data annotation tools are specialized software platforms designed to streamline the process of labeling data for machine learning models. Imagine them as digital workbenches for annotators. These tools offer features like image tagging, text classification, and object bounding boxes, making the labeling process efficient and accurate. Popular options include Labelbox and Supervise.ly, which cater to various data types like images, videos, and text. By simplifying the annotation process, these tools empower businesses to create high-quality labeled data, the fuel that drives powerful AI applications.
Q2: Which tool is used for annotation?
A2: Several tools are used for data annotation, depending on the data type. Popular options include platforms like Labelbox or Supervise.ly, which offer user-friendly interfaces for tasks like image and video annotation. These tools allow annotators to draw bounding boxes around objects, classify images by content, or transcribe audio recordings. The specific tool choice hinges on the project’s requirements, but all aim to streamline the annotation process and ensure high-quality labeled data for machine learning models.
Q3: What is the work of annotation?
A3: In the realm of AI, data annotation is the meticulous task of labeling data to give it meaning to machines. Think of it as creating flashcards for your AI assistant. For instance, an image of a cat might be labeled “feline” to help an AI image recognition model learn to identify cats in photos. This labeled data empowers machines to learn from examples and perform tasks with greater accuracy.
Q4: What is data annotation with an example?
A4: Data annotation is the process of labeling data, like text or images, to add context for machine learning models. Imagine training a self-driving car to recognize objects. Annotators would meticulously label images, highlighting cars, pedestrians, and traffic signs. This labeled data teaches the model to “see” the world and navigate it safely. By providing clear instructions, data annotation empowers machines to learn and perform tasks with greater accuracy.