(+971) 8007 4267
(+971) 8007 4267 (+91) 946 340 7140
(+91) 946 340 7140 (+1) 628 432 4305
(+1) 628 432 4305

There comes a point in every growing organization when data stops being a simple record and becomes something that must be protected with intention. As systems scale and regulations evolve, storing sensitive information is no longer enough, and securing it across every environment becomes the new expectation. A well-designed tokenization engine can preserve data format for seamless integration and support lifecycle actions like rotation, re-tokenization, and revocation without breaking workflows. It also enables secure vault or vaultless models, depending on performance needs and compliance goals.
This approach lets teams analyze and process data normally while keeping the real values hidden. For any business handling regulated or identity-linked information, tokenization quickly shifts from a nice-to-have to a core requirement when scaling responsibly.
Over the years, we’ve built several data tokenization solutions using advanced technologies like confidential computing and format-preserving encryption. Using that expertise, we’re putting together this blog to help you understand how a data tokenization engine can be designed and implemented in a real-world environment. Let’s get started.
Key Market Takeaways for Data Tokenization Engines
According to IntroSpectiveMarketresearch, the data tokenization market continues to scale at a steady pace, reaching an estimated value of USD 2.26 billion in 2023 and expected to approach USD 10.4 billion by 2032. With a projected CAGR of around 18.48 percent, this growth signals a shift in how organizations think about data protection. Instead of relying solely on perimeter security, teams are moving toward techniques that secure the data itself while still allowing it to move across systems and workflows.
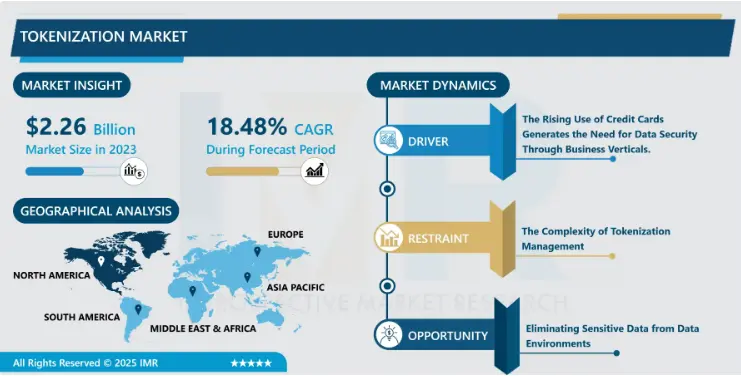
Source: IntroSpectiveMarketresearch
Tokenization engines are central to that shift because they enable replacing sensitive information with usable tokens that preserve format and functionality.
Platforms such as Protegrity and IBM Guardium stand out for their focus on compliance, scalability, and runtime monitoring, especially in regulated environments like finance and healthcare. These systems help organizations reduce regulatory scope, protect high-value data assets, and maintain operational flexibility without exposing raw information.
The ecosystem surrounding tokenization is also maturing through strategic partnerships that enhance interoperability and deployment options. Tokeny Solutions is a good example, working with Polygon for reliable blockchain scalability, Inveniam for verifiable data assurance, and Fireblocks for secure asset management.

What Is a Data Tokenization Engine?
A data tokenization engine is a system built to safeguard sensitive information by replacing it with a harmless stand-in called a token. The real data is stored securely elsewhere, similar to placing an original painting in a protected vault while displaying a replica to the public.
Unlike a one-off script or custom workflow, a tokenization engine is centralized, scalable, and accessible through APIs. It applies consistent policies across applications, teams, and environments so organizations avoid repetitive custom handling every time sensitive data appears.
Tokenization vs. Encryption vs. Masking
These methods are often grouped together, but they serve distinct purposes:
| Method | How It Works | Best Use Case | Key Differentiator |
| Tokenization | Replaces sensitive data with a random token stored in a secure vault. | Business processes where the data must be referenced without exposing it (such as payments or analytics). | Tokens are meaningless without vault access. |
| Encryption | Uses algorithms and keys to convert data into unreadable ciphertext that can be decrypted later. | Protecting data that must be retrieved or restored, such as secure messaging or stored records. | The original data still exists mathematically and relies entirely on key secrecy. |
| Masking | Permanently obscures part of the value (such as **** **** **** 1234). | Displaying or sharing data when the full value is not required. | Intended for display rather than secure storage and usually irreversible. |
Why tokenization is powerful: By storing the original sensitive information outside operational systems, organizations significantly reduce compliance scope and audit exposure. Systems that handle only tokens are not subject to the same strict regulatory controls.
Types of Tokenization Architectures
The way tokenization is implemented affects performance, scalability, and overall security posture. There are three widely adopted models.
1. Vault-Based Tokenization (Traditional Model)
Sensitive values are sent to the tokenization engine and stored in a secure Token Vault. The engine returns a randomly generated token that points back to the original value.
Advantages:
- Strong security, since tokens contain no meaningful relationship to the data.
- Well understood and auditor-friendly.
Challenges:
- Each tokenization or de-tokenization call requires a database lookup, which can add latency.
- The vault becomes a critical asset requiring heavy protection and redundancy.
2. Vaultless (Algorithmic) Tokenization
The engine uses Format-Preserving Encryption (FPE) to create a token without storing the original value. The same input and key always produce the same token. De-tokenization reverses the algorithm.
Advantages:
- Very fast, because no vault or lookup is involved.
- Eliminates the operational burden of storing sensitive data.
Challenges:
- Key management becomes the most important security factor, often requiring secure HSM-based protection.
- Security depends on cryptographic strength and proper handling of keys.
3. Hybrid Tokenization (Practical Real-World Approach)
Many organizations use a blended strategy that aligns security needs and performance expectations.
How it works: Vaultless tokenization is used for high-volume or low-latency workflows such as online payments. Vault-based tokenization is reserved for highly sensitive data that benefits from strict auditability, such as government identification numbers.
Example: An e-commerce company may tokenize credit card numbers algorithmically during checkout for speed, while storing Social Security numbers in a secure vault for compliance.
Choosing Between Format-Preserving vs. Randomized Tokens
When designing a tokenization strategy, one of the most important decisions is whether the token structure should mirror the original data structure. That choice affects system compatibility, regulatory compliance, analytics capabilities, and the overall security posture.
1. Format-Preserving Tokens (FPT)
A Format-Preserving Token retains the character set, structure, and length of the original value.
Example
- Original value: 4532-1234-5678-9012
- Format-preserving token: 2876-5401-3921-8765
Primary Benefit: System Compatibility
Format-preserving tokens are useful when working with systems that enforce strict validation or fixed database schemas. They allow the token to pass basic checks, such as length validation or the Luhn checksum for credit card numbers. This approach avoids schema changes and helps legacy systems continue functioning without modification.
2. Randomized Tokens
A Randomized Token has no structural relationship to the original data. It may be shorter, longer, or entirely different in character format.
Example
- Original value: 4532-1234-5678-9012
- Randomized token: tk_7x7d9k3n5n8m2l7 or aB9#rR$qZ
Primary Benefit: Security and Clarity
Because the token looks nothing like the original value, there is no ambiguity. A person or system can immediately identify that it is not real data. The flexibility in format also allows for stronger cryptographic randomness without constraints like fixed length or predictable formatting.
Comparison
| Feature | Format-Preserving Token | Randomized Token |
| Structure | Mirrors original data | Arbitrary format |
| Best Use Case | Legacy environments, strict validation systems | Modern platforms or greenfield systems |
| Main Strength | Compatibility | Security and clarity |
| Example | 2876-5401-3921-8765 | tk_7x7d9k3n5n8m2l7 |
Deterministic vs. Non-Deterministic Tokens
Once a format is selected, the next critical design decision involves determinism. Determinism defines whether the same input will always generate the same output.
Deterministic Tokens
A Deterministic Token ensures identical output for repeated tokenization of the same input.
Example
- Input: [email protected]
- Token: [email protected] (always the same)
Where Determinism Adds Value
Deterministic tokens enable operations that would be impossible with random outputs, including:
- Counting unique users or records
- Joining tokenized data across systems
- Building customer journeys or identity graphs
- Searching tokenized databases without detokenizing
- Preventing duplicate transactions in payment systems
This capability unlocks analytics and operational workflows while keeping sensitive data protected.
Security Consideration
Determinism increases exposure to dictionary attacks. If the potential input space is predictable, an attacker could attempt to tokenize known values and build a reverse lookup.
Mitigation Strategy
A common mitigation is the use of a salt or tweak. Instead of computing a token from the data alone, the engine computes it from a combination such as:
Token = Function(Data, Salt)
The salt may be tied to a tenant, domain, or field type. This prevents the creation of universal lookup tables because the same value in different contexts produces different tokens.
Non-Deterministic Tokens
A Non-Deterministic Token generates a different token every time the same input is processed.
Example
- Input: 4532-1234-5678-9012
- First token: 2876-5401-3921-8765
- Second token: 9112-3487-1256-4839
Where This Matters
This approach provides the highest level of protection because it removes any statistical relationship that an attacker could analyze. It prevents frequency analysis and eliminates the risk of lookup tables.
The trade-off is utility. Non-deterministic tokens cannot be joined, searched, or used for analytics. They are suitable when the token serves only as a pointer to the vault.
Putting It All Together
Reliable tokenization platforms do not rely on a single method. Instead, they support multiple token types and assign them based on context.
Examples:
- Deterministic format-preserving tokens for emails to support analytics and marketing systems.
- Non-deterministic format-preserving tokens for payment card numbers where validation and compatibility matter.
- Non-deterministic randomized tokens for internal secrets or values that never need to be queried or correlated.
Choosing the right combination ensures the system is secure, operationally efficient, and capable of supporting a long-term data strategy.
How Does a Data Tokenization Engine Work?
A data tokenization engine functions like a secure mint for sensitive information. It accepts valuable data and returns a safe token that your systems can use in its place. To your applications, the process feels simple and fast. Behind the scenes, the engine applies strict security controls and hardened protections to ensure the original data remains protected.
To understand how it works in practice, let’s follow a single sensitive value such as a credit card number as it passes through the system.
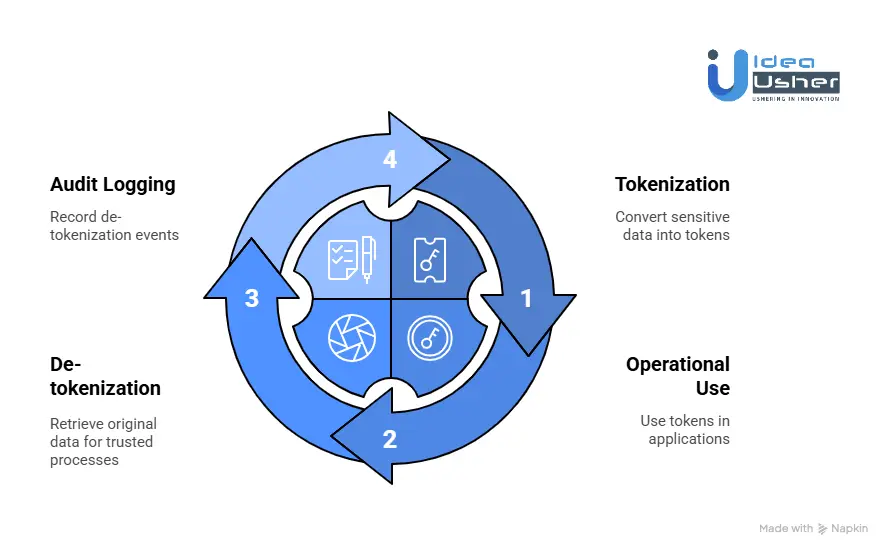
Core Components Inside the Tokenization Engine
Before looking at the workflow, it helps to understand the main pieces of the engine:
- Tokenization API: The secure entry point where applications send sensitive data and receive tokens.
- Token Generator: The component that produces the token, either through random generation or cryptographic transformation.
- Token Vault: A secured database that stores the mapping between original values and their tokens. This is only present in vaulted architectures.
These components work together to protect incoming data while supporting operational use cases.
Step 1: Tokenization
Tokenization happens when data first enters the system.
Example scenario: A customer enters a credit card number into an online checkout form.
Capture and Send: The application captures the number and immediately sends it to the Tokenization API. The sensitive value is never stored locally.
Generate Token: The Token Generator creates a token based on the chosen architecture:
- In a vaulted model, the token is randomly generated so it cannot be inferred from the original value.
- In a vaultless model, cryptography such as Format-Preserving Encryption transforms the input into a token that looks similar in structure to the original.
Store Mapping (Vaulted Only): In a vaulted system, the engine stores the original value and token as a pair inside the protected Token Vault.
Return Token: The Tokenization API returns the token to the calling application.
Operational Use:
The application stores and uses the token instead of the raw value in its CRM, order records, or analytics systems. Anyone who gains unauthorized access to the token gains nothing without the tokenization engine.
At this point, the sensitive data is either locked in the vault or never stored at all in a vaultless implementation.
Step 2: De-tokenization
De-tokenization retrieves the original value when a trusted process requires it. This should only occur for limited, critical workflows such as payment processing.
Example scenario: A payment processor needs the full card number to authorize a transaction.
Authorized Request: An approved service submits the token back to the Tokenization API and requests the original value.
Policy and Security Checks: The engine verifies:
- Who is making the request
- Whether they are allowed to access this specific type of data
- Whether the request originates from a secure and trusted environment
Retrieve the Original Value:
- In a vaulted model, the engine performs a secure lookup in the Token Vault.
- In a vaultless model, the system decrypts the token using the cryptographic key.
Create an Audit Log: Every de-tokenization event is recorded to support compliance, investigations, and governance. The log includes who requested access, when it occurred, and the reason provided.
Return the Data Securely: The original value is returned only to the requesting service and is typically used immediately and then discarded.
The Broader Architecture
In a real-world environment, the tokenization engine becomes a centralized trust layer. Multiple systems connect to it to tokenize sensitive information when it is first collected. Only a small subset of approved services is allowed to request de-tokenization.
This centralized model creates consistency across applications, reduces the number of systems that hold sensitive data, and simplifies compliance and security operations. Instead of securing sensitive data everywhere, organizations secure it once at the engine and use tokens everywhere else.
How to Build a Data Tokenization Engine?
A data tokenization engine begins by deciding which data must be tokenized to maintain compliance and accuracy. Then we design the token logic with strong cryptography so systems can still use the data without exposing the real values. Over the years, we have built many tokenization engines for clients, and this is exactly how we do it.
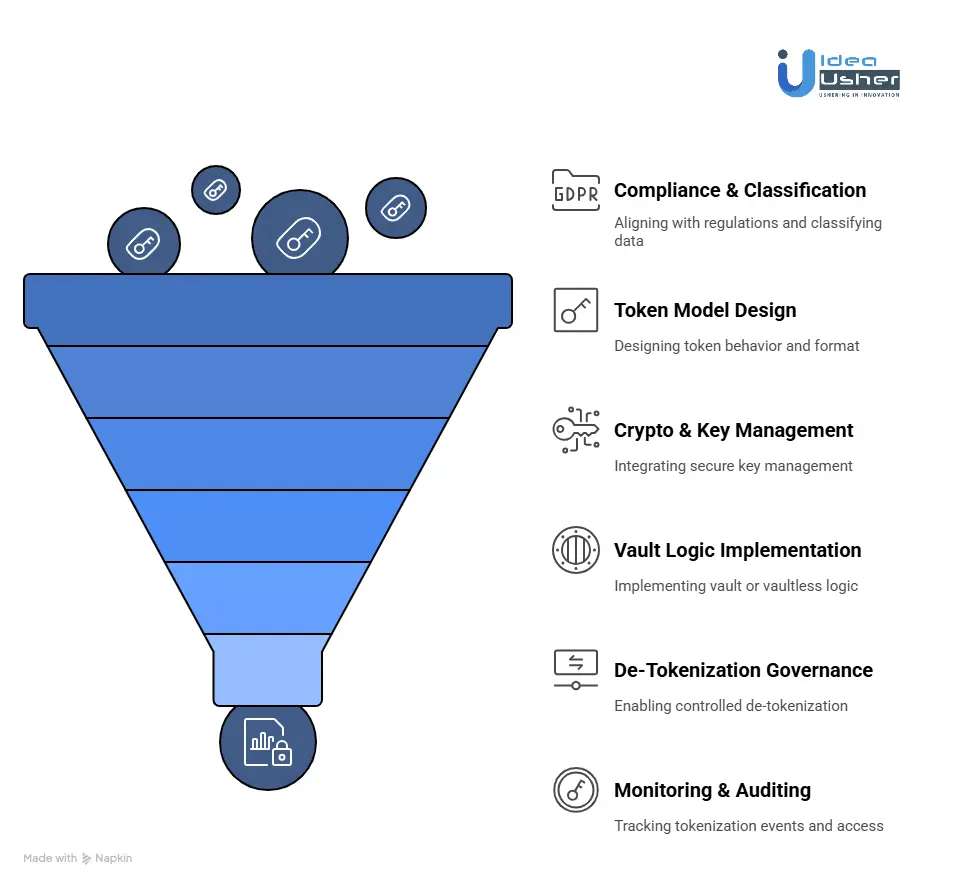
1. Compliance & Classification
We begin by aligning to regulatory frameworks such as PCI-DSS, GDPR, or HIPAA and classify data fields by sensitivity. This ensures only the required data is tokenized and mapped to its compliance obligations and permitted usage patterns.
2. Token Model Design
We design token behavior to match operational workflows, whether that means deterministic lookup consistency or non-deterministic privacy-focused tokens. Token format (preserving vs opaque) is selected based on compatibility with validation rules and downstream system requirements.
3. Crypto & Key Management
We integrate secure key management using trusted KMS or HSM platforms with enforced rotation, dual authorization, and strict lifecycle policies. All cryptographic activity is logged to support audit and compliance requirements.
4. Vault or Vaultless Logic
Based on the architecture requirements, we implement either a vault-based mapping model or a vaultless method using hashing, FPE, or encryption. Safeguards ensure token uniqueness, prevent replay risks, and maintain consistent mappings across systems.
5. De-Tokenization Governance
Controlled de-tokenization is enabled through a secure gateway using authentication, role-based access, and least privilege principles. All de-tokenization requests are logged to maintain auditability and enforce accountability.
6. Monitoring & Auditing
We deploy monitoring and visibility tools to track tokenization events, privilege changes, and access attempts. Logs are immutable, searchable, and aligned with retention and compliance requirements.
Use Cases of Data Tokenization Engines Across Various Sectors
A data tokenization engine can secure sensitive information without slowing operations and it protects financial data, health records, and customer identities by replacing real values with usable tokens. Organizations might use it to reduce compliance scope, maintain privacy across shared systems, and still run analytics or automation confidently.
1. Financial Services & FinTech
Banks, payment processors, lenders, and digital wallets manage some of the most targeted information on the planet: cardholder data, account numbers, transaction records, and personal identity details. Compliance frameworks like PCI DSS make mishandling costly and risky.
How Tokenization Helps:
Tokenization replaces payment card numbers and PII at the moment of capture, whether online, in-app, or at a card terminal. Tokens can be stored and used for refunds, loyalty programs, fraud modeling, or recurring billing without re-exposing the original data.
Example: Stripe
Stripe’s infrastructure converts raw card data into tokens (for example, tok_XXXX) before the merchant ever handles it. The token flows through the merchant’s systems, keeping PCI compliance scope minimal and reducing the attack surface.
2. Healthcare & Life Sciences
Healthcare must balance confidentiality with usability. Electronic health records, insurance workflows, and medical research rely on PHI, and regulations like HIPAA impose strict requirements for handling it.
How Tokenization Helps:
Tokenization allows healthcare organizations to work with de-identified patient data while preserving accuracy and continuity across systems. Research teams, analytics engines, and partner organizations can operate without exposing real identities.
Example: Pfizer
In research environments and clinical studies, patient identifiers can be replaced with deterministic tokens. The same patient receives the same token across datasets, which allows analysis and tracking without disclosing names, SSNs, or other direct identifiers.
3. Retail & E-Commerce
Retailers rely heavily on customer data to power automation, loyalty systems, and personalization engines. That same data, including emails, addresses, and payment details, makes them appealing targets for attackers.
How Tokenization Helps:
Tokenizing customer identifiers and payment information lets retailers retain useful data signals while removing high-risk elements. Teams can run marketing segmentation, returns workflows, and customer analytics without handling raw sensitive data.
Example: Amazon
Although proprietary, Amazon’s architecture demonstrates best practices for tokenization. Stored customer payment details are vaulted and tokenized, enabling repeat purchases and one-click checkout without repeatedly exposing the original card number.
4. Technology & SaaS
Software platforms hosting sensitive data for multiple customers must guarantee strict tenant isolation. At the same time, aggregated data is often needed for improving product performance, AI models, or usage insights.
How Tokenization Helps:
Tokenization engines can generate tenant-unique tokens so that the same value, such as an email address, appears different across accounts. A separate global token set enables safe cross-tenant analytics without exposing underlying values.
Example: Salesforce
Salesforce handles large volumes of sensitive business records. Tokenization plays a role in ensuring that customer data remains secure, isolated, and usable across internal analytics tools, storage layers, and integrated AI features.
Data Tokenization Engines Address the 12.7% Rise in Breach Costs
The average cost of a data breach has climbed 12.7% in just two years, reaching $4.45 million in 2023. With tokenization, sensitive data is replaced with irreversible tokens, so even if an attacker breaches the system, the stolen information has no operational value. This means investigations may be faster, regulatory exposure could shrink, and long-term financial risk is significantly reduced.
1. It Removes the Value of Stolen Data
Attackers target data they can monetize or weaponize, such as payment details, personal identities, and credentials. When this data is compromised, the resulting fraud, legal exposure, and customer impact drive costs rapidly upward.
How Tokenization Fixes the Problem:
Tokenization replaces sensitive information with format-preserving but meaningless values. If an attacker accesses a tokenized database, they walk away with something unusable. No identity theft. No card fraud. No resale value.
Direct Cost Reductions:
- Customer notification and credit monitoring may not be required if no sensitive data was exposed.
- Fraud losses are avoided because tokens cannot be used for transactions or impersonation.
- Customer churn decreases because no personal harm has occurred.
2. Reduces Regulatory Scope & Risk of Penalties
Laws such as GDPR, PCI DSS, and CCPA carry heavy penalties when protected data is exposed. The more systems storing sensitive data, the larger the compliance footprint and the greater the financial exposure.
How Tokenization Helps:
By isolating raw sensitive data in a secure vault, tokenization removes many systems from compliance scope. Systems that only process tokens are not held to the same strict regulatory requirements.
Direct Cost Reductions:
- Regulatory fines are significantly lower and in many cases, avoidable.
- Annual audit and compliance workloads decrease because fewer systems need to be evaluated.
3. Shortens Breach Response
The longer it takes to identify and contain a breach, the more expensive it becomes. IBM reports that resolving a breach in under 200 days saves more than $1 million.
How Tokenization Speeds Resolution:
With tokenized data, the most urgent forensic question is already answered. The attacker accessed tokens, not live data. Security and response teams can focus on the vulnerability rather than scrambling to determine what was compromised.
Direct Cost Reductions:
- Faster containment because investigation scope is smaller and clearer.
- Lower forensic and legal costs due to reduced analysis complexity.
4. Protects Customer Trust & Brand Reputation
The most damaging long-term consequence of a breach is often the loss of customer trust and future business. Reputation recovery can take years and cost more than the initial incident.
How Tokenization Supports Trust:
Organizations can confidently communicate that sensitive information was never stored in the compromised environment. This shifts the narrative from failure to responsible prevention.
Direct Cost Reductions:
- Revenue retention due to reduced customer churn.
- Lower marketing, legal, and public relations costs tied to crisis management.
Common Challenges of a Data Tokenization Engine
Building a tokenization engine might seem simple at first, but in production environments, reliability, security, and predictable performance are essential. If you are planning to implement one, you should expect technical hurdles, and you can avoid most of them with careful architecture and Zero Trust controls.
1. Eliminating Token Collisions in Deterministic Tokenization
Deterministic tokenization is essential when different systems must match or aggregate protected fields. If two distinct values ever produce the same token, data integrity collapses. Analytics fail, referential joins break, and auditability is compromised.
How We Solve It:
We address this at both the cryptographic and architectural level:
Collision-Proof Cryptography
We rely on NIST-approved Format-Preserving Encryption modes (such as FF1), which operate as true bijections. Every unique input generates a unique output within its domain. With correct configuration, collisions are mathematically impossible, not merely unlikely.
Salted Tokenization Domains
We apply contextual salts or “tweaks,” such as tenant identifiers, business domains, or purpose tags. This prevents cross-application collisions and protects systems from dictionary or replay attacks. For example, a Social Security Number tokenized for analytics will differ from the version used in payment workflows, even if the input is identical.
2. Enforcing Zero Trust in De-tokenization Controls
Decrypting or reversing tokens is the highest-risk activity in the system. A basic API key is not enough, especially in regulated environments where auditability and strict access segmentation are required.
How We Solve It:
We enforce layered verification and intent-aware authorization:
Multi-Factor Authorization Controls:
Access validation includes:
- Application identity (mTLS or OAuth2 machine credentials)
- User identity (JWT or SAML with RBAC)
- Environmental context (approved zones, IP allowlists, risk scoring)
Purpose-Based Access Enforcement:
Every de-tokenization request must declare its purpose, such as payment settlement or fraud investigation. Requests outside approved use cases are rejected automatically. All approved access is captured in an immutable audit log for compliance review and security forensics.
3. Scaling Performance Under High Transaction Volumes
Tokenization should not impact system speed or customer experience. Poorly designed vaulted architectures can introduce latency bottlenecks.
How We Solve It:
Performance optimization is built into the architecture:
- Secure, Short-Lived Caching: Frequently accessed records are cached in-memory (for example, using Redis) with strict TTL rules. Sensitive data is never persisted longer than necessary.
- Connection Pooling and Read Replication: Vaulted systems leverage optimized database access patterns and read replicas to distribute load without overwhelming primary storage.
- Vaultless Tokenization for Extreme Scale: In high-volume environments such as e-commerce and payment networks, we deploy vaultless FPE models backed by Hardware Security Modules (HSMs). This eliminates lookup overhead and enables linear scalability.
4. Secure, Compliant Cross-Region Synchronization
Global enterprises must balance availability, regulatory constraints, and exposure to the attack surface. Replicating sensitive token vaults across regions can introduce unnecessary risk.
How We Solve It:
- Active-Passive Failover with Regional Key Isolation: Each region encrypts data using region-specific keys stored in local HSMs. This prevents the uncontrolled spread of sensitive data and maintains compliance with residency requirements.
- Controlled, Encrypted Replication Workflows: During failover, data moves between HSMs in encrypted form. Upon arrival, it is re-encrypted using the passive region’s key before being stored. No region ever holds unencrypted or improperly keyed data.
Tools & APIs Required for Data Tokenization Engine
Designing a scalable and compliant data tokenization engine requires a combination of modern infrastructure, advanced security technologies, resilient data pipelines, and intelligent monitoring frameworks. The following stack outlines the essential components for architecting a robust, enterprise-grade tokenization solution.
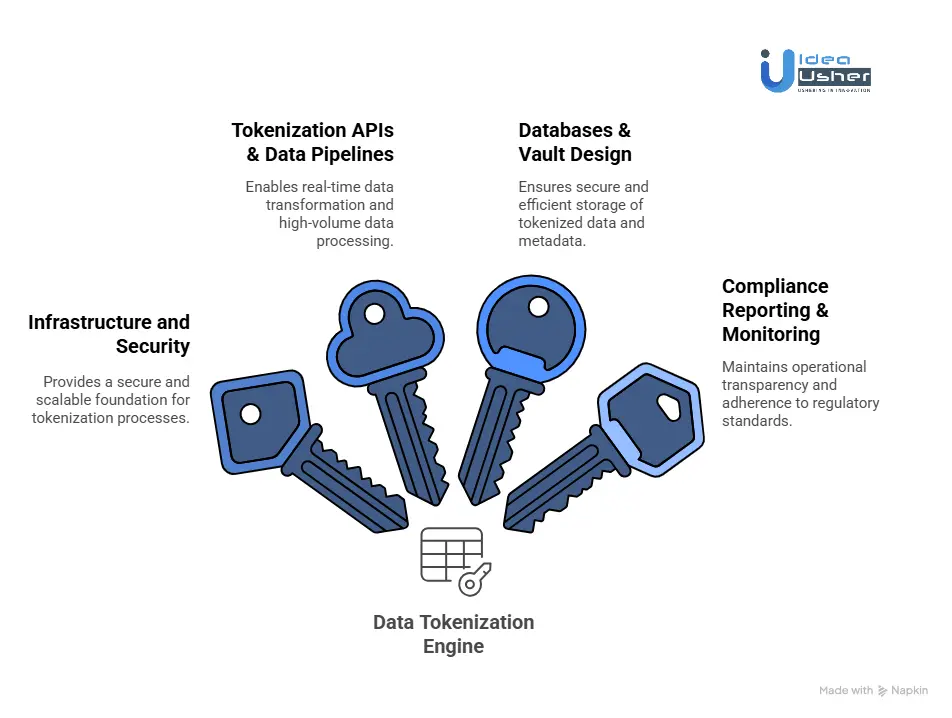
1. Infrastructure and Security
A strong security foundation is critical to safeguard cryptographic processes and ensure the integrity of tokenized data. Key infrastructure components include:
- Hardware Security Modules such as Thales, AWS CloudHSM, and Azure Key Vault HSM, which provide FIPS-compliant, tamper-resistant environments for managing, generating, and storing encryption keys.
- Kubernetes and Docker enable microservices-based deployment, ensuring the platform can scale dynamically while maintaining isolation, resilience, and rapid workload distribution across hybrid or multi-cloud environments.
- HashiCorp Vault is used for secrets management, encryption, and secure identity management, offering centralized policy enforcement and zero-trust security controls.
Together, these technologies provide a secure and scalable backbone for tokenization workflows.
2. Tokenization APIs & Data Pipelines
To support real-time data transformation and global enterprise workloads, the platform integrates high-performance API orchestration and event-streaming systems:
- Kafka and AWS Kinesis deliver reliable and fault-tolerant event streaming, enabling high-volume ingestion and processing of sensitive data while maintaining low latency.
- API Gateway and Kong provide secure, rate-limited, and authenticated API access, allowing seamless integration with enterprise applications, data services, and third-party platforms.
This combination enables continuous data flow, resilient communication frameworks, and consistent tokenization performance at scale.
3. Databases & Vault Design
The persistence layer of a tokenization platform must balance performance, consistency, and fault tolerance while protecting the relationship between original data and tokenized values.
- PostgreSQL and MongoDB support both transactional and document-based storage models, which are essential for secure token mapping and metadata management.
- DynamoDB and Redis provide distributed, in-memory, and high-availability storage for rapid lookup, caching, and scalable token repository operations.
These databases underpin the secure vault architecture, ensuring encrypted, auditable, and highly available token storage.
4. Compliance Reporting & Monitoring
Operational transparency and continuous compliance are mandatory for aligning with regulatory frameworks such as PCI-DSS, GDPR, HIPAA, and SOC 2.
Key observability and monitoring tools include:
- Splunk and Datadog for real-time security analytics, anomaly detection, and performance monitoring.
- ELK Stack (Elasticsearch, Logstash, Kibana) enables log aggregation, dynamic visualization, and compliance-ready audit trails across distributed services.
With these systems in place, organizations can enforce governance policies, detect risks proactively, and maintain full auditability across the data protection lifecycle.
Top 5 Enterprise Data Tokenization Engines
We researched the market and found a set of tokenization engines that stand out for technical depth and meaningful security impact. These platforms can scale across demanding environments and manage sensitive data with confidence.
1. Skyflow

Skyflow is a modern privacy vault platform built to store and process sensitive data such as PII, financial identifiers, and healthcare records using tokenization and strong access controls. It provides zero-trust principles by separating data storage from application logic and allows enterprises to share sensitive data through policy-driven APIs securely.
2. Ubiq Security
Ubiq provides a developer-friendly data protection platform offering encryption, tokenization, and masking that can be embedded directly into applications via APIs. It enables fine-grained control over how sensitive data is stored and accessed, supporting zero-trust models and identity-driven data access.
3. ACI Omni-Tokens

ACI Omni-Tokens is a PCI-compliant payment tokenization solution designed to protect card data across digital commerce, banking, and payment processing environments. Its flexible token formats allow organizations to support both single-use and multi-use tokens while maintaining compatibility with backend systems.
4. Protegrity
Protegrity is an enterprise data protection platform offering tokenization, encryption, and data de-identification for large organizations with strict compliance demands. Known for its field-level tokenization capabilities, the platform integrates with databases, analytics systems, and cloud environments.
5. ShieldConex
ShieldConex offers vaultless, format-preserving tokenization designed for secure handling of payment and personal data. It supports real-time tokenization across digital channels and can be embedded directly into data capture workflows. This makes it especially useful for companies managing customer transaction data.
Conclusion
Tokenization is no longer just a security feature because it has quietly become a foundation for privacy, compliance, and safe data use across modern systems. When the engine is designed well, it supports AI adoption, regulated workflows, and scalable architectures without forcing teams to expose sensitive data. The real decision for most enterprises now is not whether tokenization matters, but how to choose an approach that balances utility, reversibility, and regulatory boundaries while still supporting long-term innovation.
Looking to Develop a Data Tokenization Engine?
Idea Usher can help you build a tokenization engine by designing an architecture that aligns with your data flows and compliance requirements while maintaining predictable performance. Their team can integrate format-preserving or deterministic models, so your legacy and modern systems work smoothly.
Build with Confidence:
- Led by ex-MAANG/FAANG engineers who know how to build secure, scalable infrastructure.
- Over 500,000 hours of coding experience ensure your project is in expert hands.
Stop risking it. Start tokenizing it.


FAQs
A1: Tokenization replaces sensitive data with a random placeholder that has no mathematical link to the original value, while encryption scrambles the data so it can be decrypted with a key. Tokenization is usually irreversible unless you access the token vault, and encryption is meant to be reversible. This difference affects compliance and risk because attackers need a vault breach to break tokenization rather than just a key.
A2: Yes, it can, especially when using deterministic or format-preserving options, so field lengths and character rules stay intact. Many teams integrate tokenization at the API layer or message broker rather than modifying COBOL code. It is rarely perfect on day one, but it is absolutely workable.
Q3: No, it does not completely remove compliance, but it reduces the number of systems in scope. If protected data never touches most apps or databases, those components do not require the same audits. You still need access controls and policies to prove the process is secure.
A4: Yes, it can, and it often should. Deterministic reversible tokens keep joins and model logic consistent without exposing real identifiers. Later, you may reveal only what is necessary under strict controls. This lets you train or process data safely while maintaining privacy.