




Key Takeaways
- Kubernetes multi cloud architecture improves resilience, scalability and cloud flexibility across AWS, Azure and GCP.
- Most multi-cloud failures come from operational complexity, fragmented security and poor workload portability.
- Strong architecture requires GitOps, IaC, service mesh and centralized observability for consistent operations.
- Staff augmentation helps businesses scale Kubernetes faster with lower hiring risk and specialized expertise.
- How Idea Usher provide pre-vetted Kubernetes experts for scalable multi-cloud infrastructure and long-term support.
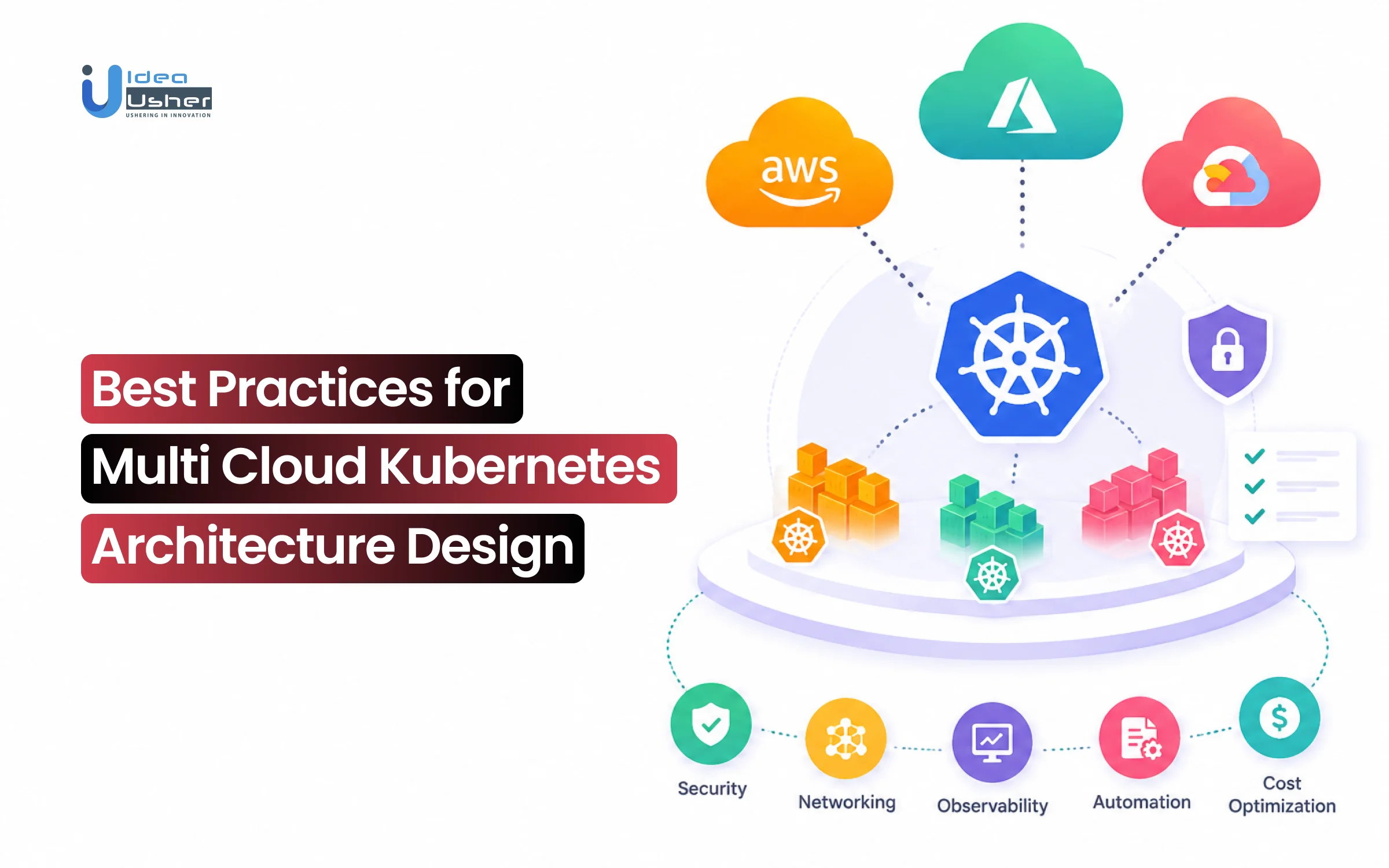
Multi cloud adoption is no longer driven only by redundancy or vendor flexibility. It is becoming a strategy for improving resilience, performance and infrastructure control at scale. That shift is making kubernetes multi cloud architecture a critical focus for modern engineering teams managing distributed workloads across providers.
Traditional cloud architectures were often designed around a single provider with tightly coupled services and limited portability. That model creates operational risks as businesses scale globally and demand greater flexibility. Teams now need kubernetes multi cloud architectures built around workload portability, cross-cloud networking, centralized observability, policy consistency and automated failover to maintain reliability across environments.
In this blog, we will talk about key design principles, architecture best practices, common challenges and how IdeaUsher provides pre-vetted Kubernetes experts for scalable multi-cloud infrastructure.
Why Most Multi Cloud Kubernetes Projects Fail Before Scale
The global Kubernetes Solutions Market is estimated at USD 3.46 billion in 2026 and is projected to reach USD 14.36 billion by 2035, growing at a 17.3% CAGR. This rapid growth reflects how enterprises are increasingly adopting Kubernetes to build scalable, cloud-native infrastructure across multiple environments.

Multi-cloud Kubernetes delivers vendor flexibility and global resilience, with 55% of enterprises using multi-cloud strategies and 84% running Kubernetes in production. Yet many projects fail at scale due to the complexity of managing security, networking, and infrastructure across multiple cloud environments.
A. The Illusion of Multi Cloud Flexibility
Many leadership teams fall into the trap of believing that because Kubernetes is portable, their applications are automatically flexible. They assume that a container running on a local laptop will behave identically on an AWS Nitro instance and a GCP Tau VM, without understanding the infrastructure complexities involved in a scalable kubernetes multi cloud architecture.
In reality, Kubernetes is an abstraction layer that still relies heavily on the underlying cloud provider’s primitives. Without deep architectural expertise, teams often:
- Ignore Storage Classes: Creating persistent volumes that are cloud-specific, making it impossible to move workloads without massive data migration efforts.
- Misconfigure Load Balancers: Failing to account for how different cloud providers handle ingress controllers and external IPs.
- Neglect Networking Plugins (CNIs): Choosing a CNI that works well in one environment but suffers from performance bottlenecks or security gaps in another.
B. Operational Chaos for Managing Kubernetes in Different Cloud
While Kubernetes provides a unified API, the managed services such as EKS (AWS), AKS (Azure) and GKE (GCP) are far from identical. Each has its own way of handling identity and access management (IAM), logging and automated upgrades. The operational chaos in kubernetes multi cloud architecture often stems from fragmented control planes.
- Identity Mismatch: Your DevOps team has to manage AWS IAM roles, Azure Active Directory (Entra ID) and GCP Service Accounts simultaneously.
- Version Drift: One provider might push a mandatory K8s version upgrade while another is three versions behind, leading to API deprecation issues across your fleet.
- Observability Gaps: Trying to stitch together CloudWatch, Azure Monitor and Google Cloud Operations into a single pane of glass often results in a mosaic of dashboards that no one actually uses during a critical outage.
C. Infrastructure Problems Companies Face After Adopting Multi Cloud
Beyond the software, the physical and economic realities of infrastructure often come as a shock after the initial migration.
- Data Gravity and Egress Costs: Data is heavy and moving massive datasets between clouds for processing triggers exorbitant egress fees that can quickly eclipse any savings gained from cheaper compute instances.
- Cross-Cloud Latency: If your frontend is on Azure and your database is on AWS, the speed of light problem becomes a tangible performance bottleneck for your users.
- Security Perimeter Dilution: Maintaining a consistent security posture like firewall rules, secrets management and encryption at rest across three different providers increases the attack surface exponentially.
D. Why Internal DevOps Teams Become Bottlenecks
As companies scale kubernetes multi cloud architecture across multiple cloud providers, operational complexity grows rapidly. Teams often become bottlenecks because they are forced to spend 80% of their time on undifferentiated heavy lifting manually syncing configurations, troubleshooting cross-cloud connectivity and writing glue code to make different services talk to each other.
Instead of focusing on feature delivery or system reliability, internal teams get stuck in a loop of:
- The Build vs. Buy Trap: Trying to build a custom internal developer platform (IDP) to hide the cloud complexity, which eventually becomes another legacy system to maintain.
- Expertise Silos: Having the AWS guy and the Azure girl, creating single points of failure within the team.
- Burnout: The sheer pressure of staying up-to-date with three rapidly evolving cloud ecosystems leads to high turnover in the very roles that are most critical for the project’s success.
What Enterprises Need From a Multi Cloud Kubernetes Architecture
Enterprises adopt kubernetes multi cloud architecture for resilience, scalability and infrastructure flexibility. However, success requires a unified operating model that abstracts infrastructure, allowing developers to focus on code while maintaining a consistent posture across all environments.

A. Building Kubernetes Environments That Prevent Vendor Lock-In
The goal of multi-cloud is to treat cloud providers as interchangeable utility companies. To achieve this, the architecture must strictly adhere to upstream Kubernetes standards and avoid proprietary gravity.
- Open-Source Pluggability: Use open-source Container Network Interfaces (CNI) like Cilium or Calico and Container Storage Interfaces (CSI) that aren’t tied to a specific provider’s storage API.
- Abstraction Layers: Leverage platforms like Anthos, Tanzu or Rancher to provide a consistent management plane. These tools act as a wrapper that ensures the K8s experience is the same whether you’re in an AWS region or a private data center.
- Infrastructure as Code (IaC): Use tools like Terraform or Pulumi to define infrastructure in a provider-agnostic way, ensuring that Spinning up a cluster is a repeatable, code-driven event rather than a manual console exercise.
B. Designing High Availability Infrastructure Across Multiple Cloud Providers
High availability within kubernetes multi cloud architecture requires specialized engineering across multiple cloud providers. A resilient architecture must account for the reality that the network is unreliable.
- Global Server Load Balancing (GSLB): You need a DNS-level or global load balancing solution (like Cloudflare or Akamai) that can intelligently route traffic to the healthiest cluster based on real-time latency and availability metrics.
- The Data Consistency Challenge: Real HA requires synchronized state. This often involves using distributed databases (like CockroachDB or YugabyteDB) that can handle split-brain scenarios and maintain consistency across high-latency cross-cloud links.
- Automated Failover: If a primary provider suffers a catastrophic outage, the system should be able to shift workloads to a secondary provider without human intervention or significant data loss.
C. Creating Standardized Kubernetes Operations Across Distributed Teams
Operational drift is one of the biggest challenges in managing kubernetes multi cloud architecture at enterprise scale when one team manages AWS and another manages GCP using different scripts and manual processes, technical debt accumulates rapidly.
- GitOps as the Source of Truth: Implementing GitOps (using ArgoCD or Flux) ensures that the desired state of all clusters is stored in a single Git repository. If a cluster’s configuration changes manually, GitOps automatically reverts it to match the code.
- Standardized CI/CD: Build pipelines should be agnostic of the destination. A developer should be able to push code and have it deployed to any cluster in the fleet using the same set of helm charts and deployment manifests.
- Unified RBAC: Use a centralized identity provider (like Okta or Ping) mapped to Kubernetes Role-Based Access Control (RBAC) so that permissions are consistent across the entire organization.
D. Ensuring Security & Compliance Across All Clusters
Security and visibility are often the first operational gaps in a poorly managed kubernetes multi cloud architecture. A security-first architecture ensures that your perimeter doesn’t become a sieve.
- Zero Trust with Service Mesh: Using a service mesh like Istio or Linkerd allows you to enforce mutual TLS (mTLS) for all cross-service communication, regardless of which cloud those services live in.
- Policy-as-Code: Use Open Policy Agent (OPA) or Kyverno to enforce compliance rules (e.g., no public load balancers, only pull images from private registries) globally across every cluster.
- Centralized Observability: You cannot jump between CloudWatch and Azure Monitor during an outage. Enterprises need a centralized Single Pane of Glass (using Prometheus, Grafana and an ELK stack) that aggregates logs and metrics into one unified view.
E. Why Scalability Depends More on Architecture Than Cloud Selection
A common myth in kubernetes multi cloud architecture is that cloud infrastructure automatically provides infinite scalability. In reality, the cloud only provides the capacity; your architecture provides the capability.
- De-coupled Microservices: If your application is a distributed monolith where every service is tightly coupled, scaling up in Azure will likely break a dependency in AWS. True scale requires asynchronous communication (queues/events) that can handle the latency of multi-cloud environments.
- Resource Quotas and Limits: Scalability is also about cost control. Without strict resource quotas and Horizontal Pod Autoscaling (HPA) tuned to the specific performance profiles of the underlying VMs, a scaling event can quickly turn into a financial disaster.
- The Architecture is the Foundation: You can build a shack or a skyscraper on the same plot of land. The cloud is just the land; your Kubernetes architecture is the blueprint that determines how high you can actually go.

Major Technical Challenges in Multi Cloud Kubernetes Architecture
Navigating the multi-cloud landscape is a high-stakes balancing act. For a business leader, the goal isn’t just to run on multiple clouds, it’s to ensure that the infrastructure doesn’t become a drain on capital and human resources.

1. Cross-Cloud Networking & Service Discovery
The Challenge: Standard networking tools are designed for single-provider environments. When your services live in different clouds, they become blind to one another, requiring complex manual routing to communicate.
The Business Impact: Significant performance lag for your customers and Egress Sticker Shock’s hidden fees for moving data between clouds that can gut your profit margins.
The Strategic Pivot: Shift toward a Unified Service Fabric. This abstracts the network layer so your applications communicate as if they are in the same room, drastically reducing latency and simplifying global scaling.
2. Management of CI/CD Across Different Ecosystems
The Challenge: Every cloud provider has its own deployment language. Managing separate release pipelines for AWS, Azure and GCP creates a fragmented workflow.
The Business Impact: Release Paralysis. Your time-to-market slows down because updates have to be manually verified across different environments, increasing the risk of shipping bugs to production.
The Strategic Pivot: Implement a Provider-Agnostic Delivery Model. By centralizing the deployment logic, you ensure that a feature release is a push once, deploy everywhere event, maintaining a consistent user experience globally.
3. Security Policy Fragility
The Challenge: Security protocols that work on AWS do not automatically translate to Azure or GCP. A single oversight in how one cloud handles Public Access can leave your entire database exposed.
The Business Impact: Catastrophic brand damage and legal liability. In a multi-cloud setup, the attack surface is much larger and a single security gap can lead to a total data breach.
The Strategic Pivot: Adopt Global Policy Governance. Instead of fixing security cloud-by-cloud, you establish a universal security umbrella that automatically enforces compliance and encryption across every cluster you own.
4. The Blind Spot Observability Problem
The Challenge: Traditional monitoring tools provide a siloed view. When a system crash occurs, your team has to log into three different consoles to find the root cause.
The Business Impact: Skyrocketing MTTR (Mean Time To Resolution). Every minute your system is down while engineers hunt for logs across clouds is lost revenue and eroding customer trust.
The Strategic Pivot: Establish a Single Pane of Glass Transparency. You consolidate all telemetry into one executive dashboard, allowing your team to identify and fix bottlenecks before they affect the end-user.
5. Infrastructure Cost Spirals
The Challenge: Kubernetes multi cloud architecture environments often suffer from Shadow IT, where redundant resources are provisioned and forgotten but the billing continues.
The Business Impact: Massive Cloud Bloat. Without granular visibility, you may find yourself paying for 40% more infrastructure than your application actually requires to run efficiently.
The Strategic Pivot: Deploy Dynamic Resource Optimization. This involves real-time scaling that shrinks your infrastructure footprint during low-traffic periods, ensuring your cloud spend matches your actual business growth.
6. Disaster Recovery Complexity
The Challenge: Maintaining a real-time hot backup across different cloud providers is technically grueling. Data synchronization often fails due to the differences in how providers handle storage.
The Business Impact: A false sense of security. Many businesses realize their backup plan doesn’t work only when a primary cloud goes offline, leading to permanent data loss or days of downtime.
The Strategic Pivot: Design for Active-Active Resilience. Rather than a simple backup, you build a system where workloads shift seamlessly between clouds. If one provider fails, your business stays online without the customer ever noticing a glitch.
Why Hiring Kubernetes Experts Internally Is Difficult
Hiring Kubernetes experts internally is difficult because multi-cloud Kubernetes skills are rare and highly competitive. For growing businesses, this talent gap can slow scalability, increase operational risks and delay product delivery.
The Bottom Line for Business Leaders: Building a multi-cloud Kubernetes team from scratch is essentially starting a second company within your company. The question isn’t just Can we hire them? but Can we afford the time it takes to find, train and keep them?

1. The Talent Deficit in Kubernetes & Multi-Cloud Expertise
The Reality: There is a global shortage of engineers who understand the intersection of Kubernetes, network architecture and multi-provider security. Most DevOps resumes represent proficiency in a single cloud, not the ability to build bridges between them.
The Business Risk: Hiring a mid-level engineer for a senior-level multi-cloud role leads to Architectural Debt. You end up with a system that works today but breaks the moment you try to scale or add a second provider.
2. Why Single-Cloud Experience Is No Longer Enough
The Reality: Mastering AWS (EKS) does not make an engineer an expert in Azure (AKS) or Google Cloud (GKE). Each environment has unique networking quirks and storage behaviors.
The Business Risk: Relying on a single-cloud expert to build a multi-cloud system often results in Cloud Mirroring where the team tries to force AWS logic onto GCP, leading to massive inefficiencies and performance bottlenecks.
3. The Hidden Cost of Internal Upskilling
The Reality: Transitioning a standard software team into high-level Kubernetes operators takes 6 to 12 months of intensive, non-productive training time.
The Business Risk: While your team learns on the job, your infrastructure remains stagnant. The opportunity cost of delayed features and system instability during this learning curve often far exceeds the cost of hiring outside experts.
4. 24/7 Burnout in Distributed Infrastructure
The Reality: Multi-cloud infrastructure never sleeps. Managing clusters across different time zones and providers requires a Follow the Sun support model that most internal teams aren’t equipped to handle.
The Business Risk: High turnover. When your best engineers are woken up at 3:00 AM to fix a cross-cloud networking glitch, they eventually burn out and leave, taking all the institutional knowledge of your complex setup with them.
5. Infrastructure Delays and Talent Gaps
The Reality: Infrastructure projects rarely fail because of a lack of tools; they fail because there aren’t enough hands on keyboards with the right experience to execute the plan.
The Business Risk: Your growth stalls. If it takes three months to find a qualified engineer just to start a migration, your competitors who leveraged an existing, expert team have already captured the market.
Best Practices for Multi-Cloud Kubernetes Architecture Design
Successful multi-cloud execution depends on removing the unique friction of individual providers to create a cohesive environment. These standards ensure your infrastructure remains a strategic asset, providing the portability, security, and automated resilience required to protect your long-term technological investment.

1. Standardizing Infrastructure With GitOps and IaC
The Operational Standard: Every piece of infrastructure, from clusters to networking must be defined in code using tools like Terraform or Pulumi and managed through Git.
The Business Value: Disaster resilience and auditability become significantly stronger because if an entire cloud region goes down, you can quickly recreate your entire environment within minutes.
The Scalability Factor: Rapid global deployment becomes possible because using code allows you to replicate your entire business environment across new geographical regions in hours instead of months, helping businesses enter new markets faster than the competition.
2. Building Cloud-Agnostic Deployment Pipelines
The Operational Standard: CI/CD pipelines must be decoupled from provider-specific tools. Your code should be blind to whether it is landing on AWS, Azure or GCP.
The Business Value: Market agility gives businesses the flexibility to shift operations between cloud providers quickly if pricing changes or a new region delivers better performance and lower latency.
The Competitive Edge: Reduced vendor dependency allows businesses to keep their pipelines cloud-agnostic, avoiding the high cost of re-engineering applications if a provider increases pricing or deprecates a critical service.
3. Using Service Mesh for Secure Cross-Cluster Communication
The Operational Standard: Implement a service mesh (like Istio) to handle identity and encryption at the application level.
The Business Value: Zero-trust security ensures that data remains encrypted while moving between clouds, reducing the risk of mid-transit interception and unauthorized access.
The Innovation Benefit: Simplified microservice management enables developers to focus on building features faster instead of handling complex service-to-service communication, helping teams reduce development time and improve scalability.
4. Centralizing Monitoring, Logging and Incident Response
The Operational Standard: Aggregating all telemetry into a single, provider-independent dashboard.
The Business Value: Reduced downtime helps teams achieve a faster Mean Time to Recovery (MTTR) because engineers spend less time context switching and more time resolving issues efficiently.
The Financial Insight: Data-driven decision making becomes easier with centralized logging, allowing businesses to identify underperforming cloud services, improve accountability and optimize for the best price-to-performance ratio.
5. Implementing Policy-Driven Security Across Clouds
The Operational Standard: Use Policy-as-Code (like OPA) to enforce rules globally.
The Business Value: Automated compliance helps eliminate human error by ensuring the system automatically prevents any non-compliant infrastructure from being created.
The Legal Safeguard: Contractual confidence comes from automated policy enforcement, enabling businesses to confidently meet security standards like SOC 2 or HIPAA, which are often required for securing high-value enterprise contracts.
6. Designing Clusters Around Workload Placement Strategy
The Operational Standard: Intelligent placement of workloads based on data proximity, cost or local data residency laws.
The Business Value: Optimized performance and compliance ensure users are served from local data centers, improving speed while helping businesses avoid potential regulatory penalties and compliance risks.
The Efficiency Driver: Cost-aware routing allows businesses to run compute-intensive workloads in the most cost-effective cloud regions while keeping user-facing services in high-performance locations, helping maximize user experience and reduce operational costs.
7. Automating Scaling and Resource Optimization
The Operational Standard: Utilizing cross-cloud autoscalers that look at both performance metrics and real-time spot-instance pricing.
The Business Value: Efficient capital allocation ensures businesses only pay for the exact amount of compute power required, reducing waste and improving cost efficiency.
The Growth Stabilizer: Capacity on demand ensures infrastructure can scale instantly across multiple clouds during sudden traffic spikes, helping businesses avoid downtime and prevent failures caused by rapid growth or viral demand.
8. Building Disaster Recovery and Failover into Architecture
The Operational Standard: Moving from Backup to Active-Active or Warm Standby architectures where data is continuously replicated.
The Business Value: Business continuity ensures that even if one cloud provider experiences a complete outage, operations continue with only a temporary performance impact instead of a full system blackout.
The Brand Protection: Customer trust retention becomes stronger when multi-cloud failover keeps services always available, helping businesses avoid downtime, protect their reputation and build a brand known for reliability and resilience.
Why Companies Are Turning to Kubernetes Staff Augmentation
The move to Kubernetes staff augmentation is a strategic response to a market bottleneck. Leading organizations are choosing specialized partners to replace Trial and Error infrastructure with immediate, battle-tested results.

1. The Velocity Gap
The Problem: Internal teams often face a steep learning curve, leading to Development Stagnation where infrastructure hurdles delay your product launch.
The Advantage: Instant technical maturity gives businesses immediate access to production-ready expertise, helping teams avoid costly mistakes and move directly from planning to execution much faster.
2. The Hiring Bottleneck
The Problem: Finding a senior Kubernetes engineer can take 3–6 months, often ending in expensive bidding wars that inflate your company’s overhead.
The Advantage: On-demand talent injection helps businesses bypass lengthy recruitment cycles by quickly onboarding specialized experts within days instead of waiting months for the right hire, enabling teams to meet critical deadlines faster.
3. Resource Elasticity
The Problem: Infrastructure needs are rarely permanent. A full-time hire is a fixed cost that can become a burden once the initial multi-cloud migration is complete.
The Advantage: Agile headcount management allows businesses to scale engineering teams based on project demands, expanding during major growth phases and reducing overhead during maintenance to keep costs aligned with actual needs.
4. Risk Mitigation in Expansion
The Problem: Multi-cloud complexity is the leading cause of silent security gaps and massive cost overruns during business growth phases.
The Advantage: Expert oversight acts as a safeguard by helping Kubernetes specialists identify critical architectural risks, such as weak cross-cloud security or poor data routing, before they cause costly outages or business disruptions.
5. The Generalist vs. Specialist ROI
The Problem: Generalist DevOps engineers spend significant time researching new tools, essentially learning on your company’s time and budget.
The Advantage: Automation-first engineering ensures cloud infrastructure is not just managed but fully automated, helping businesses build self-healing systems that require less manual intervention and reduce long-term operational costs.
The Executive Summary
| Traditional Internal Hiring | Kubernetes Staff Augmentation |
| Time-to-Start: 3–6 Months | Time-to-Start: 1–2 Weeks |
| Knowledge: Broad but provider-specific | Knowledge: Deep, multi-cloud mastery |
| Cost Model: Fixed salary + benefits + equity | Cost Model: Flexible, project-based ROI |
| Outcome: High risk of Learning on the job | Outcome: Predictable, high-speed execution |
How IdeaUsher Provides Vetted Kubernetes Developers
At IdeaUsher, we don’t just provide staff; we provide a specialized infrastructure engine. We bridge the gap between complex cloud requirements and business-ready execution by deploying developers who have been rigorously vetted for the specific demands of multi-cloud Kubernetes environments.
1. Access to Elite DevOps and SRE Specialists
The Problem: Most companies struggle to find the right balance of high-level strategy (Architects) and day-to-day reliability (SREs).
The Advantage: We provide a tiered talent pool from our 250+ niche experts whether you need an Architect to design a three-cloud failover system or an SRE to ensure 99.9% uptime, we deploy the exact profile required for your project’s maturity level.
2. Multi-Cloud Expertise Across AWS, Azure and Google Cloud
The Problem: Multi-cloud projects often stall because the team is only expert in one provider, leading to configuration errors in the others.
The Advantage: Our developers are vetted for their ability to handle EKS, AKS and GKE simultaneously. We treat cloud providers as a unified resource pool, ensuring your application remains portable and high-performing regardless of where it is hosted.
3. Designing Scalable CI/CD and Automation Pipelines
The Problem: Manual deployments are the first source of system outages and developer burnout.
The Advantage: We build automated pipelines using GitOps (ArgoCD/Flux). This means your team focuses on writing features while the infrastructure handles the testing, staging and global rollout automatically and safely.
4. Enterprise-Grade Security and Governance Policies
The Problem: In a multi-cloud setup, maintaining consistent security policies is nearly impossible without advanced automation.
The Advantage: We implement Policy-as-Code (OPA/Kyverno) that acts as an automated compliance officer. This ensures that every developer on your team follows your security and encryption standards (GDPR, HIPAA, SOC2) without needing constant supervision.
5. Centralized Observability and Performance Monitoring
The Problem: You cannot manage what you cannot see. Fragmented monitoring leads to slow incident response times and missed performance bottlenecks.
The Advantage: We consolidate your logs and metrics into a single pane of glass. You gain an executive-level view of your system’s health, cost and performance across every cloud provider in real-time.
6. High Availability, Failover and Disaster Recovery Architecture
The Problem: Many businesses have a backup plan that has never been tested, creating a false sense of security.
The Advantage: We design active-active architectures where your traffic is distributed across providers. If one provider experiences an outage, your traffic seamlessly shifts to another, keeping your revenue stream uninterrupted.
The IdeaUsher Commitment
| Capability | Our Standard | Your Result |
| Vetting Process | Hands-on technical testing + Cloud certifications | Low-risk, high-output engineering teams |
| Architecture | Provider-agnostic & Upstream K8s compliant | No vendor lock-in; total platform freedom |
| Security | Zero-Trust & Automated Policy enforcement | Audit-ready infrastructure from Day 1 |
| Support | Proactive SRE & Monitoring | Maximum uptime and peace of mind |
What IdeaUsher’s Kubernetes Developers Actually Deliver
IdeaUsher transforms complex cloud requirements into high-performance engines. Our vetted experts deliver more than just code; they provide a scalable, resilient and secure infrastructure foundation that empowers your business to deploy faster, minimize operational risks and maintain a competitive edge globally.
1. Infrastructure Assessment and Multi-Cloud Architecture Planning
We analyze your current digital footprint to identify bottlenecks and design a tailored roadmap. Our architects ensure your multi-cloud strategy aligns with your budget, performance goals and long-term scalability requirements.
- Strategic Zero-Waste Planning: We identify and eliminate redundant resources during the audit phase, ensuring your capital is invested only in infrastructure that directly supports your growth.
- Future-Proof Architectural Blueprints: Our designs prioritize Upstream standards to prevent vendor lock-in, giving you the freedom to migrate workloads between AWS, Azure and GCP as pricing fluctuates.
2. Kubernetes Cluster Design and Cross-Cloud Networking Setup
Our engineers build the skeletal structure of your container environment. We establish seamless, encrypted communication channels between disparate providers, ensuring your services operate as one unified, high-speed system across the globe.
- Unified Global Connectivity: We remove cloud silos by creating a flat network architecture, allowing your microservices to communicate securely across different providers with ultra-low latency.
- High-Availability Regional Distribution: By designing clusters across multiple geographic zones, we ensure your application remains accessible to users even if a major cloud provider experiences a localized regional outage.
3. Container Orchestration and Deployment Automation
We replace manual, error-prone workflows with sophisticated automation. Our team implements GitOps and CI/CD pipelines that handle the heavy lifting of testing, staging and deploying your software updates globally.
- Accelerated Market Velocity: Automation reduces deployment cycles from days to minutes, allowing your business to pivot based on customer feedback and market trends with unprecedented speed.
- Predictable, Error-Free Releases: By removing human intervention from the deployment process, we drastically lower the risk of downtime caused by configuration mistakes or manual oversights.
4. Security Hardening and Compliance Configuration
Security is baked into every layer of our delivery. We implement zero-trust protocols and automated governance to protect your proprietary data and ensure you meet strict industry regulatory standards.
- Automated Regulatory Compliance: We utilize Policy-as-Code to ensure your infrastructure always meets HIPAA, GDPR or SOC2 standards, keeping your business audit-ready without manual effort.
- Ironclad Data Perimeters: Our developers implement advanced encryption and identity management, ensuring that only authorized services and users can access your most sensitive business intelligence.
5. Kubernetes Cost Optimization and Resource Governance
We treat your cloud budget as a priority. Our developers implement granular tracking and automated scaling to ensure your infrastructure footprint and your monthly bill remains as lean as possible.
- Aggressive Cloud Bill Reduction: Through intelligent resource tagging and spot-instance utilization, we typically help our clients realize immediate and significant savings on their monthly operational expenditure.
- Executive Financial Transparency: We provide clear dashboards that show exactly which services are driving costs, allowing for data-driven decisions on where to scale or cut back.
6. Monitoring, Incident Management and Reliability Engineering
We provide total visibility into your system’s health. Our SRE specialists build proactive alerting systems that identify and resolve potential issues before they ever impact your end-users or your revenue.
- Proactive System Resilience: Instead of reacting to crashes, our systems identify performance trends like memory leaks and resolve them automatically before an outage can occur.
- Rapid Incident Resolution: When anomalies occur, our centralized logging ensures your team finds the root cause in minutes, drastically reducing the financial impact of system downtime.
7. Ongoing Scaling, Maintenance and Infrastructure Modernization
Infrastructure is not a one-and-done project. We provide continuous support to ensure your Kubernetes environment evolves alongside your business, integrating the latest technologies and maintaining peak performance levels.
- Continuous Platform Innovation: We keep your clusters updated with the latest stable Kubernetes versions and security patches, ensuring you always have access to the latest industry-standard features.
- Frictionless Capacity Scaling: As your user base grows, we dynamically adjust your architecture to handle the increased load, ensuring your platform remains fast and reliable during periods of rapid expansion.
In House vs Staff Augmentation for Kubernetes Projects
Choosing between an internal hire and an external specialist is a trade-off between ownership and velocity. For high-stakes Kubernetes deployments, the cost of waiting often outweighs the perceived benefits of a permanent headcount.
1. Recruitment Time and Specialized Kubernetes Access
Hiring experienced Kubernetes professionals internally is slow and competitive, while staff augmentation provides immediate access to specialized multi-cloud expertise.
- The In-House Metric: 120+ days to find, vet and onboard a senior Kubernetes architect.
- The Augmentation Reality: On-demand access. You bypass the recruitment funnel and gain immediate access to a pre-vetted engineer with deep multi-cloud experience.
- Strategic Outcome: You start the project next week, not next quarter.
2. Infrastructure Delivery Speed and Deployment
Internal teams often face deployment delays, whereas Kubernetes specialists accelerate delivery with proven automation frameworks and deployment strategies.
- Internal Hiring: Deployment often stalls as the team navigates the steep Kubernetes learning curve, leading to Development Drift.
- Staff Augmentation: Immediate Architectural Maturity. Specialists arrive with battle-tested automation templates and CI/CD blueprints ready for deployment.
- Strategic Outcome: You hit your product launch deadlines with a production-ready environment that is stable from Day 1.
3. Internal Hiring vs. Staff Augmented Experts Cost
The primary mistake entrepreneurs make is comparing an agency’s hourly rate to an employee’s base salary. The table below exposes the Hidden 40%, the actual cost of maintaining a specialized internal headcount.
| Expense Category | In-House Senior Engineer (Annual) | IdeaUsher Specialist (Annual) |
| Base Compensation | $165,000 | $96,000 – $120,000 (Flat Rate) |
| Benefits & Insurance | $24,750 (Health, 401k, etc.) | $0 (Included) |
| Payroll Taxes (FICA/FUTA) | $12,622 | $0 (Included) |
| Equity & Sign-on Bonus | $15,000 (Amortized) | $0 |
| Recruitment & Referral Fee | $25,000 (One-time avg.) | $0 |
| Hardware & SaaS Licenses | $5,000 | $0 |
| Training & Certifications | $4,500 | $0 (Pre-vetted) |
| TOTAL ANNUAL TCO | $251,872 | $108,000 (Avg) |
The ROI Analysis: Beyond the Bottom Line
Staff augmentation improves ROI by reducing upfront hiring costs, increasing flexibility, and accelerating delivery with specialized Kubernetes expertise.
- The Burn Rate Reality: Hiring in-house requires a significant upfront investment ($25k+ in recruitment and $5k in hardware) before a single line of code is written. With IdeaUsher, your capital goes directly into production output from Day 1.
- The Flexibility Factor: If your project roadmap changes in six months, terminating a high-level internal hire involves severance and potential legal risks. With staff augmentation, you can pivot or pause your resource allocation with a simple 30-day notice.
- The Talent Multiplier: For the cost of one senior in-house hire ($251k), you could essentially deploy two full-time IdeaUsher specialists, doubling your delivery speed for the same budget.
Strategic Outcome: You convert a massive fixed-cost liability into a lean, variable operational expense, allowing you to maintain a healthy runway while scaling your infrastructure.
4. Scalability and Flexibility During Infrastructure
Staff augmentation helps businesses scale infrastructure faster by adding specialized Kubernetes experts exactly when expansion demands increase.
- The Problem: Your in-house team is sized for steady-state maintenance. When it’s time to scale from one cloud to three, they become a bottleneck.
- The Augmented Solution: Burst Capacity. You inject a strike team of specialists to handle the heavy lifting of the expansion and then scale down once the environment is stable.
- Strategic Outcome: Your infrastructure scales in sync with your user growth, never trailing behind it.
5. Long Term Operational Support
Professional Kubernetes support ensures long-term stability through proper documentation, knowledge transfer, and reduced dependency on single internal experts.
- The Risk: If your only internal K8s expert leaves, your infrastructure knowledge disappears, creating a massive single point of failure.
- The Augmented Advantage: Standardized Continuity. Professional partners provide exhaustive documentation and rigorous Knowledge Transfer sessions as part of the delivery.
- Strategic Outcome: Your internal team gains a masterclass in modern K8s operations while the system remains fully documented and maintainable.
6. Why Staff Augmentation Accelerates Kubernetes Transformation
Staff augmentation accelerates cloud-native transformation by letting internal teams focus on innovation while specialists handle complex infrastructure operations.
- The Problem: Many internal transformations become permanent maintenance loops where no new features are built.
- The Solution: Decoupling Innovation from Maintenance. Augmentation handles the complex plumbing of the cloud, allowing your core developers to stay focused on high-value product features.
- Strategic Outcome: You achieve a Cloud-Native state faster, with a higher degree of security and lower architectural debt.
The Executive Verdict: If your goal is long-term general maintenance, hire in-house. If your goal is competitive scaling, risk mitigation and rapid market entry, staff augmentation is the superior business move.
Real Use Cases for Multi-Cloud Kubernetes Architecture
Theoretical benefits become tangible business results when Kubernetes is deployed across multiple clouds. By distributing workloads strategically, organizations solve the modern challenges of global latency, rigid regulatory environments and the massive computational demands of the current artificial intelligence and data-driven era.
1. SaaS Platforms Scaling Across Multiple Geographic Regions
Global SaaS providers use multi-cloud to bypass regional outages and place data closer to users. This strategy ensures always-on service availability even if a major cloud provider experiences a backbone failure.
Global Example: Snowflake utilizes a multi-cloud cross-cloud snowgrid architecture across AWS, Azure and GCP. This allows their SaaS data platform to offer seamless data replication and failover across different cloud vendors globally.
2. Fintech Applications Requiring High Availability and Compliance
Fintechs leverage multi-cloud to meet strict data sovereignty laws and ensure 24/7 transaction processing. By splitting workloads, they avoid concentration risk, a primary concern for UK and US financial regulators.
Global Example: Delio transitioned to a multi-cloud Kubernetes setup across AWS and Azure. This move was specifically designed to handle high-compliance private market transactions while optimizing costs and ensuring zero-downtime availability for international clients.
3. AI Workloads Demanding Distributed Kubernetes Compute Infrastructure
Training Large Language Models requires massive GPU clusters. AI companies use Kubernetes to cloud burst, moving heavy training jobs to whichever provider (CoreWeave, AWS or Lambda) has available high-end H100/B200 chips.
Global Example: Anthropic manages its massive Claude AI model training by distributing compute workloads across multiple specialized cloud infrastructures, ensuring they can scale inference and training regardless of single-provider hardware shortages.
4. Ecommerce Platforms Managing Seasonal Traffic Surges Across Clouds
Retailers face massive traffic spikes during events like Black Friday. Multi-cloud Kubernetes allows them to scale front-end clusters into secondary clouds to handle overflow traffic that would overwhelm a single provider.
Global Example: Wayfair has modernized its infrastructure using Kubernetes to manage bursty traffic. By decoupling their services, they can scale horizontally across different cloud environments to maintain site speed during high-velocity holiday sales events.
5. Enterprises Migrating From Legacy Infrastructure to Kubernetes
Large-scale enterprises use Kubernetes as a bridge during digital transformation. They maintain sensitive legacy data on-premises or in private clouds while scaling customer-facing applications in public clouds like AWS or Azure.
Global Example: Volkswagen Group utilizes a multi-cloud Kubernetes strategy to power its Automotive Cloud. This allows them to integrate legacy manufacturing data with new, cloud-native vehicle-to-everything (V2X) services across diverse global regions.
Signs Your Business Needs External Kubernetes Architecture Experts
A high-performance infrastructure should accelerate business growth rather than serve as a bottleneck. When operational friction begins to stall market momentum or impact the bottom line, it indicates that the underlying architecture requires specialized expertise to reach enterprise-level stability.
1. Rising Downtime and Infrastructure Instability
Frequent service interruptions are often symptoms of architectural flaws. If a platform feels fragile, it indicates that the current setup cannot reliably handle the complexities of modern multi-cloud traffic or automated failover requirements.
- Unexplained Service Interruptions: The application experiences short, recurring periods of unavailability that require manual intervention to restore, leading to a loss of customer trust and potential revenue.
- Degraded Performance During Peak Hours: The system becomes noticeably sluggish as user traffic increases, indicating that the infrastructure is not properly configured to distribute the load effectively across different cloud regions.
2. Slower Product Releases Due to Operational Complexity
When a development team spends more time managing server issues than building new product features, the infrastructure has become a liability. External experts can streamline these operations to restore business agility and speed.
- Extended Deployment Timelines: New software updates take days or weeks to reach the market because the internal process for moving code from development to production is manual and error-prone.
- Frequent Release Failures: A high percentage of new feature launches result in system bugs or crashes, forcing the team to spend valuable time on rollbacks instead of forward-looking innovation.
3. Increasing Cloud Costs Without Clear Resource Governance
Uncontrolled cloud spending is a direct drain on profit margins. Rising monthly invoices that do not correlate with business growth suggest a lack of the technical oversight required to optimize resource consumption.
- Unpredictable Monthly Invoices: Cloud bills fluctuate significantly without a clear link to user activity, making it difficult for the finance team to forecast operational expenses or set accurate budgets.
- Idle Resource Waste: Large portions of the cloud budget are spent on server capacity that remains active even during low-traffic periods, because the system lacks the intelligence to scale down automatically.
4. Security and Compliance Challenges Across Distributed Clusters
Managing data across multiple clouds increases the risk of exposure. Without expert-level hardening, a business remains vulnerable to security gaps that can lead to permanent brand damage and severe legal consequences.
- Failed Compliance Readiness: The business is unable to bid on enterprise-level contracts because the current infrastructure lacks the documented security controls required to pass SOC2, HIPAA or GDPR audits.
- Visible Data Vulnerabilities: Internal reviews reveal that sensitive information is moving between cloud providers without consistent encryption or strict access controls, creating a high-risk environment for a data breach.
5. Internal Teams Struggling to Manage Scaling and Reliability
When core engineers are perpetually focused on firefighting infrastructure emergencies, the risk of high-value talent turnover increases. Specialized support provides the relief needed to stabilize the system and protect the team’s productivity.
- Stalled Product Roadmap: Long-term business goals are consistently delayed because the engineering team is overwhelmed by the day-to-day demands of maintaining a complex and unstable cloud environment.
- Inability to Support Rapid Growth: The infrastructure lacks the foundation to handle a sudden surge in users, causing the system to fail exactly when a marketing campaign or business expansion is most successful.
Why IdeaUsher Is the Strategic Partner for Kubernetes Design
IdeaUsher serves as a premier technical catalyst, transforming complex cloud-native challenges into scalable business advantages. By combining deep architectural mastery with a global delivery footprint, we ensure your infrastructure becomes a high-speed engine for innovation, reliability and long-term market leadership.
A. Proven Experience in Kubernetes Engineering
With a track record of over 1,000 successfully delivered projects across 100+ industries, IdeaUsher brings a decade of specialized expertise in orchestrating complex container environments. Our engineers utilize battle-tested methodologies to ensure maximum system resilience.
- Multi-Cloud Mastery: Our architects possess deep technical proficiency across AWS, Azure and Google Cloud, ensuring seamless workload portability and the elimination of restrictive vendor lock-in.
- Automation-First Philosophy: We implement advanced CI/CD and GitOps workflows that replace manual overhead with zero-touch deployments, significantly reducing the risk of human-driven configuration errors.
- Cloud-Native Optimization: Beyond basic migration, we re-engineer applications to leverage the full power of Kubernetes, resulting in improved resource utilization and superior application performance metrics.
B. Access to Vetted Developers
Finding high-level Kubernetes talent is a major hurdle for growing enterprises. IdeaUsher solves this by providing immediate access to our roster of 250+ niche experts, including ex-MAANG engineering talent, ready to integrate into your workflow.
- Rigorous Talent Selection: Every developer undergoes a comprehensive multi-stage vetting process that tests for high-level problem-solving, architectural knowledge and proficiency in modern DevOps toolchains.
- Accelerated Onboarding: We bypass traditional 90-day hiring cycles with an industry-leading 24-hour onboarding process, allowing your project to maintain momentum and hit critical product launch deadlines.
- Cultural and Technical Alignment: Our engineers are trained to integrate directly into your internal teams, adopting your communication tools and project management styles for a frictionless partnership.
C. Faster Infrastructure Modernization
Modernizing a legacy system can be a high-risk endeavor. IdeaUsher specializes in in-flight modernization, upgrading your foundations while ensuring your day-to-day business operations remain completely stable.
- Non-Disruptive Migrations: We utilize sophisticated Blue-Green and Canary deployment strategies to move workloads to Kubernetes, ensuring zero downtime for your customers during the transition.
- Security-First Engineering: We embed enterprise-grade security (GDPR, HIPAA, SOC2) into the modernization process, using AES-256 encryption and zero-trust architectures to protect your proprietary logic.
- Legacy-to-Cloud Bridging: Our experts design hybrid architectures that allow new Kubernetes clusters to communicate securely with existing legacy databases, maintaining data integrity throughout the transformation.
D. Flexible Staff Augmentation Models
Business growth is rarely linear. IdeaUsher offers highly elastic engagement models designed to align perfectly with your current project phase, offering up to 70% cost savings compared to traditional in-house hiring.
- Elastic Resource Allocation: Our models allow you to scale your technical headcount up for massive cloud migrations and lean down for ongoing maintenance, protecting your monthly burn rate and ROI.
- Global Delivery Footprint: With strategic hubs in the USA, UK, Canada, UAE and India, we offer 24/7 global support and a follow-the-sun development model for rapid, around-the-clock execution.
- Flexible Engagement Models: Choose between dedicated Squad teams for long-term initiatives or specific technical consultants to solve niche architectural challenges, providing the precision your budget requires.
E. End-to-End Support
A successful Kubernetes journey requires a partner who stays the course. IdeaUsher provides comprehensive lifecycle support, ensuring your infrastructure is not only built correctly but evolves with your business.
- Strategic Architecture Audit: We begin every partnership with a deep-dive assessment of your current stack, identifying hidden trapdoors and providing a clear roadmap for enterprise-grade scalability.
- Proactive SRE Management: Our Site Reliability Engineers provide 24/7 monitoring and proactive incident response, resolving potential bottlenecks like memory leaks before they impact your end-user experience.
- Continuous Resource Optimization: We maintain a rigorous focus on FinOps, continuously tuning your cluster configurations to ensure you achieve the highest possible performance for the lowest possible cloud spend.
Conclusion
Successfully managing kubernetes multi cloud architecture across distributed environments requires more than basic DevOps management. Multi cloud Kubernetes success depends on specialized execution, strong automation and deep infrastructure expertise. The long term value of working with experienced Kubernetes experts includes faster deployments, reduced operational risks and better scalability. IdeaUsher helps enterprises build scalable and resilient multi cloud infrastructure by providing vetted Kubernetes specialists who optimize performance, security and cloud operations for long-term business growth.
Common Queries
Q.1. How does multi-cloud Kubernetes prevent downtime?
A.1. Distributed architectures eliminate single points of failure by spreading workloads across several providers. If one cloud experiences a major outage, traffic automatically shifts to another, ensuring the application remains accessible.
Q.2. What are the technical challenges of scaling Kubernetes across clouds?
A.2. Synchronizing distinct networking models, storage classes, and security APIs across different environments creates significant complexity. Establishing a unified service fabric is necessary to manage these fragmented systems and prevent operational chaos.
Q.3. How to reduce multi-cloud Kubernetes costs?
A.3. Implementing granular resource governance and automated scaling ensures cloud spending matches actual demand. Proactive monitoring identifies idle resources and optimizes workload placement, preventing the financial waste often associated with unmanaged scaling.
Q.4. How to manage data residency compliance with multi-cloud Kubernetes?A.4. Yes, distributed architectures allow businesses to host data and workloads in specific geographic regions to comply with local laws like GDPR. This granular control ensures that sensitive information never leaves the physical borders of a required jurisdiction.






