 (+971) 8007 4267
(+971) 8007 4267 (+91) 946 340 7140
(+91) 946 340 7140 (+1) 628 432 4305
(+1) 628 432 4305

Video has quietly shifted from a simple content format to an operational infrastructure within modern companies, as every department now relies on it for consistent communication. Once expansion begins, a single recording must support multiple regions and languages, and without automation, teams would repeatedly re-record the same message, quickly driving costs up.
Multilingual AI presenter software can systematically convert a verified recording into controlled language variants while preserving voice identity and delivery precision. This approach can significantly reduce executive workload and stabilize production timelines across markets.
Over the years, we’ve developed many multilingual AI presenter solutions powered by multimodal generative AI architectures and neural rendering pipelines. With this hands-on experience, we are using this blog to break down the practical steps required to develop scalable, enterprise-ready multilingual AI presenter software.
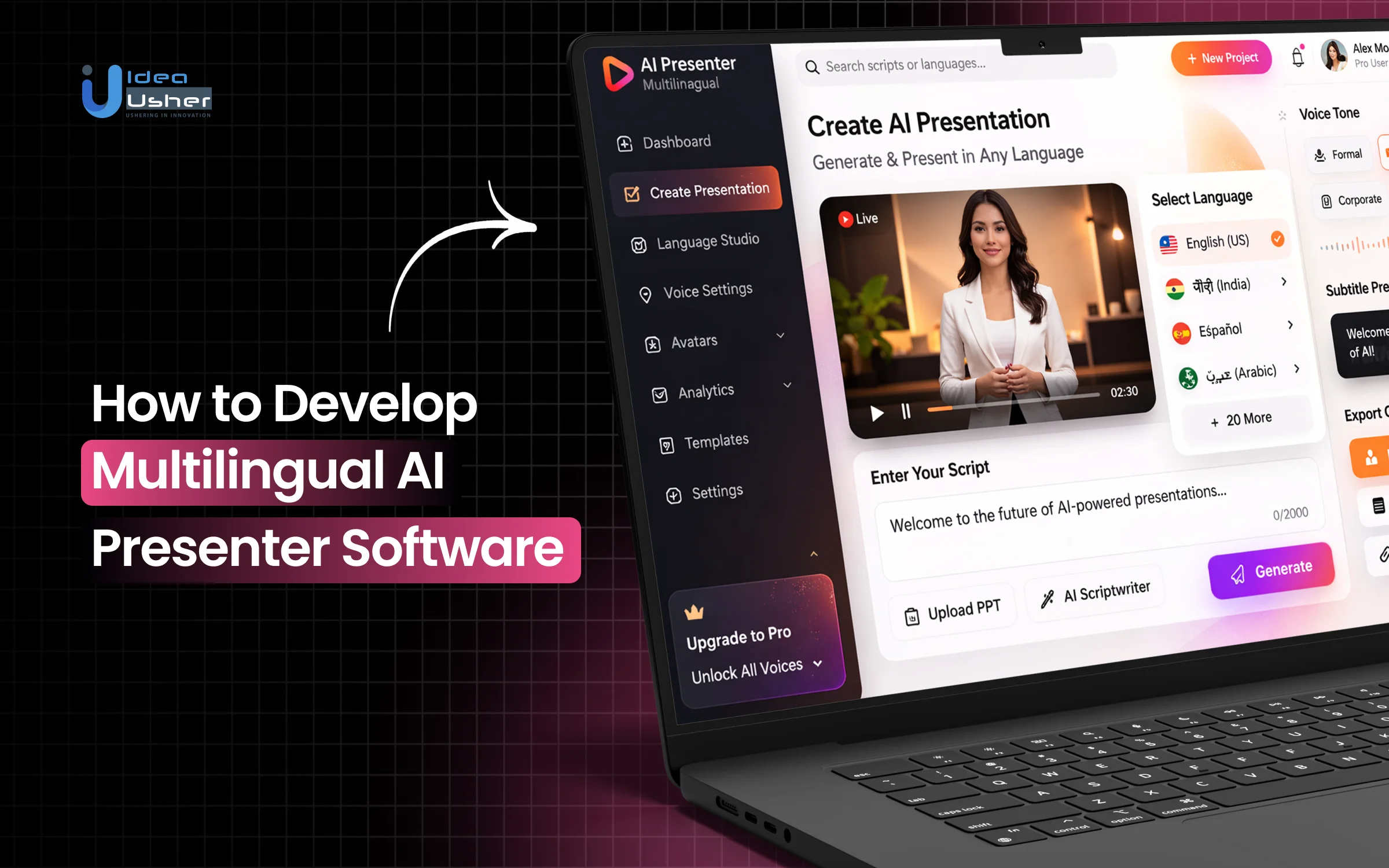
What Is Multilingual AI Presenter Software?
Multilingual AI presenter software is a generative AI application that creates lifelike digital humans capable of delivering video content in multiple languages. Unlike traditional video production, which requires a physical studio, cameras, and human actors, this software uses Neural Networks to synthesize a presenter’s appearance and voice.
The “multilingual” aspect is the engine’s ability to take a single script, translate it, and then reanimate the digital presenter so their lip movements and facial expressions perfectly match the phonetic sounds of the new language, all without needing to re-film.
How AI Presenter Platforms Work
The “magic” behind these platforms is actually a highly coordinated pipeline of different AI models working in sequence:
- Natural Language Processing (NLP): The software analyzes your text script for context, tone, and intent. If you’re using the multilingual feature, a translation layer converts the text while preserving local idioms.
- Text-to-Speech (TTS) & Voice Cloning: A sophisticated audio model generates a voiceover. Modern systems use Neural TTS to ensure the cadence, pitch, and “breathiness” sound human rather than robotic.
- Lip-Sync Generation (Wav2Lip/Audio-to-Video): This is the most critical step. The AI analyzes the audio frequencies and maps them to specific mouth shapes (visemes). It then warps the digital avatar’s face pixels to match the audio.
- Rendering: The background, clothing, and movements are synthesized into a final video file, often in a fraction of the time it would take to render a traditional 3D animation.
Difference Between AI Avatars, AI Presenters, & Virtual Anchors
While these terms are often used interchangeably, they serve different roles in the digital ecosystem:
| Feature | AI Avatar | AI Presenter | Virtual Anchor |
| Primary Use | Personal branding, gaming, or social media. | Explainer videos, corporate training, and ads. | News broadcasting and live event hosting. |
| Interactivity | Often used for 1-on-1 chat or VR. | Usually scripted and linear (one-way). | Designed for high-stakes, broadcast-quality loops. |
| Realism | Can be stylized, 2D, or “cartoonish.” | High-fidelity, often based on real human scans. | Photorealistic; often indistinguishable from humans. |
Why Multilingual Capability Is the Real Competitive Advantage
In a globalized economy, “English-only” is a growth ceiling. Multilingual capability transforms a piece of software from a cool gadget into a strategic powerhouse for three reasons:
- Hyper-Localization at Scale: You can launch a global product marketing campaign in 40+ languages simultaneously without hiring 40 different actors or translators.
- Cultural Trust: Audiences are significantly more likely to engage with content and retain information when it is presented in their native tongue.
- Cost Efficiency: Traditionally, “localizing” video meant expensive dubbing or distracting subtitles. AI presenters eliminate these costs, allowing companies to “speak” to niche markets that were previously too expensive to reach.
Why Businesses Are Investing in Multilingual AI Presenters?
According to Grand View Research, the move toward AI-driven video is no longer a futuristic concept; it is a massive economic engine. The global AI video market, which was valued at approximately $3.86 billion in 2024, is on an explosive trajectory. It is projected to reach a staggering $42.29 billion by 2033, driven by a robust 32.2% CAGR starting in 2025.

Source: Grand View Research
This rapid expansion is driven by a simple reality: traditional video production cannot keep pace with the modern demand for instant, localized, and highly personalized global content.
Global E-Learning and Corporate Training Demand
The e-learning sector is one of the primary drivers of this technology. With the global online learning market projected to hit $400 billion by the end of 2026, organizations are moving away from static text-based modules toward immersive video.
- Scalable Knowledge: Companies with a global footprint use AI presenters to roll out compliance training or product launches to thousands of employees in 50+ countries simultaneously.
- Retention and ROI: Statistics show that video-based e-learning improves information retention by 25% to 60%. By using AI presenters, firms can achieve this at 70% lower costs than hiring traditional film crews and voice actors for every regional office.
- The Human Element: Learners engage more deeply with a face than a narrated slideshow, making AI presenters the go-to tool for HR departments worldwide.
AI Video Localization Market Growth Statistics
The data paints a clear picture of a localization gold rush. Businesses are no longer satisfied with English-only content, and the numbers prove it:
- Market Valuation: The AI video translation and localization market is growing at a CAGR of approximately 25% and is expected to reach nearly $38 billion by 2034.
- Efficiency Gains: AI-driven localization tools have reduced time-to-market for global campaigns by up to 70%.
- Engagement Spikes: Content localized into a viewer’s native language sees a 40% to 50% increase in engagement compared to subtitled English videos.
Industry Use Cases Driving Adoption
Beyond general marketing, four specific sectors are leading the charge in 2026:
EdTech: Educational platforms are using AI presenters to create virtual tutors that speak students’ local dialects in rural or underserved areas, bridging the global literacy gap.
Media and Broadcasting: News outlets now use Virtual Anchors to provide 24/7 breaking news updates in multiple languages, allowing a small local desk to have a global reach.
Enterprise and BFSI: Banks and large corporations use AI avatars to create personalized customer service videos that explain complex financial statements to users in their preferred language.
Healthcare: Hospitals are deploying AI presenters to deliver post-operative care instructions and medical information, ensuring patients, regardless of their primary language, clearly understand their recovery steps.

Core Features of a Multilingual AI Presenter Software
Building a competitive AI presenter platform requires more than just a moving image; it requires a symphony of high-end features that work in tandem to create a “human” experience. To move from a basic animation to a professional-grade tool, the following core features are essential:
1. Real-Time Text-to-Speech
The foundation of any AI presenter is its voice. Modern software must support Neural TTS, which uses deep learning to produce speech that mimics human prosody, rhythm, and emotion.
- Extensive Library: Support for over 100+ languages and dialects is the current industry standard.
- Emotional Range: The ability to toggle between “cheerful,” “serious,” or “empathetic” tones ensures the voice matches the message.
2. AI Lip Sync Engine
This is the most technically demanding feature. The software must use Generative Adversarial Networks to map audio phonemes to visual visemes.
- Dynamic Micro-expressions: Beyond just moving the mouth, the software should simulate natural eye blinking, eyebrow movement, and slight head tilts.
- Zero Latency Mapping: Ensuring the audio and video are perfectly aligned to avoid the “uncanny valley” effect.
3. Voice Cloning Control
For brand consistency, businesses often want their AI presenter to sound like a specific person.
- Personalized Cloning: Users can upload a short human-voice sample to create a digital twin.
- Accent Control: The ability to apply specific regional accents (e.g., British English vs. Australian English) ensures the content feels truly local and relatable.
4. Script and Translation Hub
To streamline the workflow, the software acts as a central hub for content creation.
- One-Click Translation: Integrating APIs like Google Cloud Translation or DeepL allows users to input a script in one language and instantly generate versions in dozens of others.
- Context-Aware Editing: A built-in editor that allows users to manually tweak translations to ensure technical jargon remains accurate.
5. Avatar Customization
Diversity and representation are key to global engagement.
- Hyper-Realistic Models: Created from high-resolution 3D scans of real humans for maximum professional impact.
- Diversity Presets: A wide range of ethnicities, ages, and attire options (from medical scrubs to business suits) to fit any industry.
- Custom Brand Avatars: The option for enterprises to create a unique mascot or “digital spokesperson” exclusive to their brand.
6. Multi-Format Video Export
A tool is only as good as its compatibility with existing workflows.
- High-Definition Output: Support for 1080p and 4K resolutions in MP4 or MOV formats.
- LMS Integration: For the EdTech sector, exporting in SCORM or xAPI formats is vital for seamless integration into Learning Management Systems.
- Alpha Channel (Transparent Background): Allowing users to export the presenter with a transparent background for easy overlaying in professional video editing software like Premiere Pro or Final Cut.
Advanced Capabilities That Differentiate Your AI Presenter Software
To build a category-leading product, you must move beyond simple lip-syncing toward behavioral intelligence. These advanced capabilities transform a digital puppet into a dynamic, context-aware communicator.
1. Emotion-Aware Speech Synthesis
Standard AI voices can often sound “flat.” Advanced software uses Prosody Modeling to inject emotional intelligence into the delivery.
- Contextual Inflection: The AI analyzes the script to detect sentiment—automatically lowering the pitch for serious news or increasing energy for a sales pitch.
- User-Defined SSML: Support for Speech Synthesis Markup Language (SSML) allows creators to manually insert pauses, whispers, or emphasis on specific keywords for a 100% natural performance.
2. Real-Time Live AI Presenter Streaming
The “holy grail” of this technology is moving from pre-rendered video to Live Streaming.
- Low-Latency Rendering: Utilizing powerful GPU-accelerated cloud instances (like NVIDIA A100s/H100s) to render the avatar’s response in under 200ms.
- Interactive LLM Integration: By connecting the presenter to a Large Language Model (like Gemini or GPT-4), the avatar can “listen” to live audience questions and respond verbally and visually in real-time.
3. AI Gesture & Body Movement Generation
A talking head is only half the battle. To be truly convincing, an AI presenter needs to move like a human.
- Non-Verbal Communication: Advanced models generate autonomous hand gestures, head tilts, and shoulder shrugs that correspond to the rhythm of the speech.
- Posture Variation: The ability to switch between a seated “news desk” posture and a standing “keynote” posture, providing visual variety for long-form content.
4. Multilingual Subtitle & Auto-Dubbing Engine
True localization requires a holistic approach to the video frame, not just the audio.
- Dynamic Burn-in: Automatically generating and “burning in” accurate, time-synced subtitles in the target language.
- Global Dubbing Sync: A feature that allows users to upload an existing video of a real human and use AI to “re-face” them, changing their lip movements to match a new translated audio track (Visual Dubbing).
5. Enterprise API Integration
For high-scale business use, the software cannot exist in a vacuum. It must become part of the existing tech stack.
- Personalization at Scale: Through CRM integration (e.g., Salesforce), the software can automatically generate 5,000 unique videos, each addressed to a client by their first name and discussing their specific account details.
- Automated Workflows: API hooks that allow a Content Management System to trigger a vie.g, Salesforce), the software can automatically generate 5,000 unique videos, each addressed to update whenever a text article is published, ensuring news and info stay current without human intervention.
How to Develop Multilingual AI Presenter Software?
We understand that in a globalized economy, a “one-size-fits-all” video strategy is a missed opportunity. That is why we specialize in developing bespoke multilingual AI presenter software tailored specifically to our clients’ unique brand voices, technical ecosystems, and global scaling goals.

We take the complexity of generative AI (lip-syncing, neural TTS, and heavy GPU rendering) and turn it into a streamlined, white-label solution that gives your team the power to speak to the world in 100+ languages with a click of a button.
Here is the exact process we follow to bring your custom AI presenter software to life:
1. Define the Use Case
We start by defining the “Who” and the “Why.” Whether you are an EdTech giant needing 24/7 virtual tutors or a global retailer requiring localized product launches, we map out a UI/UX that fits your specific workflow. We do not just give you a tool; we build a solution that solves your production bottlenecks.
2. Choose the AI Stack
We leverage the most advanced frameworks available in 2026. Our stack typically involves Python for the heavy lifting, React/Next.js for a snappy frontend, and a hybrid of proprietary models and “frontier” APIs. We ensure your software is compatible with NVIDIA’s latest H100/H200 clusters for lightning-fast video generation.
3. Build the Intelligence Layer
We integrate “context-aware” intelligence. This means your AI presenter not only reads words; it understands them. By layering Large Language Models into the backend, we ensure the presenter knows when to sound empathetic during a customer service interaction or high-energy during a marketing pitch.
4. Develop the Voice System
We give your brand a voice that carries across borders. We integrate high-fidelity Neural TTS that supports over 100 languages.
- The Personal Touch: We can develop Custom Voice Cloning features that allow your CEO or a specific brand ambassador to “speak” fluent Mandarin, Spanish, or Arabic while maintaining their distinct vocal DNA.
5. Implement Visual Rendering
This is where our engineering shines. We implement cutting-edge Audio-to-Video (A2V) synchronization. We ensure that every syllable is perfectly matched to realistic mouth movements (visemes) and micro-expressions, such as blinking and head tilts, to bypass the “uncanny valley” and build real human trust.
6. Enable Localization
We do not just translate text; we localize content. Our software includes a dedicated AI Translation Engine that handles technical jargon and cultural nuances. We built in a “Human-in-the-Loop” editor that allows your regional managers to quickly review and tweak scripts before the final render.
7. Design the User Dashboard
We build a sleek, intuitive Command Center. Your team gets a drag-and-drop script editor, an avatar library, and a real-time preview window. No technical degree is required. If they can write an email, they can create a world-class multilingual video.
8. Deploy and Scale
Finally, we handle the heavy lifting of infrastructure. We deploy your software on Auto-Scaling GPU Cloud instances (AWS/Azure). Whether you need to render one video a week or 10,000 videos an hour, our architecture grows with your demand, ensuring 99.9% uptime and rapid delivery.
Technology Stack Required for Multilingual AI Presenter Development
At IdeaUsher, we do not just pick tools; we engineer a high-performance ecosystem. Our philosophy is built on Character Continuity and Cinematic Fidelity. We treat your AI presenter as a “digital cast member” that maintains the same lighting, outfit, and personality across thousands of videos.
To achieve this, we have curated a specialized tech stack that balances cutting-edge research with battle-tested production reliability.

1. AI & ML Frameworks
We utilize a dual-framework approach to ensure we can move from experimental features to stable deployment without friction.
- PyTorch (Production Share 55%+): Our primary environment for rapid experimentation. We use it to build custom neural layers that refine micro-expressions like pupil dilation and skin tension during speech.
- TensorFlow Extended (TFX): For our enterprise clients, we use TFX to manage production pipelines, ensuring that the models serving your videos are monitored for “drift” and maintain consistent latency under heavy loads.
2. Intelligence Layer
A presenter is only as good as their understanding of the script. We move beyond simple translation to Context Engineering.
- Frontier Models (GPT-4o / Claude 3.5 / Gemini 1.5 Pro): We use these “Reasoning Engines” to analyze the emotional subtext of your script. If a script is mourning, the AI adjusts the facial “muscle” weights to look somber; if it is celebrating, it adds a subtle “eye smile” (Duchenne smile).
- Agentic Workflows: We use LangChain or Temporal to create autonomous agents that can research facts, translate them with cultural nuance, and then “brief” the video generator, all in a single automated stream.
3. Audio & Speech
We give your brand a voice that carries weight in any language.
- ElevenLabs & OpenAI Realtime: Our go-to for high-fidelity, multilingual speech. These models provide industry-leading “prosody” (the rhythm and melody of speech), ensuring the AI doesn’t sound like a machine.
- Zero-Shot Voice Cloning: We can create a digital twin of your spokesperson’s voice using as little as 15 seconds of audio, allowing them to speak 70+ languages while keeping their unique vocal identity.
4. The Visual Engine
To bypass the “uncanny valley,” we combine generative AI with gaming-grade rendering.
- NVIDIA Audio2Face (Open Source): We leverage NVIDIA’s latest AI-powered facial animation technology to map audio phonemes directly to a 3D facial mesh. This results in incredibly accurate lip-sync and tongue placement.
- Unreal Engine 5.5 (MetaHumans): For the highest tier of realism, we host your presenters as MetaHumans. This allows for cinematic lighting, realistic hair physics, and the ability to “film” your AI presenter from any camera angle.
- Magic Hour & HeyGen APIs: For rapid-turnaround marketing content, we integrate these industry leaders to provide stable, long-form lip-syncing (up to 20-minute scripts) with near-instant rendering.
5. Infrastructure
Video generation is the most resource-heavy task in AI. We ensure your software never lags.
- AWS G5 & P5 Instances: We deploy on NVIDIA H100/H200 GPU clusters to ensure that a 1-minute 4K video renders in seconds, not minutes.
- Google Cloud Vertex AI: We use GCP for projects requiring massive context (like an AI presenter explaining a 500-page manual) and for its superior global fiber network, which powers low-latency live streaming.
- Data Streaming (Confluent/Kafka): We treat video as “live data,” allowing us to update a presenter’s information in real-time—essential for news anchors or live customer support avatars.
How to Train AI Models for Multiple Languages?
Training an AI presenter to be truly multilingual is a leap beyond simple translation. It requires synchronizing auditory patterns with visual cues across diverse linguistic structures. In 2026, the standard has shifted from “generic” models to hyper-localized systems that respect the unique DNA of every language we implement for our clients.
1. Dataset Collection for Multilingual Speech
High-quality output starts with high-quality data. We don’t just “scrape” the web; we curate datasets that capture the “messiness” of real human interaction.
Phonetic Balancing:
We source datasets like Mozilla Common Voice and OpenSLR, ensuring they include every possible phoneme (distinct sound) in the target language.
Diverse Demographics:
To avoid “robotic” consistency, our data includes variations in age, gender, and regional background, recorded in environments ranging from studios to “in-the-wild” public spaces.
Metadata Richness:
Every audio clip is tagged with noise levels, emotional intent, and speaker demographics, allowing us to fine-tune how the AI reacts in different contexts.
2. Accent & Dialect Adaptation Techniques
A “Standard Spanish” accent won’t resonate in Mexico City as well as it does in Madrid. We use advanced adaptation layers to bridge this gap.
Zero-Shot Transfer Learning:
We use models like Fish Speech or CosyVoice 2 to “teach” the AI a new accent using only a few seconds of reference audio.
Acoustic Fine-Tuning:
By training on regional-specific corpora, we adjust the AI voice’s pitch, pace, and “breathiness” to match local speaking habits.
Code-Switching Support:
For modern global audiences, we train our models to handle “Spanglish” or “Hinglish,” ensuring the AI doesn’t glitch when a speaker jumps between languages in a single sentence.
3. Phoneme Mapping & Lip-Sync Optimization
This is where the visual meets the vocal. Different languages require different physical movements of the mouth and tongue.
Viseme Mapping:
We map audio phonemes to visual visemes (the position of the lips and teeth). For example, the “th” sound in English requires a specific tongue placement that doesn’t exist in French; our models are trained to recognize these nuances.
NVIDIA Audio2Face Integration:
We utilize AI-powered facial animation to map audio frequencies directly to a 3D mesh, ensuring the jaw, cheeks, and even the throat move in sync with the sound.
Duration Control:
We use auto-regressive models (such as IndexTTS-2) to ensure the spoken word’s length perfectly matchesthe video frame, avoiding the “speed-up” effect common in poor dubbing.
4. Reducing Translation Bias & Cultural Errors
A literal translation can often be a brsuch as Google Translate, Gemma,and’s biggest nightmare. We implement a “Cultural Safety Net” in our development pipeline.
Context-Aware LLMs:
We use models such as Google Translate, Gemma, and Claude 3.5 to identify honorifics (e.g., the difference between “you” for a friend vs. an elder in Japanese) and ensure they are applied correctly.
Terminology Glossaries:
We “lock in” your brand’s critical terms and legal language before translation begins, preventing the AI from hallucinating or using a competitor’s terminology.
Human-in-the-Loop (HITL) Validation:
For high-stakes content, we route “high-risk” segments to native linguists who score the AI on fluency, naturalness, and cultural appropriateness before the final render.
UI/UX Considerations for AI Presenter Softwares
Building a powerful AI engine is only half the battle; the other half is making that power accessible to a non-technical marketing manager or an HR specialist. At IdeaUsher, our UX philosophy centers on “Reducing the Time to Render.” We design interfaces that strip away the complexity of machine learning, allowing your team to focus on storytelling while the AI handles the heavy lifting.
Here is how we architect the user experience for our enterprise AI platforms:
1. Script-to-Video Workflow Optimization
The journey from a blank page to a finished 4K video should be linear and frictionless. We implement a “Canvas-First” approach that mirrors modern design tools such as Canva and Figma.
- The “Magic” Paste: Our editor automatically parses pasted text, detecting natural break points to suggest scene transitions or slide changes.
- Contextual Suggestions: As a user types, the UI suggests relevant B-roll, icons, or background changes based on the keywords in the script.
- Real-Time Drafts: We use low-resolution “proxy” avatars in the editor so users can see a rough lip-sync instantly without waiting for a full cloud render.
2. Language Switching Interface Design
Managing a global campaign shouldn’t mean managing 50 different project files. We build a “Universal Project” architecture.
- The Multi-Track Editor: Users can view their master English script alongside its translated versions in a split-screen view.
- One-Click Global Sync: A single button lets users “Apply to All,” instantly generating the same video layout across 40+ languages while adjusting each scene’s timing to match the spoken length of that language.
- Visual Flags: We use intuitive iconography and heatmaps to indicate when a translated script might be too long for the current scene, enabling quick edits.
3. Custom Avatar Builder Experience
Creating a digital twin should feel like a premium concierge service, not a technical chore.
- Guided Onboarding: We build a step-by-step “Studio Walkthrough” that guides users through recording their 2-minute training video (lighting, framing, and script) to ensure the highest-quality AI clone.
- The “Wardrobe” Logic: Our UI allows users to swap outfits, hairstyles, and backgrounds for their digital avatar with a simple click-to-apply interface, powered by Stable Diffusion on the backend.
- Identity Verification: To prevent misuse, the builder includes integrated ID verification steps, ensuring only authorized individuals can create a digital likeness of themselves.
4. Enterprise Admin & Role Management
For large organizations, security and collaboration are paramount. We build “Bank-Grade” administrative backends.
- Hierarchical Permissions: Define who can edit scripts, who can approve final renders, and who has the authority to use the “Corporate Voice” or “Executive Avatar.”
- Asset Libraries: A centralized “Brand Kit” where logos, fonts, and approved background music are stored and locked, ensuring every video produced across the company remains on-brand.
- Audit Logs & Usage Analytics: Admins can track which regions are producing the most content, monitor API credit usage, and see exactly who edited a script, providing total transparency for global teams.
Where Multilingual AI Presenter Software Delivers Maximum ROI?
For global enterprises, the transition to AI-generated video is not just a trend; it is a massive cost-saving and revenue-generating strategy. By removing the need for physical studios, local actors, and expensive dubbing houses, businesses are seeing an ROI that traditional production simply cannot match.

1. E-Learning & EdTech Platforms
The education sector is the primary beneficiary of AI video. Traditional course localization takes months; with our software, it takes minutes.
- Global Classroom Expansion: EdTech companies can launch a single course in English and immediately offer it in 50+ languages, opening up markets in Latin America, Asia, and the Middle East simultaneously.
- Tutor Personalization: Platforms can create “Virtual Tutors” that adapt their dialect and tone to the specific student, increasing course completion rates by over 30%.
2. Corporate Training & HR Automation
For companies with thousands of employees worldwide, keeping everyone on the same page is a logistical nightmare.
- Uniform Compliance: Roll out mandatory safety or ethics training globally on the same day. Every employee hears the same message from the same “Corporate Face,” ensuring no details are lost in translation.
- Scalable Onboarding: Automate the welcome process for new hires. An AI presenter can walk a new employee through their benefits package in their native language, reducing the burden on local HR teams.
3. Healthcare Patient Education
Clear communication in healthcare can quite literally be a matter of life and death.
- Multilingual Aftercare: Hospitals use AI presenters to deliver post-operative instructions. A patient who speaks Mandarin can receive a personalized video explaining their medication in Mandarin, ensuring 100% comprehension and reducing readmission rates.
- Informed Consent: Complex medical procedures are explained through friendly, calm AI avatars, making high-stress information easier for patients to digest.
4. Real Estate & Virtual Property Tours
The real estate market is increasingly global, with investors buying property halfway across the world.
- The Multilingual Agent: An AI presenter can act as a 24/7 virtual agent, walking a buyer through a 3D property tour in Arabic, Russian, or English, depending on the viewer’s location.
- Personalized Outreach: Agents can send thousands of “personalized” video follow-ups to leads, addressing each person by name and discussing specific property features in the lead’s primary language.
5. E-Commerce & Product Demonstrations
In the world of online shopping, video is the ultimate conversion tool.
- Localized Social Commerce: Brands can create TikTok and Instagram product demos that feature an AI host speaking the local slang of each target market.
- Mass Personalization: For high-ticket items, e-commerce platforms can generate a custom video for every cart-abandonment email, showing the AI presenter discussing the specific item the customer left behind.
6. Media & Entertainment Industry
Content creators and news outlets are using AI to break the speed-of-light barrier in reporting.
- 24/7 Virtual Newsrooms: News agencies can deploy “Virtual Anchors” to report on breaking news or weather updates around the clock in multiple languages, without the overhead of a full broadcast crew.
- Content Globalisation: YouTube creators and filmmakers use our Visual Dubbing tech to “re-animate” their existing videos, allowing them to speak to a global audience with perfect lip-sync, effectively tripling their ad revenue potential.
Compliance, Ethics & AI Regulations You Must Consider
Building a Multilingual AI Presenter today requires navigating a complex global patchwork of laws that protect individual likeness and ensure digital transparency.
Here are the critical regulatory pillars we integrate into every client project:
1. Voice Cloning Legal Considerations
Voice is now legally recognized as “biometric property” in many jurisdictions. You cannot simply “scrape” a voice to create a clone without a rigorous legal trail.
Explicit Informed Consent:
Under new 2026 statutes like the Digital Creativity Integrity Act in the EU and the ELVIS Act in several U.S. states, you must obtain written, revocable authorization specifically for AI training.
Vocal Personality Rights:
High-profile settlements (such as the 2025 Arijit Singh case) have reinforced that a person’s “vocal DNA” is a protectable asset. Our software includes Digital Rights Management (DRM) to ensure that voices are used only within the scope of their specific license.
Biometric Privacy:
We implement “Privacy by Design,” ensuring that the underlying voiceprints used to generate speech are encrypted and stored separately from user accounts, in compliance with biometric privacy laws.
2. AI Content Disclosure Policies
The “right to know” is now a global standard. It is no longer optional to label AI-generated content; it is a technical requirement for platform hosting.
Mandatory Labeling:
Per the EU AI Act (effective August 2026) and India’s IT Rules Amendment 2026, all synthetic media must be clearly and prominently labeled. Our software automatically “burns in” visual watermarks and includes mandatory audio disclaimers at the start of every generated clip.
Machine-Readable Metadata:
We embed C2PA (Coalition for Content Provenance and Authenticity) metadata into every video file. This “digital fingerprint” stays with the video even after sharing, allowing platforms and users to instantly verify its AI origins.
Three-Hour Takedown Readiness:
New regulations require platforms to remove non-consensual or deceptive “Synthetically Generated Information” within 2 to 3 hours. We build “Emergency Kill-Switches” into our enterprise dashboards so your legal team can instantly de-publish content if a dispute arises.
3. GDPR & Data Protection Requirements
Generating video involves processing sensitive personal data, placing your software directly under the GDPR and the DPDP Act.
Purpose Limitation:
We help you document the specific “purpose” of your AI system, as recommended by the CNIL, to ensure you don’t collect unnecessary biometric data during the training or rendering phases.
The Right to Erasure (Right to be Forgotten):
We architect our databases so that if a user or spokesperson withdraws consent, their “Voice Model” and all associated training data can be completely purged from the system within the 30-day legal window.
Cross-Border Data Flows:
For multinational clients, we utilize Sovereign Cloud deployments. This ensures that a French employee’s biometric voice data never leaves the EU, keeping you compliant with strict data localization requirements
Why Partner with Idea Usher to Develop Multilingual AI Presenter Software?
At Idea Usher, we do not just provide off-the-shelf solutions. We partner with you to build proprietary, high-performance platforms that give your brand a permanent, global voice.
With a track record of delivering next-generation AI solutions across healthcare, EdTech, and enterprise video, we bring the technical depth and strategic vision needed to turn complex generative AI into a seamless user experience.
Our AI Development Expertise
We house a specialized team of AI researchers and engineers who stay ahead of the curve. Our expertise spans the entire generative AI spectrum, including Computer Vision for realistic facial mapping and NLP for nuanced, context-aware translations.
We understand the fine details (such as skin tension during speech and pupil dilation) that distinguish a robotic avatar from a digital human.
End-to-End Product Engineering Approach
We manage the entire lifecycle of your software, from the initial blueprinting of your business requirements to the final deployment on the cloud. Our End-to-End model ensures that your AI engine, frontend dashboard, and backend database are perfectly synchronized. This holistic approach reduces your time-to-market by up to 30%, allowing you to launch and scale faster than the competition.
Custom AI Model Development Capabilities
While many agencies simply “wrap” existing APIs, Idea Usher specializes in building Custom AI Models. Whether you need a proprietary voice clone for your CEO or a custom-trained lip-sync model that handles unique technical jargon, we have the capabilities to train and fine-tune models on your specific datasets. This gives you total IP ownership and a unique brand face that cannot be replicated.
Scalable and Secure Architecture Design
Video rendering is one of the most resource-intensive tasks in modern computing. We architect your platform using Auto-Scaling Cloud Infrastructure (AWS/Azure/GCP), ensuring your software can handle 10 videos or 10,000 without a drop in performance.
- Bank-Grade Security: We prioritize data sovereignty, implementing HIPAA and GDPR-compliant protocols to ensure your sensitive scripts and biometric data remain encrypted and secure.
Post-Launch Support and Optimization
Our partnership does not end at the “Launch” button. AI models require continuous monitoring to maintain accuracy and prevent model drift.
- AIOps and Monitoring: We provide ongoing Monitoring and Optimization services that refine your AI’s performance based on real-world usage and feedback.
- Future-Proofing: As new frontier models emerge (such as the latest iterations of Sora or Gemini), we ensure your platform is updated to leverage the latest tech, keeping your business at the bleeding edge of the industry.
Conclusion
Multilingual AI presenter software is no longer an experimental layer on top of video production, and it is steadily becoming the core communication infrastructure for global enterprises. When architected correctly, it can deliver scalable recurring revenue while enabling international market expansion and clear technological differentiation. With a strong compliance framework and a well-designed multimodal pipeline, businesses can confidently build a category-defining platform that performs reliably at enterprise scale and under regulatory scrutiny.
Looking to Develop a Multilingual AI Presenter Software?
IdeaUsher can help you architect a multilingual AI presenter platform using structured speech-to-speech pipelines and synchronized neural rendering systems.
The team can carefully implement phoneme-aligned lip-sync models and voice-identity preservation layers so the presenter remains consistent across languages.
Why build with us?
- 500,000+ hours of coding experience, we’ve debugged what’s possible
- Ex-MAANG/FAANG developers building at Google, Meta, & Amazon standards
- End-to-end expertise: Neural voice cloning + NeRF avatars + C2PA compliance
- Production-ready: We ship scalable, enterprise-grade systems, not prototypes


FAQs
A1: To build a multilingual chatbot, we integrate a Large Language Model like Gemini with an RAG framework. We use a vector database with multilingual embeddings, allowing the bot to understand a query in one language and find the answer in another. An automated language-detection layer ensures the bot instantly adjusts its response style and cultural tone to match the user.
A2: The three types include simultaneous multilingualism, where a model is trained on multiple languages at once for a shared global understanding; sequential multilingualism, where an AI mastered in one language is later fine-tuned on a second; and receptive multilingualism, where a system can accurately process various languages but is programmed to output in only one specific tongue.
A3: Multilingual AI is an artificial intelligence designed to interpret and generate human language across hundreds of tongues using a single unified model. Unlike basic translation, it understands semantic intent and cultural nuances rather than just swapping words. This allows the AI to perform “zero-shot” tasks, meaning it can solve a problem in a language it was not specifically trained for by transferring knowledge from other mastered languages.
A4: Voice cloning is legal for commercial use as long as you have secured explicit, written consent from the individual being digitized. Under the 2026 regulatory landscape, including the EU AI Act, unauthorized clones are a violation of biometric property. Compliance also requires embedding digital watermarks, like C2PA metadata, in the audio to clearly disclose to the audience that the voice is AI-generated.




















