




Key Takeaways
- Standardizing Kubernetes improves deployment consistency, reduces configuration drift, and simplifies infrastructure governance for engineering organizations.
- Fragmented workflows, inconsistent security policies, and multi-cloud operations increase operational complexity, cloud costs, and deployment failures.
- Using platform engineering, GitOps, automation, and reusable templates helps businesses create scalable, secure Kubernetes environments.
- Centralized governance, policy-as-code, and shared observability improve security, accelerate onboarding, and support Kubernetes scalability.
- How Idea Usher helps businesses standardize Kubernetes across teams with pre-vetted developers, automated workflows, and scalable infrastructure strategies.
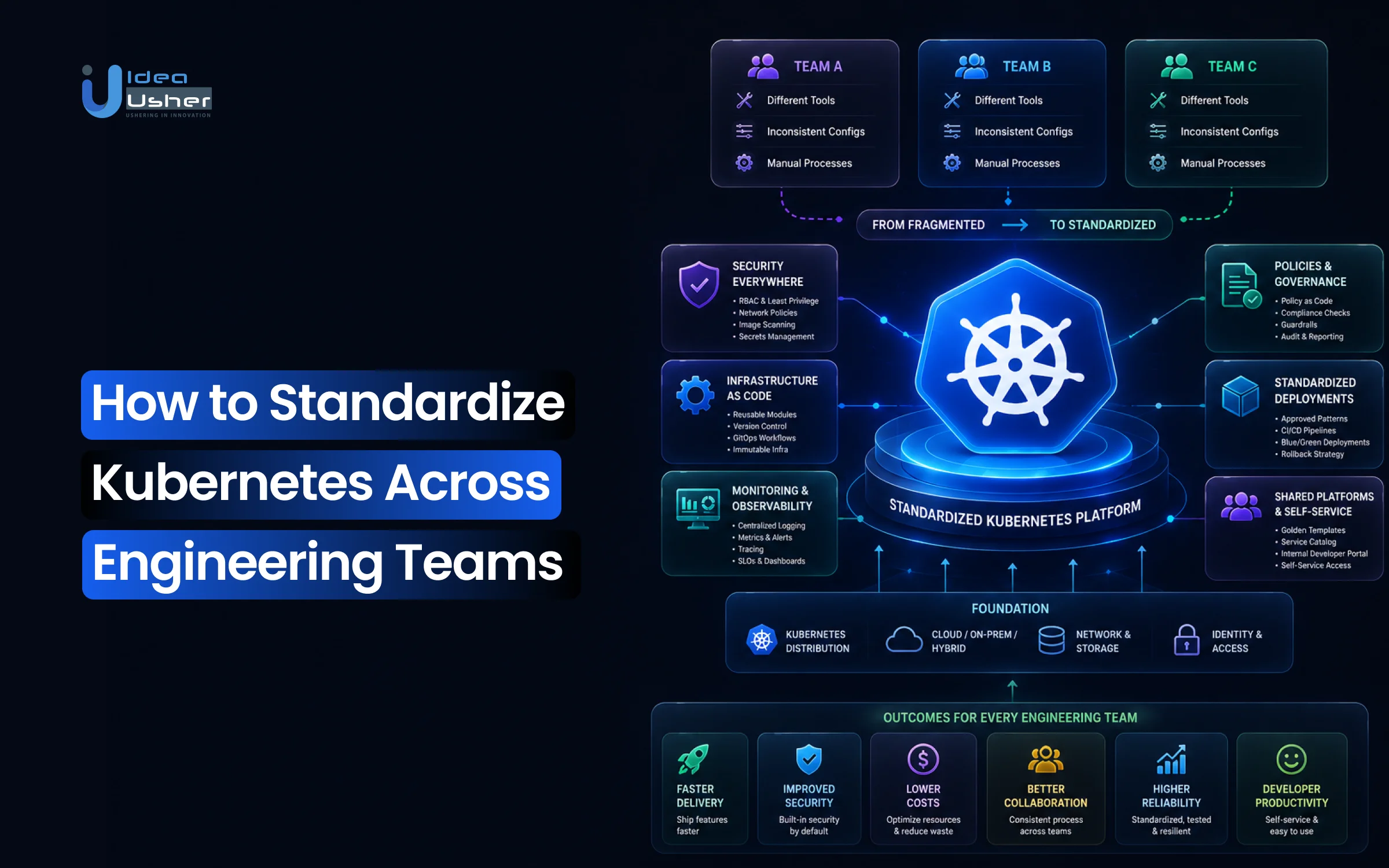
Why do Kubernetes environments become harder to manage even after teams adopt the same platform? The problem is not Kubernetes itself. It is the lack of operational consistency across engineering teams. One team builds custom deployment workflows, another defines its own security policies, while platform teams struggle to enforce standards across growing infrastructure.
This model worked when Kubernetes adoption was limited to smaller engineering setups. But modern businesses now run multi-cloud workloads, AI infrastructure, and distributed applications on Kubernetes at scale. Inconsistent configurations now directly impact release cycles, security posture, onboarding speed, and cloud costs.
We’ve helped businesses standardize Kubernetes across engineering teams by reducing configuration drift, improving deployment consistency, and simplifying platform governance. In this blog, we’ll break down practical strategies for building scalable Kubernetes environments that enable faster development, better collaboration, and more reliable operations.
Why Kubernetes Standardization Has Become Essential?
According to Mordor Intelligence, the Kubernetes market size is expected to grow from USD 2.57 billion in 2025 to USD 3.13 billion in 2026 and is forecast to reach USD 8.41 billion by 2031 at a 21.85% CAGR over 2026-2031. This aggressive capital infusion underscores a fundamental shift in how global enterprises manage infrastructure. However, for investors and founders, this growth presents a paradox. While the underlying technology is becoming the industry standard, the lack of uniformity in its deployment often creates a technical debt trap that can erode the ROI of cloud-native initiatives.

Source: Mordor Intelligence
Standardization is no longer a luxury reserved for tech giants. It is a prerequisite for financial predictability and operational security. When an organization scales, the cost of managing idiosyncratic, snowflake clusters begins to outweigh the benefits of the technology itself. Without a standardized approach, your capital is frequently diverted away from product innovation and toward the perpetual maintenance of fragmented infrastructure.
The Problem of Fragmented Engineering
One of the most significant risks to a scalable platform is architectural drift. Because Kubernetes is a highly modular framework rather than a prescriptive product, it offers a thousand different ways to solve the same problem. Left to their own devices, individual engineering teams will inevitably choose different ingress controllers, different CI/CD patterns, and different observability stacks.
- Fragmentation of Tooling: One team might favor Istio for service mesh, while another prefers Linkerd. One might use Helm for templating, while another leans into Kustomize.
- Knowledge Silos: This diversity creates tribal knowledge where only specific engineers understand the plumbing of specific services. If a key engineer departs, the lack of documentation and standardized patterns becomes a liability.
- Security Inconsistency: When every team manages its own configuration, applying global security patches or compliance protocols becomes an exercise in manual, error-prone auditing across dozens of unique environments.
From an investment perspective, this lack of uniformity translates to high Mean Time to Recovery (MTTR) and inefficient resource allocation. You are not just paying for infrastructure. You are paying for the cognitive overhead required for your team to switch between conflicting systems.
The Hidden Costs of Growing Complexity
The initial appeal of Kubernetes is its ability to automate container orchestration, but as the footprint expands, the complexity curve becomes exponential. What starts as simple cluster management quickly evolves into a multifaceted challenge involving networking, storage, and multi-cloud interoperability. This creates a bottleneck where senior engineers, your most strategic assets, find themselves bogged down in low-value debugging and upgrades rather than shipping revenue-driving features.
Strategic investors must recognize that Kubernetes is not a set it and forget it utility. It is a living ecosystem that requires constant maintenance to prevent the infrastructure from collapsing under its own weight. When complexity grows unchecked, the resulting operational burden leads to shadow IT and bypassed procedures, which ultimately compromise the integrity, security, and scalability of the entire platform.
The Shift to Platform Engineering
The industry is currently witnessing a strategic pivot from DevOps as a job title to Platform Engineering as a product. High-growth enterprises are no longer asking their developers to be Kubernetes experts. Instead, they are investing in the creation of Internal Developer Platforms that abstract away the underlying complexity of the cloud-native stack.
The logic behind this shift is purely economic:
- Developer Velocity: By providing a Golden Path, which is a pre-configured, standardized set of tools and workflows, developers can deploy code without needing to understand the intricacies of Kubernetes manifests.
- Operational Governance: Platform engineering allows leadership to bake security, cost controls, and compliance directly into the infrastructure. This ensures that every new service automatically adheres to enterprise standards.
- Scalability of Talent: It is far easier to hire developers who can build on a well-architected platform than it is to find specialists who are experts in both application logic and deep-level Kubernetes orchestration.

The Biggest Challenges in Kubernetes Standardization
Standardization is the primary hurdle between a functioning Kubernetes environment and a scalable enterprise asset. The risk lies in the invisible friction that accumulates when different departments treat the cloud as a personal playground rather than a unified corporate resource. This fragmentation directly correlates with increased burn rates and delayed market entry.
1. Fragmented Infrastructure Standards
When a central governance model is missing, engineering teams prioritize immediate delivery over long-term architectural health. This leads to a patchwork of configurations that are nearly impossible to manage at scale. Over time, even small infrastructure inconsistencies compound into major operational challenges.
Diverse CI/CD Pipelines
The path to production is rarely uniform in a non-standardized environment. One team might use GitLab CI for its deep integration, while another opts for GitHub Actions or Jenkins. This lack of a unified pipeline means that security gates, automated testing, and deployment strategies vary wildly across the organization. For the business, this creates an unpredictable release cycle where one product is stable and another is prone to deployment-related outages.
Inconsistent Network Policies
Kubernetes relies on namespaces to isolate workloads, but without strict standards, these often become disorganized. Some teams might over-isolate, creating complex networking hurdles, while others might neglect isolation entirely. This inconsistency makes it difficult to apply Global Network Policies, leaving the platform vulnerable to lateral movement during a security breach.
Environment Drift
The most common operational nightmare is environment drift. When the staging environment does not perfectly mirror production, bugs that were supposedly fixed reappear during launch. This creates uncertainty in deployments and increases troubleshooting time for engineering teams. Over time, repeated inconsistencies reduce confidence in the entire release process.
- Configuration Mismatch: Different versions of ingress controllers or service meshes.
- Resource Limits: Variations in CPU and memory requests that lead to unpredictable performance.
- Version Lag: Clusters running on different versions of Kubernetes, making global updates a manual and risky process.
2. Isolated Kubernetes Knowledge
Operational risk is often tied to people rather than code. In many organizations, Kubernetes expertise is concentrated in a small group of specialists, creating a high-stakes dependency. When critical knowledge is not shared across teams, even routine infrastructure tasks become difficult to manage. This dependency slows scalability and increases operational vulnerability during team transitions.
| Risk Factor | Business Impact |
| Expert Dependency | If one or two key architects leave, the ability to maintain or troubleshoot the platform vanishes. |
| Slow Onboarding | New hires spend weeks learning specific quirks of a custom-built environment instead of contributing. |
| Tribal Knowledge | Critical operational procedures exist only in the minds of veteran engineers, making scalability impossible. |
The isolation of knowledge means you are not building a platform. You are building a dependency on a few individuals. This represents a significant single point of failure that can halt growth overnight.
3. Multi-Cloud Complexity
The promise of multi-cloud is often overshadowed by the reality of operational divergence. AWS, Azure, and GCP each have unique ways of handling identities, storage, and networking, which complicates any attempt at a unified standard. As cloud environments expand, maintaining consistent policies and workflows becomes increasingly difficult. This operational fragmentation often leads to higher management overhead and reduced platform visibility.
- Diverse Operational Models: Managing EKS is fundamentally different from managing GKE. The underlying security groups, load balancers, and IAM roles do not translate directly, forcing teams to learn multiple platforms.
- Fragmented Observability: Without a centralized monitoring strategy, logs and metrics are scattered across different cloud-native tools. This fragmentation makes it nearly impossible to get a single-pane-of-glass view of the entire ecosystem’s health.
- Inconsistent Security: A security policy that works on one cloud may not be enforceable on another. This leads to a situation where the enterprise is only as secure as its weakest cloud configuration.
4. Degraded Developer Experience
The ultimate victim of poor standardization is the developer. When the infrastructure becomes too complex, the people hired to build products spend more time acting as amateur system administrators. Developers are forced to navigate inconsistent workflows, deployment rules, and infrastructure dependencies daily. This not only reduces productivity but also slows overall engineering momentum across teams.
The Productivity Tax: When developers have to manage their own namespaces, secrets, and deployment manifests, they are effectively paying a tax on their productivity. This shift in focus results in slower feature releases and increased frustration within the engineering organization.
The Business Risks of Poor Kubernetes Governance
For leadership, the danger of poor Kubernetes governance is rarely immediate. Instead, it is a slow erosion of margins and agility. When governance is treated as an afterthought, the platform evolves into a collection of technical silos that actively work against the organization’s strategic goals. The financial fallout of this neglect manifests in inflated cloud bills, security vulnerabilities, and a catastrophic drop in engineering output.

1. Declining Velocity as Teams Scale
As the organization grows, the absence of a unified governance framework creates a friction-heavy environment. What was once a fast-moving culture becomes bogged down by the weight of uncoordinated infrastructure decisions. Teams begin adopting different operational practices, making collaboration and scalability increasingly difficult across the organization.
- Slower Deployments: Without standardized pathways, every environment requires unique configurations. This manual overhead turns a five-minute deployment into a multi-hour ordeal.
- Operational Dependencies: Teams become locked in a web of dependencies. If a team needs a networking change to launch, they must wait for an overstretched infrastructure team to manually approve a request that should have been automated.
- Increased Deployment Failures: Inconsistency is the primary driver of outages. When cluster configurations are not identical, code that passes in staging fails in production, leading to costly rollbacks.
2. Security and Compliance Hurdles
In a decentralized Kubernetes ecosystem, security is often applied inconsistently, leaving high-value assets exposed. For regulated industries, this lack of oversight is a significant risk. Security teams struggle to enforce consistent controls across clusters managed by different departments. Minor policy gaps can quickly evolve into major compliance and operational vulnerabilities.
Inconsistent RBAC Policies
Role-Based Access Control is the first line of defense. However, without centralized governance, permissions are often granted too broadly. Developers may end up with administrative rights across multiple clusters, violating the principle of least privilege and increasing the blast radius of a potential compromise.
Weak Policy Enforcement
Without automated policy engines, there is no way to ensure that containers run with necessary security constraints. One team might allow privileged containers, while another enforces strict profiles. This inconsistency makes it impossible to guarantee a uniform security posture.
Audit and Compliance Gaps
When an audit occurs, the burden of proof lies with leadership. If every cluster has its own logging and access protocols, gathering evidence becomes a weeks-long manual effort. This lack of transparency is a major financial liability. Compliance teams often spend excessive time reconciling fragmented records across environments. Delayed audit responses can also increase the risk of penalties and reputational damage.
3. Escalating Infrastructure Costs
Unchecked Kubernetes environments are notoriously inefficient at wasting capital. Without a governance layer to monitor resource usage, the cloud bill becomes a black hole of wasted spend. Unused workloads, idle nodes, and poorly optimized clusters silently drive infrastructure costs higher over time. Limited visibility into resource consumption also makes long-term budgeting and forecasting difficult for leadership teams.
The Cost of Chaos: Organizations without centralized governance typically spend significantly more on cloud infrastructure than those with standardized resource controls due to the lack of visibility.
| Cost Driver | Business Impact |
| Duplicate Tooling | Multiple departments paying for separate licenses of the same software. |
| Overprovisioning | Teams requesting excessive CPU and RAM limits, leading to idle clusters and high costs. |
| Operational Overhead | More headcount required to manage the complexity of fragmented systems. |
4. Scaling AI and Data Workloads
As enterprises rush to integrate Artificial Intelligence, Kubernetes governance becomes the deciding factor in project success. AI and Machine Learning (ML) workloads have unique requirements that fail in fragmented environments. Without centralized operational standards, scaling AI initiatives across teams becomes increasingly difficult and resource-intensive.
GPU Orchestration Challenges
GPUs are expensive, high-demand resources. Without centralized governance, one team might monopolize GPU nodes for a non-critical experiment, leaving a revenue-generating model unable to scale. Governance ensures these assets are allocated based on priority. This improves resource efficiency while reducing infrastructure bottlenecks for critical AI workloads.
Shared Infrastructure Conflicts
Data pipelines are resource-intensive. In a poorly governed cluster, a massive data job can starve critical web services, leading to performance degradation. Centralized governance implements protections that prevent one workload from impacting another. Workload isolation policies help maintain consistent application performance across shared environments.
Strategic ML Governance
Successful AI deployment requires a unified approach to data ingestion and model serving. If every team builds a bespoke pipeline, the organization loses the ability to scale models into production. Governance provides the framework necessary for AI to move from the lab to the market. Standardized governance also accelerates collaboration between platform, data, and ML engineering teams.
What Standardized Kubernetes Operations Look Like?
Standardization is the transition from managing individual clusters to managing a unified platform. In a mature environment, Kubernetes infrastructure is no longer a bespoke creation for every new project. It is a reliable and repeatable service. This shift represents the industrialization of software delivery, where output becomes predictable, and overhead remains lean.

At IdeaUsher, we facilitate this evolution by providing pre-vetted engineers who arrive with these frameworks already mastered, ensuring capital is spent on growth rather than troubleshooting.
1. Unified Kubernetes Templates
High-performing organizations eliminate the blank page problem for developers by providing standardized blueprints. This ensures that every new service is born into a compliant and well-architected environment from day one. Developers spend less time configuring infrastructure and more time building core product features.
- Standardized Deployment Blueprints: Instead of writing complex manifests from scratch, we help teams implement pre-approved templates that include baseline configurations for high availability, scaling, and logging.
- Reusable Infrastructure Modules: Using tools like Terraform or Pulumi, we build a library of vetted modules for your organization. If a team needs a database or a cache, they pull a module that our experts have already cleared for security.
- Consistent Policies: By standardizing how namespaces and network policies are defined, we ensure that every application is isolated by default. This creates a secure-by-design architecture that scales without constant manual intervention.
2. Centralized CI/CD Governance
Standardization at the deployment level ensures that every piece of code undergoes the same rigorous checks before it reaches a customer. We integrate these guardrails naturally into existing workflows to maintain speed without sacrificing quality. This creates a more reliable release process while reducing deployment-related risks across teams.
Shared Deployment Pipelines
Instead of dozens of bespoke scripts, we maintain a set of golden pipelines for our clients. These shared workflows integrate security scanning, linting, and testing as non-negotiable steps. This centralization ensures that a change in security policy can be rolled out across an entire company by updating a single pipeline template.
GitOps-Based Workflows
Our approach uses GitOps as the single source of truth for the state of the infrastructure. By deploying tools like ArgoCD or Flux, the actual state of a Kubernetes cluster is always synchronized with a Git repository. This provides an immutable audit log of every change, making rollbacks instantaneous and disaster recovery a scripted process rather than a chaotic one.
Automated Environment Promotion
We implement standardization to allow for a waterfall of automated testing. Code moves from development to staging to production only after passing standardized health checks. This removes the it worked on my machine excuse and ensures that the production environment remains a stable and protected zone.
3. Platform Engineering
The goal of our platform engineering approach is to hide the scaffolding of Kubernetes so developers can focus on building value. By hiring from our pool of specialized talent, organizations bypass the learning curve associated with complex orchestration. This enables engineering teams to ship products faster without being slowed down by infrastructure complexity.
| Feature | Strategic Impact |
| Self-Service Platforms | We enable developers to provision their own environments via a portal, removing the DevOps team as a bottleneck. |
| Reduced Dependency | Our developers build the tools so internal teams can simply use them. This decouples daily operations from specialized infrastructure knowledge. |
| Rapid Onboarding | Because we provide all the necessary scaffolding and documentation, new engineers can push code almost immediately. |
By treating the internal platform as a product, we ensure that the infrastructure serves the developers rather than the developers serving the infrastructure.
4. Built-In Security and Compliance
When we standardize operations, security is no longer a check-the-box activity at the end of a sprint. It is baked into the very fabric of the platform. Security controls become part of everyday development workflows rather than isolated review processes. This allows teams to maintain compliance and reduce risk without slowing delivery velocity.
Policy-as-Code Enforcement
Using frameworks like OPA (Open Policy Agent), we enable the platform to automatically reject any deployment that does not meet security standards, such as running as a root user or lacking resource limits. This provides real-time and automated governance that does not require a human reviewer.
Centralized Secrets Management
We replace scattered environment variables with a centralized vault like HashiCorp Vault or AWS Secrets Manager. This ensures that sensitive credentials never touch a Git repository and are rotated automatically, significantly reducing the risk of a data breach. It also improves visibility and control over how credentials are accessed across environments.
Continuous Compliance Monitoring
In the standardized environments we build, compliance is a continuous state, not a quarterly audit. We set up the platform to constantly monitor the state of all clusters against regulatory frameworks like SOC2 or HIPAA, providing leadership with a real-time dashboard of the risk posture. This transparency is vital for maintaining the trust of stakeholders and customers alike.
How Platform Engineering Improves Kubernetes Standardization?
Platform engineering represents the evolution of cloud infrastructure from a manual craft to a scalable product. At IdeaUsher, we view the platform as the connective tissue between raw infrastructure and application logic. By abstracting the complexities of the underlying environment, we enable organizations to enforce high-level standards without slowing down the development cycle. This transition is less about the technology itself and more about how we optimize the flow of value from code to customer.
1. Investing in Internal Platforms
Strategic investment in Internal Developer Platforms is driven by the need to eliminate the friction inherent in raw Kubernetes. Modern enterprises are moving away from decentralized management in favor of a unified experience. This shift helps organizations improve operational consistency while simplifying infrastructure management at scale.
- Reducing Complexity: We replace fragmented configurations with a streamlined interface. Instead of navigating the landscape of raw primitives, teams interact with tools aligned with business requirements.
- Accelerating Onboarding: When we standardize the platform, the time it takes for a new engineer to become productive drops from weeks to days. All networking and security protocols are already in place.
- Improving Consistency: By using a unified platform, we ensure every deployment follows the same logical path. This removes the variability that often leads to environment-specific bugs and production outages.
2. Automation Reduces Management Overhead
The scale of modern container environments makes manual management an impossibility. We implement automation to ensure that standardization is an inherent property of the system rather than a manual checklist. This reduces operational burden while improving consistency across large-scale Kubernetes environments.
Automated Cluster Provisioning
We eliminate the risk of snowflake clusters by automating the entire lifecycle of the infrastructure. Every cluster we deploy is generated from a master blueprint, ensuring that compute, storage, and networking are identical across every environment. Standardized provisioning also simplifies maintenance and future scalability efforts.
IaC Standardization
By treating your infrastructure as versioned code, we create a repeatable process for every change. We use tools like Terraform and Crossplane to define the desired state of the environment, ensuring the platform remains audit-ready across different cloud providers. This approach improves infrastructure visibility and minimizes configuration drift over time.
Resource Optimization Policies
Inefficient resource allocation is a significant drain on capital. We implement automated policies that monitor cluster health and adjust resource limits in real-time. This prevents overprovisioning and ensures infrastructure costs scale with actual usage. Teams gain better utilization without constantly managing resources manually.
3. Shared Observability and Reliability
Standardization is only as good as your ability to measure it. We build shared observability directly into the platform to provide a single source of truth for the entire engineering organization. Centralized visibility helps teams identify operational issues before they impact business performance. It also improves collaboration by ensuring every team works from the same operational data and metrics.
| Component | Impact on Reliability |
| Unified Monitoring | We aggregate metrics from all clusters into a single dashboard, allowing leadership to see ecosystem health at a glance. |
| Faster Incident Detection | Standardized alerting rules mean teams are notified of issues before they impact the end-user, reducing recovery time. |
| Centralized Logging | By funneling all logs into a centralized system, we enable deep-dive forensics without searching through fragmented data. |
4. Improve Developer Experience
The ultimate measure of a standardized platform is the experience of the people using it. When we remove the burden of infrastructure management, developers are free to innovate. Engineering teams can focus more on product development and customer outcomes instead of operational troubleshooting. This also improves developer productivity and accelerates feature delivery across the organization.
Focus on the Product: When the platform handles the intricacies of Kubernetes, your developers spend 90% of their time writing application logic and only 10% on configuration. This is a complete reversal of the industry average in non-standardized environments.
Why Kubernetes Standardization Projects Often Fail?
Standardization initiatives frequently collapse because they are treated as static administrative mandates rather than living engineering products. At IdeaUsher, we have observed that the primary reason these projects stall is a fundamental misalignment between top-down control and the bottom-up reality of daily development. If the transition to a unified platform feels like an obstacle to your engineers, they will find ways to bypass it, leading to the very fragmentation the project was designed to solve.

1. Resistance to Rigid Governance
The friction between speed and safety is the most common point of failure. When governance is too restrictive, it stifles the creative autonomy that developers value. Engineering teams often become frustrated when simple operational tasks require excessive approvals or manual intervention. Overly rigid governance can also slow innovation and reduce overall platform adoption across teams.
- Adoption Bottlenecks: Standardization without flexibility is a recipe for low adoption. If a developer cannot experiment or adjust a resource limit without three levels of approval, they will revert to shadow IT.
- Restrictive Workflows: Many organizations force every team into a single workflow that does not account for different workload types. A data science team has different needs than a frontend team.
- Supporting Agility: Governance must be an enabler, not a gatekeeper. We focus on building guardrails that allow for high-speed maneuvering within a safe zone, ensuring engineering agility remains intact.
2. Lack of Internal Expertise
The Kubernetes maturity gap is a silent killer of standardization. Most organizations have great application developers, but very few have the deep systems expertise required to architect a sustainable governance model. As infrastructure complexity increases, this expertise gap becomes a major barrier to long-term scalability and operational stability.
| Maturity Challenge | Business Impact |
| Expertise Gap | Internal teams often rely on trial and error, leading to fragile architectures that fail under load. |
| Scalability Hurdles | Governance that works for three clusters often breaks when the organization scales to thirty or three hundred. |
| Sustainability | Long-term platform engineering requires a dedicated focus that internal teams, busy with product features, cannot maintain. |
By hiring from our pool of pre-vetted Kubernetes specialists, you fill this expertise gap immediately. We provide the architectural muscle needed to design a platform that remains manageable as your organization grows.
3. Tooling Cannot Fix Chaos
Buying expensive monitoring or security software will not fix a broken process. Automation and tools are only effective when they are built on a foundation of operational alignment. Without clearly defined workflows and ownership, even advanced tooling becomes difficult to manage effectively.
Aligning Governance Processes
Before we automate, we align. Standardization is a cultural shift as much as a technical one. It requires defining who owns the cluster lifecycle, who manages the secrets, and how teams communicate when a deployment fails. Clear governance structures help reduce operational confusion and improve accountability across teams.
Prioritizing Developer Enablement
A platform is only successful if people use it. We prioritize developer enablement, providing the documentation and Golden Paths that make the standardized way of working the easiest way of working. Simplified workflows encourage faster adoption and reduce resistance to platform standards.
Supporting Team Workflows
Automation should be invisible. We build systems that integrate into existing workflows, ensuring policy enforcement happens in the background without requiring developers to learn a dozen new interfaces. This allows teams to maintain productivity while governance operates seamlessly behind the scenes.
4. Sustainability of Multi-Team Governance
The final hurdle is longevity. Maintaining consistent standards across multiple departments requires constant vigilance and coordination. As teams evolve, operational priorities and infrastructure requirements often begin to diverge across the organization. Without continuous governance reviews, inconsistencies gradually reappear and weaken platform reliability over time.
The Maintenance Trap: It is relatively easy to set up a standardized cluster. It is incredibly difficult to keep ten departments aligned with that standard months later as their individual requirements evolve.
How Idea Usher Simplifies Kubernetes Standardization?
Standardization is not a one-time configuration but a continuous engineering effort. At IdeaUsher, we move beyond the theoretical to provide actionable infrastructure blueprints that allow businesses to scale without the typical friction of cloud-native growth. We help you transform Kubernetes from a complex management burden into a silent, reliable utility. By leveraging our pre-vetted specialists, you gain immediate access to institutional knowledge that prevents the common pitfalls of architectural drift and operational sprawl.

1. Developer-Friendly Workflows
A platform is only as good as its adoption rate. We focus on building workflows that developers actually want to use, replacing manual complexity with intuitive, automated paths to production. Simplified workflows reduce operational friction and improve developer productivity across teams. When the platform experience feels seamless, adoption naturally increases throughout the organization.
- Workflow Adoption: We build Golden Paths that remove the need for developers to master every Kubernetes primitive. By simplifying the interface between code and cluster, we ensure that the standardized way is also the fastest way.
- Platform Abstraction: Through expert platform engineering, we wrap complex deployment logic into simple, repeatable actions. This allows your product teams to trigger deployments, scale services, and manage logs without ever leaving their familiar environments.
- Complexity Reduction: We audit and prune unnecessary infrastructure layers. By reducing the number of manual touchpoints required to ship code, we minimize the chance of human error and significantly lower the cognitive load on your engineering talent.
2. Designing Reusable Architectures
Efficiency in the cloud is born from reusability. We treat infrastructure as a modular product, ensuring that the work done for one team can be leveraged by the entire organization. Shared infrastructure patterns reduce duplication of effort across engineering teams. This approach also improves operational consistency while accelerating infrastructure delivery at scale.
Standardized Cluster Templates
We provide master templates that serve as the DNA for every cluster in your ecosystem. Whether you are deploying on AWS, Azure, or GCP, these templates ensure that networking, security headers, and observability agents are identical, making global management a reality.
3. Reusable Infrastructure Modules
Instead of bespoke scripting, we utilize a library of vetted Infrastructure-as-Code (IaC) modules. This allows teams to deploy infrastructure faster with far greater consistency across environments. Standardized modules also reduce configuration drift and simplify long-term maintenance efforts. Engineering teams can reuse proven infrastructure patterns without rebuilding components from scratch for every project.
- Security-First: Every module is pre-scanned for vulnerabilities and compliance.
- Consistent Scaling: Load balancers and auto-scaling groups are configured to enterprise-grade standards by default.
- Interoperability: Modules are designed to talk to each other seamlessly, regardless of which team is deploying them.
Scalable Environment Strategies
We implement multi-tenant and multi-cluster strategies that grow with your user base. By standardizing how environments like staging, UAT, and production are segregated, we ensure that your data remains isolated and your release cycles remain predictable.
4. Aligning Governance With Growth
Governance should never be a bottleneck to innovation. We design oversight mechanisms that provide transparency and security while supporting the rapid pace of modern engineering. Automated controls help teams maintain compliance without slowing down deployment cycles. This creates a balance between operational stability and fast-moving product development.
| Growth Pillar | IdeaUsher Strategy |
| Engineering Expansion | We build self-service portals that allow you to double your headcount without doubling your infrastructure team. |
| Innovation Speed | Our guardrails are automated, not manual. Developers get instant feedback on their configurations through policy-as-code. |
| Scalable Foundations | We architect the platform to handle increasing load and complexity without requiring a complete rewrite of your core systems. |
How Idea Usher Enables Platform Engineering?
Platform engineering is the critical discipline of binding together the tools and processes that make up a software development lifecycle. At IdeaUsher, we do not just manage clusters. We build the internal highways that allow your engineering teams to travel from ideation to production without getting lost in the weeds of Kubernetes configuration. By treating the platform as a product, we ensure that your infrastructure is an accelerator for your business goals rather than a drag on your operational budget.
1. Automating Operations
Automation is the bedrock of a scalable platform. We move your organization away from manual heroic efforts toward a state of predictable, automated stability. This creates a resilient operational foundation that scales efficiently as infrastructure complexity grows. It also improves operational reliability by minimizing human error across critical infrastructure workflows..
- Eliminating Repetitive Tasks: We automate the mundane aspects of cluster management, such as certificate rotation, node scaling, and patch management. This frees your high-cost talent to solve business-specific problems.
- Standardizing Deployments: Through automation, we ensure that every deployment is a mirrored reflection of the last. This repeatability is the only way to achieve true reliability at scale.
- Reducing Operational Overhead: By implementing self-healing infrastructure patterns, we reduce the volume of low-value support tickets that typically overwhelm DevOps teams.
2. Building Internal Developer Platforms
An Internal Developer Platform acts as a specialized interface between the developer and the cloud. We build these portals to provide the right balance of autonomy and control. This allows engineering teams to innovate faster without compromising governance, security, or operational consistency.
Self-Service Provisioning
We empower your developers to spin up the resources they need, whether it is a new namespace, a database, or a cache, through a pre-configured service catalog. This removes the ticket-based bottleneck, allowing teams to move at the speed of their own ideas while staying within the cost and security guardrails we establish.
Standardized Pipelines
Our IDPs feature unified pipelines that bake in security scanning and compliance checks automatically. This ensures that no matter which team is shipping code, the path to production remains identical, audited, and secure.
Centralized Monitoring
We integrate a single pane of glass for observability. By centralizing logs and metrics within the IDP, we give every stakeholder the visibility they need to understand system health without needing to access raw cluster data.
3. Unified Kubernetes Workflows
Fragmentation is the enemy of speed. We create a unified experience that bridges the gap between different engineering functions, from frontend developers to data scientists. By standardizing workflows and tooling, we reduce operational silos that often slow down collaboration. This creates a smoother development lifecycle where teams can ship updates faster with greater confidence and consistency.
| Workflow Benefit | Operational Outcome |
| Consistent Experiences | The workflow for deploying services remains the same across the entire enterprise regardless of the cloud provider. |
| Faster Onboarding | New hires can contribute on their first day because the platform abstracts away the complexity of the underlying infrastructure. |
| Improved Collaboration | By using a common toolset, DevOps and Product teams collaborate on architectural improvements rather than fighting over configuration errors. |
How Idea Usher Solves Kubernetes Governance Challenges?
Effective governance is the difference between a secure, cost-effective infrastructure and a chaotic collection of cloud assets. At IdeaUsher, we address these challenges by implementing centralized controls that do not compromise engineering speed. We transform Kubernetes governance from a reactive manual audit into an automated, proactive system. By deploying our pre-vetted experts into your team, we ensure your platform adheres to the highest standards of security and operational integrity.
1. Standardizing Cluster Security
In a decentralized environment, security is often the first casualty of speed. We prevent this by baking security protocols directly into the cluster lifecycle. By automating policy enforcement and access controls, we reduce the risk of misconfigurations across distributed environments. This ensures security remains consistent even as development teams scale and deploy faster.
- Centralized RBAC: We implement unified Role-Based Access Control that spans your entire infrastructure. This ensures permissions follow the principle of least privilege, reducing the blast radius of any potential security incident.
- Policy-as-Code: Using tools like OPA Gatekeeper, we create automated guardrails. Any deployment that fails to meet requirements, such as missing resource limits or insecure images, is rejected before it reaches production.
- Reducing Drift: We use automated reconciliation loops to ensure clusters stay in their desired state. If a manual change deviates from the established standard, the system corrects it automatically to maintain consistency.
2. Multi-Cloud Kubernetes Management
As businesses expand across AWS, Azure, and GCP, the complexity of maintaining a single governance standard increases. We specialize in creating a cloud-agnostic governance layer. This allows organizations to enforce consistent policies, security controls, and operational standards across every Kubernetes environment.
Unified Governance
We build a control plane that treats every cloud provider as a standard compute resource. This allows you to apply the same security and compliance policies to an EKS cluster as you do to a GKE cluster, ensuring a seamless experience. Teams can operate across cloud environments without constantly adapting to provider-specific governance models.
Cross-Cluster Observability
Data silos are the enemy of governance. We implement centralized observability stacks that aggregate telemetry from every cloud provider into one dashboard. This provides a holistic view of ecosystem health and spending. Centralized insights also make it easier to identify performance bottlenecks and optimize operational efficiency.
Standardized Networking
Managing communication across different clouds is difficult. We implement a standardized service mesh strategy that ensures networking policies remain consistent and enforceable, protecting data as it moves across cloud boundaries. This improves workload reliability while maintaining secure communication between distributed services.
3. Improving Kubernetes Visibility
You cannot govern what you cannot see. We provide the tools and processes necessary to turn raw infrastructure data into actionable business intelligence. By centralizing visibility across clusters and cloud environments, we help teams make faster and more informed operational decisions. This improves accountability, strengthens governance, and reduces the time required to resolve infrastructure issues.
| Visibility Feature | Business Impact |
| Infrastructure Dashboards | A single source of truth for resource utilization to identify waste and optimize cloud spend. |
| Shared Insights | Making data available to both developers and management to foster a culture of accountability. |
| Faster Incident Response | Standardized logging allows teams to pinpoint root causes in minutes rather than hours, protecting uptime. |
By solving the governance puzzle, we allow your organization to scale with confidence. Our approach ensures your Kubernetes environment remains a disciplined, high-performance engine. We do not just solve technical hurdles. We align your infrastructure with your broader corporate compliance and financial goals.
How Idea Usher Uses Kubernetes Automation?
Automation is the cornerstone of a resilient and cost-effective cloud strategy. At IdeaUsher, we view manual intervention as a scalability risk. We replace bespoke, human-led processes with robust automated systems that ensure your Kubernetes environment remains consistent regardless of its size. By removing the need for heroic individual efforts, we create a stable foundation where infrastructure behaves exactly as expected every single time.
1. Eliminating Manual Management
The transition from manual tweaks to automated operations is where organizations find true efficiency. We help you move away from the high-risk “snowflake” model where every cluster has its own unique configuration quirks. This creates a more predictable infrastructure environment that is easier to scale, manage, and secure over time.
- Automated Cluster Provisioning: We utilize master templates to spin up new clusters across any cloud provider. This ensures that every node, network bridge, and security setting is identical from the start.
- Standardized IaC Workflows: By using Infrastructure-as-Code (IaC), we treat your data center as software. Every change is documented, peer-reviewed, and applied via script, ensuring a transparent audit trail.
- Reduced Operational Errors: Automation eliminates the “fat-finger” mistakes that account for the majority of production outages. We build systems that perform the heavy lifting of scaling and patching, allowing your engineers to focus on higher-value tasks.
2. Using GitOps for Consistency
Consistency is achieved when the “desired state” of your infrastructure is clearly defined and strictly enforced. We utilize GitOps methodologies to make your repository the single source of truth for the entire platform. This creates a more reliable operational model where infrastructure changes remain transparent, repeatable, and easy to govern.
Version-Controlled Infrastructure
By storing all Kubernetes manifests in Git, we ensure that every change to the environment is versioned. This provides a clear history of who changed what and why, making compliance and auditing a natural byproduct of the development process. It also improves collaboration by giving engineering teams a centralized and traceable workflow for infrastructure management.
Automated Rollbacks
If a deployment causes instability, our GitOps-driven platforms allow for near-instantaneous rollbacks. By simply reverting to a previous Git commit, the cluster automatically resynchronizes to the last known stable state, minimizing downtime and customer impact. This helps teams recover faster from failed deployments while maintaining operational continuity.
Continuous Configuration Validation
We implement automated checks that constantly compare the actual state of the cluster with the desired state defined in Git. If unauthorized changes are detected, the system automatically overwrites them, effectively eliminating configuration drift. This ensures infrastructure remains aligned with approved governance and security standards at all times.
3. Building Self-Healing Platforms
A truly mature platform should be able to recover from failures without human intervention. We architect self-healing mechanisms into the core of your Kubernetes strategy to ensure maximum uptime. This minimizes operational disruptions and helps maintain consistent application performance during unexpected failures.
Resilience by Design: Automation is the bedrock of a scalable platform. We move your organization away from manual heroic efforts toward a state of predictable, automated stability. This transition ensures that your infrastructure remains resilient under pressure while allowing your internal teams to focus on high-level strategy rather than routine maintenance.
| Self-Healing Feature | Impact on Business Continuity |
| Automated Remediation | Workflows that detect failing nodes or containers and restart them automatically before users notice an issue. |
| Resilient Infrastructure | Designing clusters to automatically redistribute workloads when hardware failures occur, ensuring zero-downtime operations. |
| Faster Recovery | Pre-scripted disaster recovery paths that can rebuild an entire environment from scratch in minutes, not days. |
Questions to Ask Before Standardizing Kubernetes
Standardization is a major strategic pivot. Before committing resources, leadership must evaluate if their current Kubernetes environment is a foundation for growth or a source of technical debt. At IdeaUsher, we guide partners through these critical self-assessments to identify where pre-vetted expertise can bridge the gap between current chaos and future stability.
Do We Have Consistent Governance?
Governance is often the first operational layer to break as engineering teams expand. If every team follows different deployment, security, or infrastructure practices, operational risk grows rapidly. Without standardized governance, maintaining compliance and infrastructure consistency becomes increasingly difficult at scale.
- The Audit Test: Could you produce a unified compliance report for every cluster in your fleet within an hour?
- The Drift Reality: Are your staging and production environments identical, or do they suffer from undocumented manual tweaks?
- Centralized Control: Without a single source of truth for policies, governance remains a manual and error-prone task.
Can Developers Deploy Without Bottlenecks?
A modern Kubernetes platform should accelerate development rather than slow it down. If developers spend more time managing YAML files, infrastructure tickets, or deployment approvals than building products, standardization efforts remain incomplete. An effective platform should simplify operations while improving development velocity.
The Velocity Indicator: Automation is the bedrock of a scalable platform. We move your organization away from manual heroic efforts toward a state of predictable and automated stability. This transition ensures your infrastructure remains resilient under pressure while allowing internal teams to focus on high-level strategy rather than routine maintenance.
Are Security Policies Enforced Across Clusters?
Security should never depend on manual enforcement or individual engineering habits. In mature Kubernetes environments, security policies are automatically inherited and consistently applied across every workload and cluster. Standardized security enforcement reduces vulnerabilities while improving operational confidence.
| Security Question | Risk Factor |
| RBAC Consistency | Do developers have excessive permissions in production clusters? |
| Image Scanning | Is every container scanned for vulnerabilities before deployment? |
| Network Isolation | Are workloads isolated by default to prevent lateral movement during a breach? |
Is the Platform Ready for AI Workloads?
AI and machine learning workloads place unique demands on Kubernetes infrastructure, especially around GPU orchestration, resource allocation, and data-intensive operations. Without proper standardization, AI workloads can quickly create infrastructure instability and resource contention. A well-governed platform ensures these workloads scale efficiently without impacting overall system performance.
GPU Scarcity Management
Standardization ensures that expensive GPU resources are not hoarded by a single team. We implement priority-based scheduling and fair-share policies to ensure your most critical AI models have the compute they need. This creates a balanced infrastructure environment where AI workloads can scale efficiently without impacting other critical services.
Data Pipeline Stability
AI workloads can be noisy neighbors. Without standardized resource quotas and limits, a large training job could starve your customer-facing web services of CPU and memory. We implement resource governance policies that maintain workload isolation and platform stability across shared environments. This ensures critical applications continue performing reliably even during resource-intensive AI processing tasks.
Can the Infrastructure Scale Long-Term?
Standardization ensures that expensive GPU resources are not hoarded by a single team. We implement priority-based scheduling and fair-share policies to ensure your most critical AI models have the compute they need. This improves resource utilization while preventing infrastructure bottlenecks across shared AI environments.
- Vendor Lock-in: Is your standardization tied to a specific cloud provider or can you move workloads seamlessly?
- Operational Headcount: Will you need to hire a new DevOps engineer for every five new developers, or does the platform allow for non-linear growth?
- Unified Vision: Does the entire engineering function agree on the Golden Path, or are there silos building their own alternative infrastructure?
Why Choose Idea Usher to Standardize Kubernetes?
Standardizing a cloud-native ecosystem requires more than just technical knowledge. It requires the battle-tested experience of having seen where systems break at scale. With over 500,000 hours of coding experience, our team of ex-MAANG/FAANG developers brings a level of precision to Kubernetes that is rarely found in the general talent pool. We do not just build clusters. We engineer the high-performance environments that allow your business to outpace the competition.
1. Access to Pre-Vetted Experts
Hiring for specialized infrastructure roles is a notoriously slow and expensive process. We eliminate that friction by providing immediate access to an elite tier of engineering talent. Our experts integrate seamlessly into existing workflows, helping teams accelerate Kubernetes initiatives without lengthy onboarding cycles.
- Faster Implementation: Our developers arrive ready to execute, skipping the long learning curves associated with complex orchestration projects.
- Enterprise-Grade Expertise: By leveraging engineers who have worked within the world’s most demanding tech stacks, you ensure your infrastructure is built to withstand extreme scale.
- Reduced Overhead: We handle the vetting, testing, and training, allowing you to scale your engineering capacity without the long-term liability of traditional hiring.
2. Multi-Environment Experience
Our 500,000 hours of development history span a diverse range of complex environments. We understand the nuances of different business models and how they impact infrastructure design. This broad experience allows us to build Kubernetes strategies that align with both technical and operational business goals.
SaaS and Product Engineering
We build multi-tenant architectures that ensure high availability and data isolation. This allows providers to onboard customers rapidly without worrying about cross-contamination or performance degradation. Standardized infrastructure also improves scalability as customer demand and application workloads continue to grow.
AI Infrastructure Platforms
Our team understands the unique requirements of AI and Machine Learning. We implement the specific scheduling and resource management strategies needed to keep expensive GPUs active and data pipelines flowing smoothly. This helps organizations maximize infrastructure efficiency while supporting high-performance AI workloads reliably.
Multi-Cloud Kubernetes
We excel at creating a unified experience across AWS, Azure, and GCP. Our approach ensures that your governance and deployment patterns remain identical, regardless of which cloud provider you choose to host your workloads. This consistency simplifies operations while reducing the complexity of managing distributed Kubernetes environments.
3. A Platform-First Approach
We believe that the best infrastructure is the kind that developers never have to think about. Our philosophy centers on creating a seamless bridge between code and production. By simplifying operational complexity behind standardized workflows, we help developers focus entirely on building and shipping products. This creates a faster and more reliable software delivery experience across the organization.
Operational Excellence: Automation is the bedrock of a scalable platform. We move your organization away from manual heroic efforts toward a state of predictable and automated stability. This transition ensures your infrastructure remains resilient under pressure while allowing internal teams to focus on high-level strategy rather than routine maintenance.
We design governance that is built for scale, ensuring that security and compliance are inherent properties of the platform. By focusing on a developer-centric design, we make the standardized path the path of least resistance.
4. Achieving Kubernetes Maturity
The journey to architectural maturity is a transition from chaos to a silent, efficient engine. We partner with you to navigate each stage of this evolution. Our approach focuses on building scalable operational foundations that continue to perform reliably as business demands grow. This enables organizations to modernize infrastructure without sacrificing stability, governance, or development velocity.
The Evolution of Your Infrastructure:
- From Fragmented to Centralized: We consolidate scattered clusters into a single, governed ecosystem with unified oversight.
- From Manual to Automated: We replace fragile, human-dependent tasks with robust, version-controlled automation that eliminates error.
- From Dependency to Self-Service: We remove the DevOps bottleneck, giving your developers the tools to provision their own resources within safe, pre-approved guardrails.
By choosing IdeaUsher, you are not just hiring developers. You are integrating a decade of high-level engineering experience into your organization. We provide the strategic foundation that ensures your technical choices today support your growth for years to come.
Conclusion
Standardizing Kubernetes transforms your infrastructure from a complex hurdle into a strategic growth engine. By implementing unified templates and automated governance, we eliminate the silos that slow innovation and inflate costs. Our approach provides the architectural expertise needed to move from fragmented operations to true engineering maturity. We ensure your platform remains a scalable, invisible utility, allowing your developers to focus entirely on building products that drive your success.
FAQs
Q1: How do we begin standardizing Kubernetes across multiple teams?
A1: Success starts with defining a single source of truth for your cluster configurations. By establishing a library of pre-approved Kubernetes templates and Infrastructure-as-Code modules, we ensure that every team starts from a secure, high-performance baseline. This approach eliminates the creation of snowflake clusters and ensures that your global infrastructure remains consistent as your organization scales.
Q2: What is the best way to manage Kubernetes security in a large organization?
A2: Security must be treated as an automated guardrail rather than a manual checklist. We implement policy-as-code and centralized RBAC to ensure that every Kubernetes workload adheres to the principle of least privilege by default. By automating vulnerability scanning and network isolation, we bake protection directly into the platform so that developers cannot accidentally deploy insecure configurations.
Q3: How does standardization impact the speed of Kubernetes deployments?
A3: Standardization actually increases velocity by removing the cognitive load of infrastructure management from your developers. When we provide a unified Kubernetes platform with self-service provisioning, engineers can ship code faster without waiting on manual approvals or complex environment setups. This transition allows your teams to focus entirely on application logic while the platform handles the underlying orchestration.
Q4: Can we standardize Kubernetes if we use multiple cloud providers?
A4: Yes, true standardization should be cloud-agnostic. We build a unified governance layer that applies the same security, networking, and deployment standards to your Kubernetes clusters whether they are running on AWS, Azure, or GCP. This cross-cloud consistency prevents vendor lock-in and allows your leadership to manage the entire ecosystem through a single, centralized dashboard.






