




Key Takeaways
- Businesses are adopting enterprise RAG architectures to connect AI with internal knowledge, improving accuracy and access to company information.
- A successful RAG system combines data ingestion, vector databases, retrieval pipelines, and LLM orchestration to deliver reliable responses.
- Advanced techniques like hybrid retrieval, chunking, embeddings, and re-ranking help reduce hallucinations and improve answer quality.
- Organizations use RAG to enhance customer support, knowledge management, and enterprise search while maintaining governance.
- How Idea Usher can help businesses build enterprise RAG architectures with secure data integration, optimized retrieval pipelines, vector databases, and enterprise AI solutions.
Organizations once believed that better AI performance required larger models, extensive fine-tuning, and higher infrastructure spending. However, real-world adoption has shown that many AI failures stem from models lacking access to the right business context rather than from a lack of intelligence. More and more businesses are adopting enterprise RAG architectures because they allow AI systems to access current company knowledge, policies, documents, and operational data without the need for constant retraining. This not only improves the accuracy and relevance of AI-generated responses but also makes it easier to scale AI across teams and departments.
Over the years, we’ve helped businesses implement enterprise RAG architectures that connect AI with internal knowledge and business workflows. Using technologies like vector databases and semantic search, we’ve built systems that make AI responses more relevant and useful in real-world operations. In this guide, we’ll share what goes into a successful enterprise RAG architecture and the key considerations for building one that can grow with your business.
Enterprise AI Adoption Is Creating Demand for RAG Systems
According to Research and Markets, the global Retrieval-Augmented Generation market is expected to rise from USD 1.96 billion in 2025 to USD 40.34 billion by 2035. This rapid growth shows that businesses are moving beyond basic AI experiments and focusing on systems that can deliver dependable results. Enterprise leaders want AI that understands their documents, policies, and business knowledge in real time.

Source: Research and Markets
RAG architecture makes this possible by connecting AI models to trusted company data, helping organizations improve accuracy while getting more value from their AI investments. Major companies are already leading the charge by integrating these advanced frameworks directly into their core operations:
- Walmart: Uses proprietary AI platforms to help corporate employees quickly search, summarize, and synthesize massive internal HR policies and benefits documentation.
- Morgan Stanley: Deployed an internal AI assistant powered by OpenAI to help financial advisors instantly access and analyze insights from a vast library of research reports and investment data.
However, off-the-shelf language models cannot achieve this level of utility on their own. To deliver true value, an AI system needs direct access to trusted enterprise knowledge. This reality makes Retrieval-Augmented Generation a critical infrastructure layer for any production deployment. Without RAG, a massive AI investment is essentially a powerful engine without any fuel.
Grounding AI in Internal Data
The phase of AI experimentation is officially over. Today, companies require systems that securely retrieve information from internal documents, legacy databases, and live business applications in real time. Generic AI models lack access to private corporate data, which limits their usefulness for specialized business tasks. RAG solves this fundamental limitation.
By connecting the AI directly to secure enterprise knowledge sources, RAG bridges the gap between general intelligence and specific business context. Investors who fund the development of these systems are tackling a massive pain point for corporations that want to operationalize their private data assets safely.
Accurate and Governed AI Demand
Enterprise adoption hinges on three non-negotiable pillars:
- Trust: Employees and customers must rely on the output.
- Compliance: Data must remain secure and adhere to strict privacy laws.
- Accuracy: The system cannot afford to guess or make up facts.
Standard language models are notorious for hallucinations, which can cause severe legal and financial liabilities for a business. RAG drastically minimizes these risks.
By pulling facts directly from verified corporate records before generating a response, RAG delivers highly accurate, context-aware answers. Building a robust RAG platform positions you directly in front of an enterprise market that is eager to pay for safety, control, and reliability.

Why Does Enterprise AI Need RAG Architecture?
Deploying raw artificial intelligence in a corporate environment usually results in a mismatch between advanced technology and practical utility. Standard foundational models excel at general reasoning but fall short when handling proprietary business operations. To bridge this gap, businesses are turning to Retrieval-Augmented Generation to make AI systems functional, secure, and contextually aware.
The Limits of Standalone LLMs
Standard large language models are frozen in time. They only know what they were trained on during their initial development phase. If a team asks a base model about a financial report generated yesterday, the model will fail or guess. Base LLMs lack real-time awareness and cannot access private files.
For an investor, backing a standalone LLM platform means selling an expensive tool that quickly gets outdated. Enterprises cannot run a business on stale public data. They need dynamic answers.
Why Enterprise Knowledge Is Hard to Access
Corporate data is notoriously messy. It sits trapped inside isolated silos like secure cloud drives, old SQL databases, and internal communication channels. Most AI tools cannot read these formats safely or respect user permission levels. This fragmentation creates a massive headache for executives. A proper enterprise platform must connect these dots securely without leaking sensitive payroll or legal data to unauthorized staff members.

How RAG Reduces Hallucinations at Scale
When an AI model does not know an answer, it often invents a plausible lie. In the corporate world, these hallucinations lead to bad strategy decisions and compliance penalties. RAG acts as an open-book exam for the AI:
- Search: The system finds the exact paragraph needed from your secure files.
- Verify: It hands that specific text to the LLM.
- Respond: The AI generates an answer based strictly on that proven fact.
This verification process keeps the output accurate and auditable even when processing millions of documents across global offices.
Business Impact of Context-Aware AI
Context changes everything for a company’s bottom line. When an AI understands exact customer histories or proprietary product specifications, workflows accelerate dramatically. Investing in RAG architecture means funding a platform that delivers clear operational ROI. It turns raw AI capabilities into a practical tool that protects corporate liability and drives efficiency.
| Business Function | Before RAG | After RAG |
| Customer Support | Agents manually search wikis for minutes | AI drafts accurate answers instantly |
| Legal Review | Hours spent browsing old contracts | Crucial clauses located in seconds |
Core Components of an Enterprise RAG Architecture
Building a commercial-grade RAG architecture requires a robust blueprint. It is not just about connecting an LLM to a database. Investors must understand that a scalable enterprise platform relies on a sophisticated multi-layered pipeline designed to handle complex data, strict security rules, and heavy user traffic smoothly.
1. Data Ingestion and Knowledge Integration
Before an AI can answer questions, it has to collect information from across the company. This layer serves as the intake system for the entire platform. It connects to enterprise data sources such as document repositories, databases, CRM systems, internal wikis, and cloud applications to gather relevant information.
- Enterprise Data Connectors: A system must sync automatically with corporate tools like SharePoint, Salesforce, and secure cloud storage. Without reliable pipelines, the AI quickly becomes useless.
- Document Parsing and Normalization: Corporate files arrive as PDFs, Word documents, and spreadsheets. This process strips out messy styling to isolate the raw text so the system can understand it clearly.
- OCR for Scanned Content: Many legacy companies store invoices and legal contracts as images. Optical Character Recognition converts these scanned files into readable text for the AI.
- Metadata Extraction and Enrichment: The platform tags files automatically with key details like author, creation date, and department. This tagging helps the retrieval system filter information faster during a search.
- Indexing and Knowledge Preparation Layer: Once data enters the system, it must be structured so that algorithms can scan it in milliseconds.
- Document Chunking Strategies: Large documents are broken into smaller pieces. Instead of feeding a 100-page manual to the AI, the platform chops it into logical paragraphs to ensure precise answers.
- Embedding Generation: Machine learning models convert those text pieces into mathematical vectors. This transformation allows the system to understand the actual meaning of words rather than just looking for exact keyword matches.
- Vector Database Architecture: Specialized databases like Pinecone, Milvus, or Qdrant store these mathematical vectors. They are designed to search through billions of data points instantly.
- Hybrid Search Indexing: The system merges traditional keyword search with vector search. This combination ensures the platform catches exact product codes as well as broader conceptual ideas.
2. Query Understanding and Retrieval
When a user asks a question, this layer translates that input into a precise search instruction. It understands the intent behind the query and converts it into a format optimized for retrieval systems. Advanced query processing can also expand, refine, or rewrite the request to improve search accuracy and ensure the most relevant information is retrieved from enterprise knowledge sources.
| Component | Role in the Retrieval Layer |
| Query Rewriting and Expansion | Refines vague or incomplete user questions into clearer search queries, improving the chances of finding the most relevant internal documents. |
| Vector and Hybrid Retrieval | Searches enterprise knowledge using both semantic similarity and keyword matching to identify the most relevant content chunks. |
| Re-Ranking Models | Evaluates and reorders retrieved results so the highest-quality and most relevant information appears first. |
| Retrieval Quality Optimization | Removes duplicate, outdated, or irrelevant content and prepares a cleaner set of context data for the language model. |
3. Context Processing and Generation
This layer acts as the final packaging step where the retrieved data meets the language model to generate an answer.
- Context Assembly and Compression: The platform bundles the top text chunks together and shrinks them to fit the AI token limits without losing meaning.
- Prompt Engineering Framework: The system wraps the data in strict instructions, telling the LLM to only answer using the provided facts.
- LLM Response Generation: The core language model reads the packaged instructions and writes a natural, cohesive response.
- Citation and Grounded Responses: Every claim the AI makes includes a direct link to the source file. This allows users to verify the source instantly.
4. Governance and Security Layer
For enterprise clients, security is a major selling point. This layer protects sensitive information and ensures compliance. A regular employee should never see AI answers derived from restricted executive payroll files.
- Permission-Aware Retrieval: The platform checks user permissions in real time. The search engine only pulls files that the specific user has official clearance to view.
- PII Protection and Data Redaction: The system detects sensitive elements like Social Security numbers or credit cards and masks them before data ever reaches an external AI model.
- Audit Logging and Compliance: The platform keeps a detailed trail of who asked what, which files were accessed, and what the AI answered to satisfy corporate compliance audits.
- Enterprise Access Controls: The system integrates smoothly with identity providers like Okta or Azure AD to manage user authentication safely.
5. Monitoring and Evaluation Layer
An enterprise platform cannot run blind. Operators need tools to verify that the system is working accurately over time. Continuous monitoring helps teams track retrieval quality, response accuracy, latency, and system performance across different use cases.
| Evaluation Metric | What It Measures | Why It Matters |
| Groundedness | Is the answer backed by actual files? | Eliminates hallucinations |
| Answer Relevance | Did the AI actually answer the question? | Ensures user satisfaction |
| Latency | How long did the response take? | Drives platform adoption |
- RAG Evaluation Frameworks: Automated tools like Ragas or TruLens continuously score the quality of the system retrieval and generation phases.
- Observability and Performance Tracking: Dashboards monitor processing times and API errors to ensure the software remains fast and reliable under heavy user loads.
- User Feedback Loops: Simple thumbs-up and thumbs-down buttons let employees flag bad answers, which helps developers continuously improve the system.
- Drift Detection and Continuous Improvement: The system alerts administrators when new company terminology or changes in data patterns start degrading the accuracy of the AI model.
6. Infrastructure and Orchestration Layer
This final layer acts as the digital engine room, tying all the components together into a single cohesive application. It manages how data, retrieval systems, language models, security controls, and user interfaces interact during every request. A strong application layer ensures a seamless user experience while maintaining reliability, scalability, and governance across the entire enterprise AI platform.
| Component | Role in the Enterprise RAG Platform |
| Workflow Orchestration Engines | Frameworks such as LangChain and LlamaIndex coordinate the flow of data between ingestion, retrieval, reasoning, and response generation components. |
| Model Routing and Load Balancing | Directs queries to the most appropriate AI model based on complexity, helping optimize performance while controlling inference costs. |
| Caching and Latency Optimization | Stores responses and frequently accessed data so common queries can be answered faster without repeated retrieval and generation steps. |
| Scalable Deployment Architecture | Uses cloud-native infrastructure and container orchestration platforms like Kubernetes to support high availability and automatically scale resources as demand grows. |
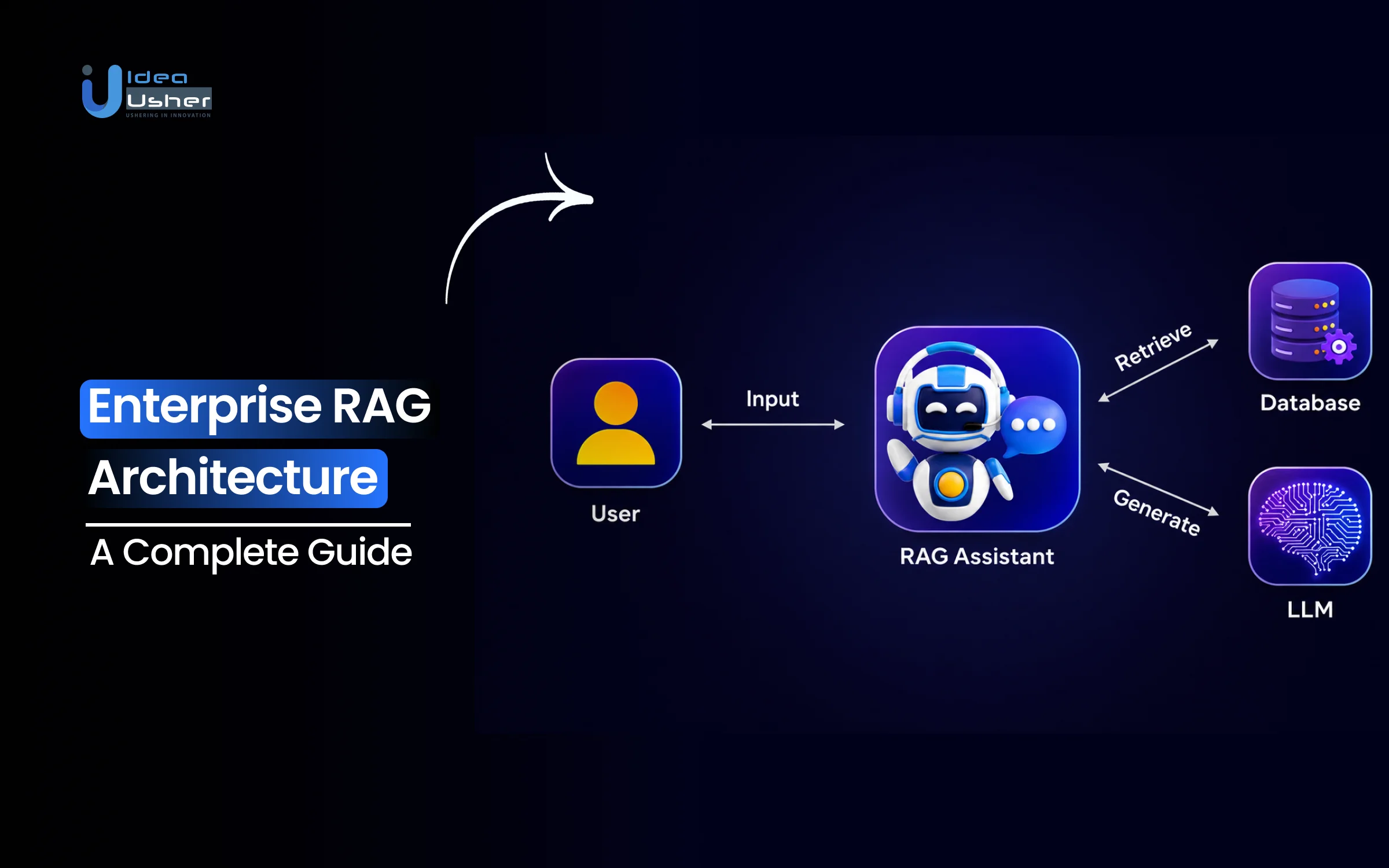
Understanding Enterprise RAG Pipelines
A RAG pipeline enables AI systems to access trusted company knowledge whenever users need answers. Instead of depending only on pre-trained information, the AI can retrieve relevant business data in real time and generate responses based on current enterprise knowledge. For organizations, this means better accuracy, greater trust in AI outputs, and a stronger foundation for deploying AI across critical business operations.
Production-Ready RAG Architecture
A production-ready system must balance two separate engineering workflows that operate simultaneously. The offline track processes corporate documents in the background so the system data is always current. The online track handles live user requests, searching the index and generating answers in real time.
For true enterprise viability, these tracks require tight observability tools and strict governance protocols. This validation loop ensures the system operates reliably under compliance audits.
Choosing the Right Vector Database
Selecting the core database architecture is a major financial decision that influences platform running costs and computing speed. Different enterprise use cases require distinct data technologies. Analyzing factors like operational complexity and structural integration before deploying the database layer protects capital investments from expensive infrastructure migrations later on.
| Database | Main Strength | Best Used For |
| Pinecone | Fully managed cloud service | Fast deployment with minimal server management |
| Qdrant / Milvus | High-performance open source | Private cloud setups with massive scalability needs |
| Weaviate | Native keyword and vector mixing | Object-heavy data and complex enterprise knowledge graphs |
| pgvector | Integrates with existing PostgreSQL | Cost-efficient scaling without buying new software |
| Elasticsearch | Powerful exact-match tracking | Systems requiring perfect precision for serial codes |
RAG or Fine Tuning: Which Approach Fits Your Use Case?
Investors often ask whether they should build a search-based RAG platform or simply fine-tune an AI model on corporate data. These two approaches serve entirely different purposes. Fine-tuning changes how an AI model speaks and behaves, while RAG gives the model an open-book library to read from. Understanding the difference prevents costly architectural mistakes.
When RAG Is the Better Choice
Retrieval-Augmented Generation is the clear winner when a business deals with proprietary knowledge and information that updates constantly. If your company policies or product prices change daily, fine-tuning a model every night is financially impossible and technically inefficient.
RAG handles strict compliance requirements perfectly because it provides source-backed responses. When the AI answers a question, it cites the exact document it used. This clear audit trail allows compliance officers to verify the output instantly, which removes the risk of untraceable AI hallucinations.
When Fine-Tuning Delivers Better Results
Fine-tuning is the right choice when an organization needs a model to adopt a highly specialized behavior, tone, or specific formatting style. Instead of teaching the model new facts, you are training it to perform a specific task exceptionally well.
- Medical Coding: Teaching a model to output raw medical data into rigid, standardized clinical formats.
- Customer Support Tone: Training an AI to perfectly mimic a brand unique voice and emotional intelligence style across millions of chat logs.
- Code Generation: Optimizing a smaller model to write software syntax inside a highly custom corporate programming framework.
Why Modern Enterprise AI Combines Both
The most advanced enterprise applications do not choose between these technologies. They combine them into a unified system. High-performance platforms use fine-tuning to optimize the model behavior and use RAG to feed that model accurate real-time data. This hybrid approach allows companies to deploy smaller, highly efficient open-source models that run faster and cost less.
| Component | Strategic Value | Core Function |
| Fine-Tuning | Behavior Layer | Fixes the tone, enforces formatting, and optimizes logic |
| RAG Architecture | Knowledge Layer | Injects live facts, checks compliance, and cites sources |
By fine-tuning a small model for behavior and using RAG for knowledge, you build a scalable product that delivers high-tier accuracy without the massive cloud compute bills of larger models.
Chunking and Embeddings: The Hidden Drivers of RAG Accuracy
Deploying a successful platform requires looking past the user interface. The real value lies in how data is processed under the hood. If the system chops up text poorly or uses weak mathematical representations, the AI will miss critical facts. At IdeaUsher, we design custom enterprise RAG architecture with high-precision engineering to ensure your platform delivers flawless performance for corporate clients.
Chunking Impacts Quality
Documents cannot be fed to an AI all at once. They must be broken into digestible pieces called chunks. The strategy we choose to divide this text directly dictates whether the AI finds the exact answer or completely misses the context. Different enterprise datasets require specialized chunking methodologies to maintain accuracy:
- Fixed-Size Chunking: Breaking text by a strict character count. It is fast but can cut sentences in half, causing the system to lose vital context.
- Semantic Chunking: Analyzing the text to split documents only when the topic naturally changes. This ensures whole ideas stay intact.
- Hierarchical Chunking: Creating small child chunks for precise searching while linking them to larger parent summaries to preserve the big picture.
- Structure-Aware Chunking: Respecting the original layout of files like legal contracts or tables so structural meaning is never lost.
Our engineering teams analyze your specific business data assets first. We then build custom chunking pipelines tailored to your files, ensuring the system retrieves highly relevant answers every time.
Choosing Embedding Models
An embedding model translates raw corporate text into mathematical coordinates so the system can calculate conceptual relationships. Selecting the right model shapes the long-term scalability and operational cost of your platform. When we build enterprise platforms, we evaluate several technical dimensions:
- Vector Dimensionality: Higher dimensions catch deep nuances but increase database storage costs. We balance precision with infrastructure spend.
- Multilingual Support: We ensure global enterprises can search documents seamlessly across different languages.
- Domain Performance: Financial and medical platforms require models trained on specialized vocabulary to understand industry jargon.
- Upgrade Strategies: Replacing an embedding model requires re-indexing your entire database. We architect your system with modular wrappers to make future upgrades smooth and cost-effective.
Silent Failures in RAG
Enterprise AI success depends heavily on trust and answer quality. Even the most advanced language model can produce incorrect responses if it retrieves poor or irrelevant information. This is why leading organizations invest in continuous evaluation, retrieval testing, and quality monitoring. Strong validation processes help ensure that AI responses remain accurate, reliable, and grounded in trusted enterprise data as the system evolves.
Advanced Retrieval Strategies for Enterprise RAG
Basic search methods often fail when applied to complex corporate data environments. If a platform relies solely on standard algorithms, users will not find what they need. At IdeaUsher, we build advanced retrieval layers that ensure your system extracts information with clinical precision, helping your application stand out as a premium market solution.
1. Hybrid Retrieval Boosts Accuracy
Relying on just one search method limits system performance. True enterprise accuracy requires blending two distinct approaches into a single unified engine. We integrate classic BM25 keyword search with modern vector search to deliver superior results:
- Exact Matching: BM25 catches specific product codes, part numbers, and legal IDs perfectly.
- Contextual Understanding: Vector search captures the underlying meaning of a query even if the user uses different phrasing.
By fusing these technologies, our engineering team ensures that the AI never misses exact corporate terminology while still understanding natural human intent.
2. Query and Metadata Optimization
Users rarely write perfect search prompts. To fix this, our architectures optimize queries behind the scenes before they ever touch the database. We implement advanced techniques like Hypothetical Document Embeddings to improve relevance. The system generates a fake ideal response first, then uses that draft to search for actual matching corporate files.
Additionally, we use metadata filtering to instantly narrow searches by department, date, or region. This approach handles multilingual requests effortlessly while satisfying strict corporate compliance and access control standards.
3. Re-Ranking and Agentic Retrieval
The first round of data retrieval often pulls in a lot of unnecessary noise. To refine these results, we implement a secondary defense layer using cross-encoder re-ranking models. For highly complex requests, we deploy iterative agentic workflows. If a user asks a multi-part question, the system treats it as a series of steps.
| Retrieval Phase | Action | Business Benefit |
| Initial Search | Scans millions of files instantly | Ensures no data is missed |
| Re-Ranking | Scores the actual relevance of each chunk | Cuts out noise to save API costs |
| Agentic Iteration | Resolves multi-step questions automatically | Handles complex analytical tasks |
It looks up the first fact, analyzes it, and uses that new knowledge to run a second search. Partnering with us means gaining access to these advanced engineering capabilities, allowing you to deliver an AI assistant that tackles sophisticated business challenges with complete autonomy.
Build Enterprise RAG Architecture with Idea Usher
Investing in artificial intelligence requires the right execution partner to transform a concept into a secure, high-value asset. We construct robust platforms that satisfy the strict technical and operational mandates of global organizations. By combining enterprise-grade performance with ironclad data security, we build digital solutions that command market authority and protect your capital investment.

Design Systems for Scale
A software product must remain performant when dealing with massive datasets. When we build retrieval systems, we ensure they process millions of documents without experiencing latency spikes or system failures. Our engineering strategy centers on structural stability:
- Dynamic Pipelines: We build agile data ingestion paths that clean and index incoming corporate data instantly.
- Vector Database Optimization: We fine-tune database configurations to keep lookups fast and reduce infrastructure maintenance costs.
- Security Architecture: We embed access-aware governance models directly into the framework so sensitive files stay protected.
By managing the entire orchestration layer, we deliver a stable environment capable of managing intense enterprise workloads with complete reliability.
Seamless Corporate Integration
An AI platform becomes far more useful when it can access the systems employees already rely on every day. At IdeaUsher, we connect enterprise tools and data sources into a single AI ecosystem so information can flow where it is needed most. This helps teams find answers faster, reduces manual work, and allows the AI to deliver insights based on real business knowledge rather than isolated datasets.
Launch Production Platforms Faster
Building advanced software from scratch can take months of expensive trial and error. We accelerate your development timeline by leveraging our deep technical background and proven delivery frameworks. We minimize your time-to-market while keeping a sharp focus on measurable business value.
| Engineering Strength | What We Bring | Investor ROI |
| Deep Experience | 500,000+ development hours | Avoids costly architectural mistakes |
| Elite Talent | Ex-MAANG engineering experts | Top-tier code quality and system design |
| Optimization Focus | Continuous performance tuning | Lowers monthly cloud and API expenses |
Conclusion
Enterprise RAG architecture is becoming the foundation of reliable business AI. By combining large language models with real-time access to enterprise knowledge, organizations can deliver more accurate answers, improve productivity, and reduce the risks associated with outdated or incorrect information. As AI adoption continues to grow, businesses that invest in a well-designed RAG architecture will be better positioned to scale AI initiatives and create lasting value from their data.
Things to Know About Enterprise RAG Architecture
A1: Traditional chatbots rely mainly on pre-trained knowledge, while Enterprise RAG retrieves information from internal documents, databases, knowledge bases, and business applications in real time before generating answers. This enables more accurate and context-aware responses for employees and customers. It also ensures AI outputs reflect the latest business information available.
A2: Organizations use RAG to improve knowledge management, automate support operations, enhance employee productivity, reduce AI hallucinations, and provide secure access to company information through conversational interfaces. As AI adoption grows, businesses need systems that can access trusted data sources. RAG bridges the gap between powerful LLMs and enterprise knowledge repositories.
A3: A typical enterprise RAG stack includes data ingestion pipelines, document processing, chunking, embedding generation, vector databases, retrieval systems, re-ranking models, LLM orchestration, security controls, and monitoring tools. Each layer plays a critical role in determining answer quality and system reliability. Together, these components create a scalable and production-ready AI platform.
A4: No. RAG significantly reduces hallucinations by grounding responses in retrieved information, but retrieval errors, outdated data, or poor indexing can still lead to inaccurate answers if not properly monitored. Continuous evaluation and retrieval optimization are essential for maintaining accuracy. Strong governance practices further improve trust in AI-generated outputs.





