




Key Takeaways
- Kubernetes platform engineering helps scaling teams simplify infrastructure through automation and standardized workflows.
- Organizations improve productivity, strengthen security, reduce bottlenecks, and optimize cloud costs with Kubernetes operations.
- GitOps, Internal Developer Platforms, service mesh, and AI-driven automation support scalable Kubernetes environments.
- A strong platform engineering approach improves consistency, reduces infrastructure drift, and enables faster software delivery.
- How IdeaUsher helps businesses scale Kubernetes platforms with pre-vetted developers experienced in automation and multi-cloud infrastructure management.
Kubernetes is not the reason scaling teams slow down. Poor internal platform design is. Most companies adopted Kubernetes to improve engineering agility, but as teams grow, infrastructure complexity grows even faster. Developers end up waiting on DevOps approvals, managing inconsistent environments, and spending more time maintaining systems instead of shipping products.
Engineering teams want self-service platforms, standardized workflows, and automated guardrails that reduce friction without sacrificing reliability. This is why Kubernetes platform engineering is becoming a competitive advantage, helping businesses scale engineering output, improve developer velocity, and maintain infrastructure consistency as teams expand.
We’ve helped businesses build Kubernetes platforms that improve developer velocity, reduce operational overhead, and standardize infrastructure workflows across scaling engineering teams. In this blog, we’ll explore the key benefits of Kubernetes platform engineering and how it helps organizations scale faster without increasing infrastructure complexity.
Why Kubernetes Scaling Becomes Difficult?
According to SkyQuest, the Global Kubernetes Market size was valued at USD 2.11 Billion in 2024 and is poised to grow from USD 2.61 Billion in 2025 to USD 14.61 Billion by 2033, growing at a CAGR of 24% during the forecast period (2026–2033). This massive capital shift toward cloud-native architectures presents a paradox for investors. While adoption is surging, the friction of scaling increases proportionally, turning what should be a linear expansion into a complex struggle with networking, security, and resource allocation that can quickly erode expected ROI.

Source: SkyQuest
The transition from a functional startup setup to an efficient enterprise platform often reveals deep operational vulnerabilities. Without a strategic commitment to automation and standardized configurations, the infrastructure becomes a fragile ecosystem. For decision-makers, the risk is clear: a single misconfiguration in a manual environment can trigger cascading failures, transforming a high-potential digital asset into a significant drain on capital and organizational velocity.
Operational Complexity
The initial allure of Kubernetes is its promise of portability and automation, but the reality for large-scale investors is that adoption often outpaces operational maturity. As you scale, you are not just managing containers. You are managing a sophisticated distributed system that requires constant tuning. The complexity manifests in several critical areas:
- Observability Overload: In a scaled environment, generating logs and metrics is easy, but extracting actionable intelligence is difficult. Investors often see rising costs in monitoring taxes, where the tools used to watch the system cost nearly as much as the infrastructure itself.
- Security and Compliance: Maintaining a consistent security posture across hundreds of microservices requires sophisticated RBAC (Role-Based Access Control) and network policies. For platforms handling sensitive financial or personal data, the cost of ensuring compliance across every node and pod increases exponentially with scale.
- Resource Management: Inefficient horizontal and vertical pod autoscaling often leads to either cloud waste, where you pay for idle resources, or performance degradation during peak traffic. Finding the Goldilocks zone of resource allocation requires deep technical expertise that is often scarce.
From a strategic investment perspective, this complexity means that the Total Cost of Ownership of a Kubernetes platform is often back-loaded. The capital is not just spent on the initial build. It is continuously consumed by the need for specialized engineers to manage the intricate web of service meshes, ingress controllers, and persistent storage volumes that keep the platform viable.
DevOps Bottlenecks
Entrepreneurs often mistakenly assume that hiring more developers will naturally accelerate deployment cycles. In a Kubernetes environment, the inverse is frequently true if the platform lacks maturity. As the system expands, the DevOps team often pivots from high-value architectural building to reactive firefighting. This shift turns specialized engineers into gatekeepers for every minor configuration change, creating a dangerous centralization of knowledge that effectively paralyzes the product roadmap.
This operational bottleneck has a direct impact on capital efficiency. Because the talent market for Kubernetes experts is highly competitive, the business burn rate often climbs to support an increasing ratio of operators to developers. Without strategic investments in internal developer platforms or advanced automation, investors find their high-cost engineering talent trapped in low-value maintenance. Ultimately, this human bottleneck restricts the ability of the business to pivot or scale, regardless of the amount of capital deployed.
Innovation Slowdown
The ultimate goal of any platform investment is to enable developers to ship code faster and more reliably. However, Kubernetes was built as a system for operators, not necessarily for application developers. When developers are forced to interact directly with the complexities of Kubernetes, including understanding service abstractions, sidecars, and deployment strategies, their productivity plummets.
This cognitive load is a silent killer of innovation. When a developer has to spend hours debugging why a pod will not start or why a service cannot reach a database due to a complex mesh policy, they are not building features that drive revenue. A poor developer experience leads to:
- Increased Time-to-Market: The friction between writing code and seeing it live in production can stretch from minutes to days.
- Shadow IT: Frustrated developers may bypass official channels to use simpler, unmanaged tools, creating massive security and consistency risks for the organization.
- Attrition: Top-tier engineering talent gravitates toward environments where they can be productive. If your platform is a source of constant frustration, you will struggle to retain the people needed to scale the business.

What Does Kubernetes Platform Engineering Mean?
Platform engineering represents a fundamental shift in how organizations manage the lifecycle of containerized applications within the Kubernetes ecosystem. It moves away from the traditional ticket-based model toward a self-service paradigm, providing the bridge between expensive technical debt and a scalable, automated business asset.
By building a curated layer that abstracts the complexity of raw clusters, organizations can maintain enterprise-grade control while industrializing the delivery process, ensuring that scaling does not require a linear increase in headcount.
From Management to Platforms
The evolution of Kubernetes usage often follows a predictable path. Initially, teams focus on managing raw infrastructure by manually configuring nodes, networks, and storage. However, as the organization grows, this manual approach becomes the primary bottleneck. Transitioning to an internal platform means shifting the focus from the technicalities of infrastructure to the acceleration of developer productivity.
- Platforms as internal products: Successful platform engineering requires a product management mindset. The platform is not just a collection of tools; it is a product whose customers are the company’s own developers. This means gathering requirements, defining SLAs, and continuously iterating based on user feedback to ensure the infrastructure meets actual application needs.
- Standardized K8s workflows: A mature platform defines clear, repeatable paths for deployment and recovery. Instead of every team having its own unique configuration, the platform provides golden paths. These are pre-approved, automated workflows that ensure every new service follows best practices by default.
- Scalable cloud foundations: A true platform is cloud-agnostic and resilient. It provides the foundation for multi-region strategies without requiring developers to understand the nuances of different cloud providers. This abstraction layer protects the business from vendor lock-in and allows the organization to move workloads based on cost and performance.
Evolving DevOps Operations
The implementation of a platform does not eliminate DevOps; it evolves it. It moves the discipline from a helper role to a strategic role, fundamentally changing the unit economics of engineering. This shift allows DevOps teams to focus more on automation, scalability, and long-term platform innovation rather than repetitive operational tasks.
| Traditional DevOps | Platform-Led Operations |
| Manual Provisioning: DevOps handles infrastructure requests via tickets. | Self-Service: Developers provision resources via an automated portal. |
| Configuration Drift: Environments become inconsistent over time. | Immutability: Automation ensures production matches staging exactly. |
| Linear Scaling: More developers require more DevOps headcount. | Exponential Scaling: A lean platform team supports hundreds of developers. |
Strategic Insight: By empowering developers with self-service tools, the constant back-and-forth between teams vanishes. DevOps is no longer a bottleneck; it is an enabler. This allows application teams to own their entire lifecycle from code to production.
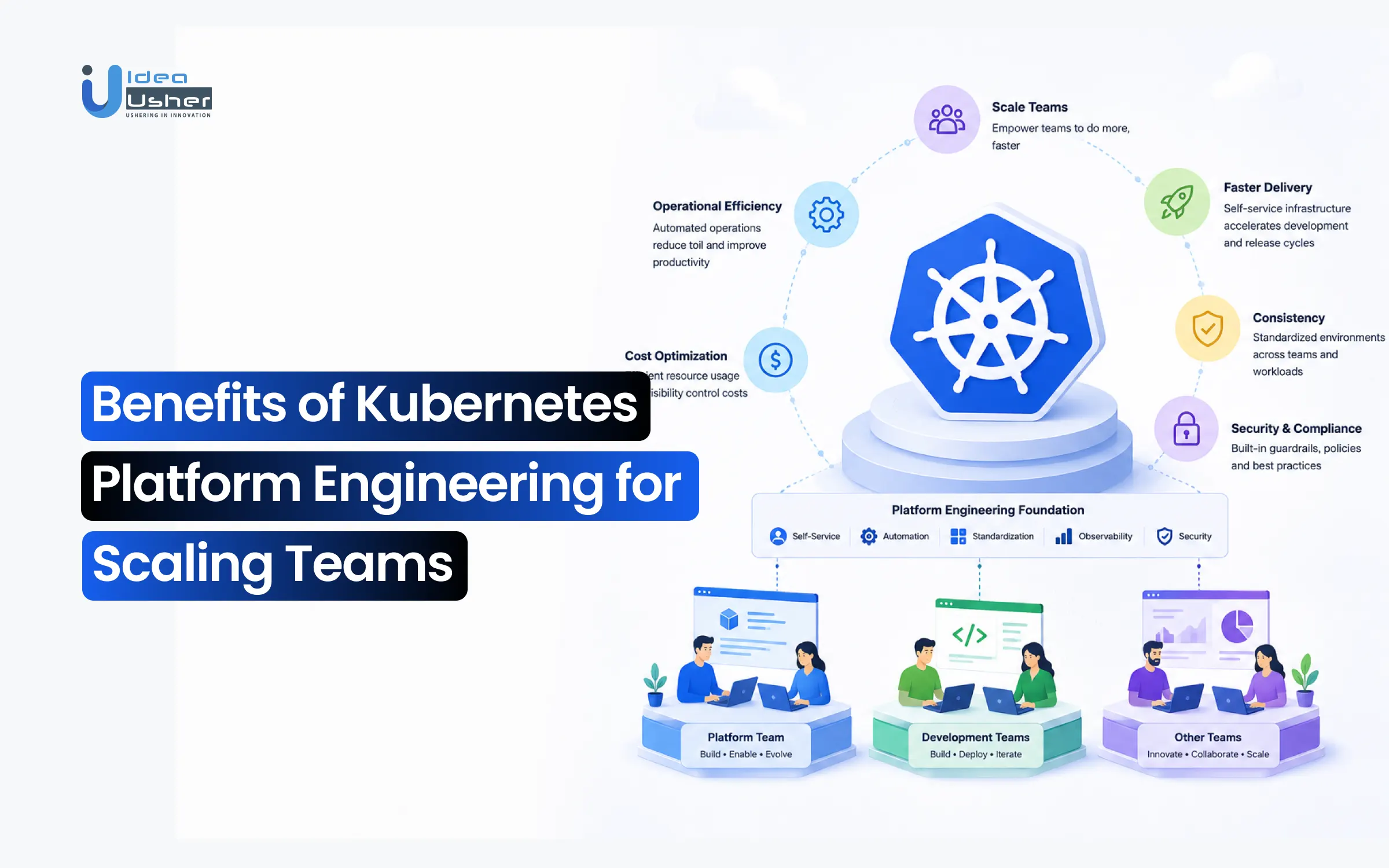
Key Benefits of Kubernetes Platform Engineering
Adopting platform engineering is a strategic move to de-risk your infrastructure. By shifting from manual cluster management to a unified platform, organizations transform Kubernetes from a complex burden into a competitive advantage. This shift maximizes engineering output while minimizing the operational overhead that typically scales alongside cloud growth.
1. Faster Onboarding
In traditional setups, new developers spend days gaining access and setting up environments. Platform engineering eliminates this friction by providing pre-configured environments ready for use. Automated onboarding workflows ensure developers can start building and testing applications almost immediately. This faster ramp-up time improves productivity and helps engineering teams scale more efficiently.
- Standardized environments: Using golden paths ensures every developer starts with a consistent set of tools. This allows new hires to contribute to the codebase within hours.
- Reducing setup complexity: The platform abstracts Kubernetes technicalities. Developers do not need to be cluster experts to deploy a service. They follow guided workflows that handle orchestration and networking automatically.
2. Standardized Workflows
Fragmented deployment processes are a primary cause of outages. Platform engineering enforces consistency by mandating unified CI/CD pipelines for every team. Standardized automation reduces human error and ensures deployments follow the same validation and release practices across environments. This consistency improves application stability while making troubleshooting and rollback processes significantly faster.
The Workflow Impact:
- Uniformity: Every microservice follows the same testing rigors for higher quality.
- Auditability: Every change is version-controlled for compliance and troubleshooting.
- Eliminating drift: Automation ensures staging mirrors production exactly. This prevents failures caused by subtle, manual environment changes over time.
3. Self-Service Operations
The biggest bottleneck in engineering is the request cycle between developers and DevOps. Platform engineering breaks this by offering self-service capabilities. Developers gain the ability to provision and manage resources independently without waiting for manual approvals or infrastructure tickets. This reduces deployment delays and allows engineering teams to move faster with greater operational flexibility.
Operational Freedom: When developers provision their own namespaces and databases through a validated portal, the DevOps team is freed from ticket management. This autonomy leads to faster deployment and rollback workflows. Teams can experiment and recover in minutes without waiting for external approval.
3. Stronger Security
Security cannot be an afterthought in containerized environments. A mature platform embeds DevSecOps into the foundation rather than treating it as a final gate. By integrating security controls directly into development and deployment workflows, organizations can identify risks earlier in the lifecycle. This approach strengthens compliance while reducing the chances of vulnerabilities reaching production environments.
- Embedded practices: Vulnerability scanning happens automatically during the build process.
- Automated enforcement: Using policy as code, the platform blocks non-compliant deployments in real time. It can prevent containers from running as root or ensure all traffic is encrypted, maintaining continuous compliance without manual audits.
4. Cost Optimization
Cloud waste erodes ROI. Kubernetes often leads to over-provisioning when developers overestimate resource needs. Without proper visibility, unused compute and storage resources continue accumulating unnoticed across clusters. Over time, this inefficiency increases operational costs and reduces the overall financial value of cloud adoption.
| Optimization Strategy | How it Works | Financial Result |
| Smarter Scheduling | Packing pods efficiently onto nodes. | Lower monthly cloud bills. |
| Horizontal Scaling | Scaling based on real-time demand. | Only pay for peak usage when needed. |
| Right-Sizing | Trimming resource requests based on usage. | Prevents paying for idle capacity. |
Improved resource utilization ensures every dollar spent on compute power drives application performance instead of maintaining empty capacity.
5. Better Reliability
You cannot manage what you cannot see. Platform engineering provides unified monitoring and logging for a clear view of the entire ecosystem. When an incident occurs, the platform provides deep context through distributed tracing and centralized logs. This reduces the time to recovery by allowing engineers to pinpoint failures across microservices instantly. Troubleshooting becomes a data-driven process that preserves uptime and user trust.
6. Multi-Cloud Management
The future is often multi-cloud, but managing diverse environments separately is an operational struggle. A platform engineering layer acts as a centralized hub across all providers. This approach simplifies governance by allowing you to set a single policy for all clusters regardless of their location. This abstraction provides the flexibility to move workloads based on pricing or regional availability without retraining staff, protecting the business from vendor lock-in.
Why Traditional DevOps Models Fail at Scale?
The transition from a small operation to a sprawling enterprise environment often exposes the inherent limitations of traditional DevOps, particularly within the Kubernetes ecosystem. While the initial philosophy emphasized collaboration, the lack of a structured platform layer often results in a fragmented architecture.
As the number of services and clusters grows, the manual intervention required to keep the system stable begins to outweigh the benefits of the technology, turning the infrastructure into a liability rather than an asset.
1. Scaling Manual Infrastructure
In many traditional setups, infrastructure management is still heavily reliant on human intervention. Whether it is manually tweaking cluster settings or following a checklist for each new environment, these actions create a scaling ceiling that no amount of hiring can solve. As infrastructure complexity increases, manual processes also increase the likelihood of configuration errors and operational delays.
- Expensive Management: Every new cluster or region adds a linear increase in maintenance tasks. Without automation, senior engineers become expensive administrators, spending their time on routine configuration instead of architectural growth.
- Efficiency Losses: Repetitive workflows are the enemy of speed. When developers have to wait for manual approvals or resource provisioning, the momentum of the product cycle stalls. This inefficiency creates a hidden cost that reduces the overall competitiveness of the business.
2. Operational Tool Sprawl
As teams grow, they often adopt different tools for similar tasks. One team might prefer a specific monitoring solution while another uses a different CI/CD pipeline. Without a centralized platform engineering strategy, this leads to a Frankenstein architecture that is impossible to manage holistically.
The Chaos Tax: Managing a disconnected web of CI/CD, monitoring, and security systems requires specialized knowledge for each tool. This fragmentation prevents unified operational visibility, making it nearly impossible for leadership to get a clear picture of system health, security posture, or resource spend across the entire organization.
The result is a culture of silos where data is trapped in separate systems. When a security vulnerability is identified, patching it across dozens of disparate tools and environments becomes an exercise in frustration and risk, often leaving critical gaps in the enterprise defense.
3. Inconsistent Reliability
Consistency is the foundation of reliability. In traditional DevOps models, the lack of standardized environments leads to a phenomenon known as environmental drift, where production, staging, and development environments gradually diverge in their configurations. Over time, these inconsistencies make deployments less predictable and significantly increase troubleshooting complexity.
- Deployment Instability: When environments are not identical, a feature that passes tests in staging can easily crash in production. This instability leads to a cycle of failed deployments and emergency patches, eroding user confidence and team morale.
- Drift and Downtime: Minor manual changes, often called hotfixes, made directly to a live cluster create a situation where the actual state of the system is unknown. When the system eventually fails, recovery time is significantly longer because the team must first figure out what the actual configuration was before they can begin the repair.
Technologies Behind Kubernetes Platform Engineering
The shift toward platform engineering is fueled by a specialized stack designed to automate the lifecycle of containerized workloads within the Kubernetes ecosystem. At IdeaUsher, we view these technologies not just as tools, but as the fundamental drivers of cloud unit economics. By replacing manual intervention with programmable, self-healing systems, we help you build high-performance platforms that scale without collapsing under their own weight.

Our pre-vetted developers specialize in integrating these architectural pillars to ensure your infrastructure remains a high-value business asset.
1. GitOps for Scalable Operations
We implement GitOps as the definitive operating model for Kubernetes, treating infrastructure as code and using Git repositories as the single source of truth for your entire system. This approach improves deployment consistency by ensuring every infrastructure change is version-controlled and automatically traceable.
- Declarative infrastructure management: Unlike imperative commands, where you tell the system what to do step-by-step, we build declarative systems. You define the end state, and the platform ensures the environment matches that definition automatically.
- Git-driven deployment consistency: We ensure every change is initiated via a pull request, providing a built-in audit trail. This allows for rapid rollbacks where returning to a stable state is as simple as reverting a commit, significantly de-risking your deployment cycles.
2. Internal Developer Platforms
An Internal Developer Platform acts as the primary interface between complex backend clusters and your application developers. We focus on the productization of infrastructure to accelerate your roadmap. By simplifying access to infrastructure services, developers can deploy and manage applications with far less operational overhead.
The Developer Experience Shift: By abstracting complexity, the IDPs we build allow your developers to focus entirely on business logic. Instead of managing ingress controllers, they use self-service portals to deploy services. This autonomy removes the DevOps bottleneck and increases the frequency of successful releases.
Our team standardizes these self-service experiences, ensuring that every project follows your security and operational guardrails by default.
3. Service Mesh for Traffic and Security
As your microservice architectures grow, managing communication between hundreds of services becomes a primary challenge. We utilize Service Mesh to provide a dedicated infrastructure layer that handles this without changing your application code. This enables secure, observable, and controlled service-to-service communication across complex distributed environments.
| Feature | Technical Function | Business Value |
| Mutual TLS (mTLS) | Encrypts service-to-service data. | Zero-trust security by default. |
| Traffic Splitting | Canary and Blue/Green updates. | Zero-downtime updates and safer testing. |
| L7 Observability | Deep metrics on every request. | Instant identification of latency. |
We implement these layers to ensure secure communication and advanced routing, protecting your user experience during major system updates.
4. AI-Driven Automation
The scale of modern environments has surpassed the capacity for human-only monitoring. We integrate AI-driven automation to maintain efficiency and uptime at the enterprise level. AI-powered systems continuously analyze infrastructure behavior, resource usage, and performance trends in real time. This allows organizations to respond faster to operational issues while improving scalability and resource efficiency.
Intelligent workload optimization
Our developers deploy AI agents that analyze historical resource usage to identify waste. By automatically adjusting pod limits and node sizes, we ensure your platform remains performant without the common pitfall of over-provisioning. This continuous optimization helps reduce unnecessary cloud spending while maintaining stable application performance.
Predictive scaling and anomaly detection
We move beyond reactive scaling by implementing AI models that prepare your infrastructure ahead of anticipated demand. Furthermore, we use anomaly detection to identify subtle performance deviations, allowing for preemptive intervention before a minor glitch becomes a major outage. When you hire from our pool of specialized talent, you gain the expertise needed to turn these advanced technologies into reliable, scalable operations.
How Companies Scale Faster With Kubernetes Platform Engineering?
Success in the modern digital economy is measured by the speed of the feedback loop between an idea and its deployment. We recognize that for high-growth companies operating within the Kubernetes ecosystem, the technical debt of a poorly managed cluster is the single greatest threat to velocity. By implementing a dedicated platform engineering layer, we enable organizations to decouple their growth from technical complexity.

This transition allows businesses to scale their infrastructure and their headcount simultaneously without the traditional friction that slows down market entry.
1. SaaS Developer Operations
For SaaS providers, the ability to maintain global consistency while shipping features daily is a critical requirement. We help SaaS teams move away from bespoke, team-specific configurations toward a unified operational standard that spans the entire organization. This centralized approach improves deployment reliability while simplifying infrastructure management across distributed engineering teams.
- Faster feature delivery: By providing pre-validated deployment templates, we allow your developers to focus on shipping code rather than debugging environment issues. This reduces the time to market for new features, ensuring you stay ahead of the competition.
- Workflows at scale: We implement standardized pipelines that ensure every update, regardless of which team it comes from, meets the same high bar for security and performance. This uniformity is what allows a SaaS platform to support millions of users across different regions with minimal downtime.
2. AI Infrastructure Automation
The rise of generative AI and machine learning has placed unprecedented demands on infrastructure. AI-driven businesses require more than just standard compute. They require specialized orchestration of high-cost resources. Without intelligent workload management, infrastructure costs and performance bottlenecks can quickly scale alongside model complexity.
The GPU Challenge: Managing GPU clusters for AI training and inference is notoriously complex. We provide the expertise to automate GPU orchestration, ensuring that these expensive resources are utilized efficiently. Our platform strategies include dynamic resource allocation, which prevents idle GPU time and significantly reduces the burn rate of AI-native startups.
Through scalable AI infrastructure management, we enable your data scientists to deploy models into production environments that automatically scale based on inference demand. This level of automation is essential for maintaining performance while keeping operational costs under control.
3. Modernizing Legacy Systems
For established enterprises, the challenge is often bridging the gap between stable legacy systems and the agility of the cloud. We specialize in creating the bridge that allows for a smooth transition without disrupting core business operations. This modernization approach helps organizations adopt cloud-native capabilities while preserving the stability of mission-critical systems.
| Modernization Goal | Strategy | Outcome |
| Monolith Migration | Refactoring legacy apps into microservices. | Improved fault tolerance and modularity. |
| Cloud-Native Adoption | Containerizing workloads for Kubernetes. | Portability across any infrastructure. |
| Multi-Cloud Strategy | Standardized control planes across vendors. | Eliminated vendor lock-in and optimized costs. |
Common Kubernetes Platform Engineering Mistakes
Even with the best intentions, many organizations stumble when building their orchestration layers within the Kubernetes ecosystem. We have observed that technical excellence alone does not guarantee a successful platform. The most frequent failures stem from a misalignment between infrastructure goals and the actual needs of the engineering teams they serve.
Avoiding these pitfalls is essential for maintaining capital efficiency and ensuring the platform remains a scalable asset rather than a technical liability.
1. Overengineering Platforms
A common trap for growing teams is the desire to build a perfect, feature-complete platform before any developer has even used it. This premature complexity often leads to a system that is too rigid or too difficult to navigate. As a result, platform adoption slows down because developers struggle with unnecessary operational complexity from the start.
- Complexity creep: Building unnecessary features, such as hyper-granular resource controls or bespoke networking protocols, too early can overwhelm developers. This results in a platform that requires extensive training just to perform basic tasks.
- Poor usability: If the platform is harder to use than the raw Kubernetes API, developers will simply bypass it. We focus on building iterative, lean platforms that solve immediate pain points first, ensuring that usability drives adoption rather than mandates.
2. Ignoring Developer Experience
The primary customer of your platform is your developer. If the interface is clunky or the documentation is lacking, the platform becomes a source of frustration rather than a tool for acceleration. Poor developer experience often leads teams to bypass platform standards entirely, creating further operational inconsistency.
The Friction Cost: When platforms ignore developer experience, the result is operational friction. Developers spend their time fighting the tool rather than shipping code. We prioritize intuitive workflows that allow for one-click deployments and clear error messaging, ensuring that the platform genuinely removes cognitive load.
3. Security as an Afterthought
In the rush to achieve high velocity, security is often pushed to the end of the development cycle. This reactive model is dangerous in a containerized environment where vulnerabilities can propagate rapidly. Without proactive security controls, a single misconfiguration can quickly impact multiple services across the infrastructure.
| Security Mistake | Impact | Strategic Fix |
| Reactive Patching | High risk of zero-day exploits. | Automated vulnerability scanning. |
| Manual Compliance | Gaps across diverse environments. | Policy-as-Code enforcement. |
| Broad Permissions | Potential for lateral movement. | Strict RBAC and zero-trust mesh. |
By building security into the foundation, we help you avoid compliance gaps that often haunt large-scale deployments. We ensure that every workload is secure by default, so you do not have to choose between speed and safety.
4. Lack of Platform Ownership
Without clear boundaries between what the platform team manages and what the application teams are responsible for, operational confusion is inevitable. In large organizations, this lack of ownership leads to significant governance challenges. When a cluster fails or a deployment hangs, teams may waste hours arguing over whose responsibility it is to fix the issue. We advocate for a clear shared responsibility model.
The platform team owns the reliability and security of the infrastructure, while application teams own the performance and health of their services. This clarity eliminates the blame game and ensures that incident response is fast and effective. By hiring our pre-vetted specialists, you gain the expertise to define these roles early, preventing the organizational silos that stall growth.
Why Businesses Need Expert Platform Partners like Idea Usher?
Building a resilient infrastructure is a high-stakes endeavor that requires more than just raw compute power. At IdeaUsher, we understand that a poorly architected platform becomes a bottleneck that drains capital and stalls innovation. By partnering with us, you bypass the steep learning curve and operational risks associated with building an enterprise-grade Kubernetes ecosystem from scratch.

We provide the specialized talent and battle-tested frameworks needed to transform your infrastructure into a lean, automated engine for growth.
1. Expertise for Complex Systems
Production-grade Kubernetes is notoriously difficult to manage at scale. While many teams can spin up a basic cluster, maintaining high availability, networking, and storage across global regions requires a level of seniority that is difficult to find and expensive to retain. As infrastructure grows, the operational complexity of managing these distributed environments increases significantly..
- Ecosystem Complexity: Modern platforms involve a web of integrated tools for container orchestration, service mesh, and secret management. We handle this complexity so your core team can remain focused on your product roadmap.
- Overcoming Scalability Struggles: Internal teams often get bogged down in day-to-day maintenance, leading to platform stagnation. We bring the outside perspective and deep technical bench needed to ensure your platform evolves ahead of your business requirements, preventing the technical debt that cripples scaling startups.
2. Faster, Proven Architectures
Starting from zero often leads to expensive trial and error. We accelerate your cloud-native journey by deploying proven architectures that have already been validated in high-demand environments. This reduces deployment uncertainty while helping organizations adopt scalable infrastructure patterns much faster.
Risk Mitigation: Instead of experimenting with your production environment, we use established frameworks that reduce implementation risk. This approach ensures that your move to the cloud is not just fast, but stable and secure from day one.
By leveraging our pre-vetted developers, you gain access to blueprints for high-performance scaling. This accelerates adoption across your organization, allowing you to move from legacy systems to modern, containerized workflows in a fraction of the time it would take to build internally.
3. End-to-End DevSecOps Support
Fragmented operations are the primary cause of security gaps and system outages. We help you avoid the trap of disconnected tools by building a unified automation and governance layer. This centralized operational model improves visibility, strengthens policy enforcement, and reduces inconsistencies across environments.
| Focus Area | Our Approach | Business Outcome |
| Unified Automation | Centralized CI/CD and GitOps workflows. | Rapid, repeatable, and error-free releases. |
| Governance | Programmatic policy enforcement and RBAC. | Constant compliance without manual checks. |
| Observability | Full-stack logging and predictive monitoring. | Reduced downtime and faster incident response. |
Idea Usher’s DevSecOps Strategy for Kubernetes Platforms
Security in a Kubernetes environment cannot be a final inspection step. We treat security as a foundational element that is woven into every layer of the platform. At IdeaUsher, our strategy centers on shifting security to the left, ensuring that protection is automated, continuous, and invisible to the developer. By hiring our pre-vetted experts, you ensure that your scaling efforts are protected by enterprise-grade guardrails from the very first line of code.

1. Embedded Security Workflows
We integrate security scanning directly into the CI/CD pipeline to catch vulnerabilities before they ever reach a cluster. This proactive approach prevents the deployment of compromised images and ensures that every container meets your organization’s safety standards. By identifying risks earlier in the development lifecycle, teams can resolve security issues before they impact production environments.
- Automated Image Scanning: We verify container images for known CVEs during the build phase.
- Manifest Validation: Our systems check configuration files for insecure settings like running containers as root or missing resource limits.
- Signature Verification: We ensure only trusted, signed images run in production, preventing supply chain attacks.
2. Continuous Compliance
Compliance is not a one-time event; it is a constant state. We build platforms that continuously monitor cluster configurations against industry standards like CIS Benchmarks or SOC2 requirements. This continuous validation helps organizations detect configuration drift early and maintain consistent governance across environments.
Automated Governance: Our platform architecture uses policy as code to enforce rules in real time. If a configuration drifts from a compliant state, the platform can automatically trigger remediation or block the change. This provides a constant audit trail, making regulatory reviews a seamless part of your operations.
3. Secrets and Access Control
Managing sensitive data like API keys and certificates is a primary challenge in distributed systems. We implement centralized secrets management to ensure that credentials are never stored in plain text or hardcoded in repositories. This approach reduces the risk of credential exposure while improving security governance across Kubernetes environments.
| Control Mechanism | Implementation | Benefit |
| RBAC | Role-Based Access Control. | Grants the least privilege to users and services. |
| Vault Integration | Dynamic secrets injection. | Rotates credentials automatically to limit exposure. |
| Identity Federation | Linking K8s to enterprise IAM. | Centralizes user management and simplifies offboarding. |
4. Runtime Threat Detection
Protection does not stop once a service is live. We implement runtime security tools that monitor active workloads for suspicious behavior. By analyzing system calls and network traffic, we can identify anomalies that indicate a potential breach. If a container starts making unauthorized network connections or attempts to modify sensitive system files, our automated response systems can instantly isolate the affected pod.
This level of detection ensures that even if a vulnerability is exploited, the impact is contained. By partnering with IdeaUsher, you gain a platform that is not just built for speed but hardened for the realities of modern cyber threats.
How Idea Usher Scales Multi-Cloud Kubernetes?
A mature cloud strategy often requires spreading workloads across multiple providers to optimize costs and ensure high availability. At IdeaUsher, we specialize in removing the complexity of multi-cloud environments. We build a unified control plane that allows you to manage Kubernetes clusters on AWS, Azure, and GCP as a single, cohesive ecosystem. By hiring our pre-vetted developers, you gain the ability to move workloads seamlessly across clouds, protecting your business from vendor lock-in and regional outages.
1. Unified Operations
Managing different cloud providers usually requires specialized knowledge for each console and API. We eliminate this overhead by standardizing operations through a single interface. This unified management model reduces operational complexity and improves consistency across distributed Kubernetes environments.
- Consistent Tooling: We use cross-cloud technologies like Terraform and Crossplane to ensure your infrastructure is defined once and deployed anywhere.
- Centralized Governance: We apply a single set of security and compliance policies across all providers, ensuring that an Azure cluster is just as secure as an AWS cluster.
- Global Capacity Management: Our approach allows you to scale resources in the region or cloud that offers the best price-to-performance ratio at any given moment.
2. Networking and Traffic
Connecting services across different clouds is one of the most difficult technical hurdles in platform engineering. We implement advanced networking layers to make cross-cloud communication secure and performant. We utilize Global Server Load Balancing and service mesh technology to route traffic based on proximity, latency, or health.
If a provider in one region experiences a spike in latency, our systems automatically reroute user traffic to the next best available cluster, maintaining a seamless experience for your customers.
3. Centralized Monitoring
Visibility is often the first casualty of a multi-cloud strategy. We solve this by building a unified observability stack that aggregates data from every cluster into a single pane of glass. This centralized monitoring approach gives operations teams consistent insight into infrastructure health, workload performance, and resource utilization across environments.
| Data Type | Our Solution | Business Impact |
| Logs | Aggregated into a central, searchable warehouse. | Audit-ready data for all cloud activities. |
| Metrics | Real-time performance dashboards. | Instant identification of cost or performance spikes. |
| Traces | End-to-end distributed tracing. | Debugging complex cross-cloud transactions. |
This centralized view ensures that your operations team is not jumping between different cloud-native monitoring tools. Instead, they have the deep context needed to troubleshoot issues across your entire distributed infrastructure from one location.
4. Hybrid Architecture Optimization
For enterprises with on-premise requirements, we optimize hybrid architectures that bridge the gap between private data centers and the public cloud. This allows organizations to modernize infrastructure gradually without disrupting existing operational dependencies. It also provides greater flexibility in balancing compliance, performance, and scalability requirements across environments.
The Hybrid Advantage: We help you keep sensitive data on-premise for sovereignty while bursting compute-heavy tasks into the cloud. This optimization ensures you are not overpaying for local hardware while still benefiting from the infinite scale of the public cloud.
Why Choose Idea Usher for Kubernetes Platform Engineering?
Building a production-ready Kubernetes platform is a high-stakes investment. With over 500,000 hours of coding experience, our team of ex-MAANG/FAANG developers provides a strategic partnership that transforms your infrastructure into a competitive asset. At IdeaUsher, we do not just provide developers. By integrating specialized talent with battle-tested automation, we help you avoid the common pitfalls of cloud-native transitions.
Our approach ensures that your engineering team spends less time fighting tools and more time shipping features that drive revenue.
Expertise in Cloud-Native Systems
Managing a raw cluster is vastly different from running a production-grade ecosystem. Our team brings deep seniority across the entire cloud-native landscape, from low-level networking to high-level orchestration. This expertise helps organizations build Kubernetes environments that remain stable, secure, and scalable under growing operational demands.
- Deep Technical Bench: We specialize in the complex CNCF landscape. This ensures your stack is modern, supported, and secure.
- DevOps Culture: We do not just perform DevOps tasks. We implement the cultural and technical shifts required to make it work, including establishing CI/CD best practices that actually scale.
- Architectural Guidance: We help you choose between managed services like EKS or GKE versus self-managed solutions based on your specific cost and compliance needs.
Scalable Internal Platforms
A successful platform must be a product that developers actually enjoy using. We focus on creating Internal Developer Platforms that prioritize usability and self-service. By simplifying infrastructure interactions, developers can deploy and manage applications with greater speed and confidence. This improved experience increases platform adoption while reducing operational friction across engineering teams.
The IdeaUsher Difference: Instead of building a rigid system, we develop iterative platforms. We start with your most significant bottlenecks, such as slow environment provisioning, and build automated solutions that provide immediate ROI. This product-centric mindset ensures high internal adoption and a drastic reduction in developer frustration.
Security and Compliance
For many organizations, the move to Kubernetes creates new security anxieties. We mitigate these risks by embedding enterprise-grade security and compliance directly into the platform DNA. Security controls, governance policies, and compliance checks are integrated directly into operational workflows rather than added later as manual processes.
| Strategic Focus | Our Implementation | Business Protection |
| Zero-Trust Security | Mutual TLS via Service Mesh. | Protects sensitive data from lateral movement. |
| Automated Compliance | Policy as Code using OPA or Kyverno. | Ensures continuous SOC2 and HIPAA readiness. |
| Identity Management | Unified RBAC and IAM integration. | Prevents unauthorized access across all clusters. |
We ensure that security is not a separate step that slows you down. By automating guardrails, we allow your teams to move fast without breaking your compliance posture.
Faster Adoption and Reduced Risk
Moving to a cloud-native model often carries the risk of service disruptions or spiraling cloud costs. We act as your safety net by providing proven architectures that have been validated in high-demand environments. When you hire from our pool of pre-vetted specialists, you are not just filling a seat. You are importing years of specialized experience.
This expertise allows your organization to accelerate its transition to Kubernetes by months, bypassing the expensive trial-and-error phase. We provide the end-to-end support from initial audit to long-term optimization that ensures your platform remains reliable, cost-effective, and ready for whatever your business needs next.
Conclusion
Implementing platform engineering within the Kubernetes ecosystem allows scaling teams to transition from manual operations to a streamlined delivery model. By consolidating complex infrastructure into a unified platform, businesses can eliminate developer bottlenecks, enforce enterprise-grade security by default, and maintain high availability across environments. Ultimately, this approach empowers your engineering talent to focus on product innovation rather than cluster maintenance, ensuring that your technical foundation remains a catalyst for rapid, sustainable growth.
FAQs
Q1: How does Kubernetes platform engineering improve developer velocity?
A1: By providing a self-service layer, platform engineering removes the need for developers to manage the underlying infrastructure. We build automated workflows that allow teams to deploy applications into Kubernetes clusters without waiting for manual approvals or configuration changes. This shift reduces the cognitive load on engineering teams, allowing them to focus entirely on writing and shipping code.
Q2: Can platform engineering reduce the costs of running Kubernetes?
A2: Yes, a well-engineered platform uses intelligent automation to optimize resource allocation across your clusters. We implement tools that monitor workload patterns and adjust pod limits or node sizes to prevent over-provisioning. By right-sizing your Kubernetes environment and automating the shutdown of unused resources, we help significantly reduce monthly cloud spend without sacrificing performance.
Q3: How is security managed in a Kubernetes platform engineering model?
A3: Security is integrated directly into the platform through a DevSecOps approach, ensuring that every deployment is checked for vulnerabilities automatically. We use policy-as-code to enforce security guardrails across all Kubernetes workloads, which prevents insecure configurations from reaching production. This ensures consistent protection and compliance without requiring developers to be security experts.
Q4: Why is an Internal Developer Platform better than raw Kubernetes?
A4l Raw Kubernetes is highly complex and requires specialized knowledge that many application developers do not have. An Internal Developer Platform abstracts this complexity into simple interfaces, giving developers the power of container orchestration without the steep learning curve. We design these platforms to provide a standard, reliable experience that scales seamlessly as your team and infrastructure grow.






