 (+971) 8007 4267
(+971) 8007 4267 (+91) 946 340 7140
(+91) 946 340 7140 (+1) 628 432 4305
(+1) 628 432 4305


Scientific discovery platforms deal with complex data, evolving hypotheses, and long research cycles where accuracy and reproducibility matter more than speed alone. Researchers often need systems that can analyze large datasets, identify patterns, and support reasoning across multiple variables. These requirements are shaping the design of an AI scientific discovery engine, where computation assists scientists in generating insights rather than simply automating tasks.
Turning research data into meaningful scientific insights requires a coordinated system rather than a single model. Data pipelines, simulation environments, reasoning models, and validation frameworks must operate together within a structured architecture. The way these components interact determines whether the platform can reliably assist in hypothesis generation, experimental design, and knowledge discovery without introducing noise or bias.
In this blog, we explore AI engine architecture for scientific discovery platforms by examining core system layers, architectural patterns, and practical considerations involved in building reliable AI infrastructure for research environments.

Overview of AI Engine for Scientific Discovery Platforms
An AI Engine for Scientific Discovery is the core computational component of specialized platforms designed to automate and accelerate the scientific method. Rather than just searching for information, these engines function as “AI Co-Scientists” or “Discovery Agents” that can reason, hypothesize, and even design experiments.
Core Functions of the AI Engine
The AI scientific discovery engine drives the transition from traditional, document-heavy research to a machine-readable, data-driven “World Model” of a scientific field.
- Knowledge Distillation: Uses Large Language Models (LLMs) to extract granular, verifiable data (parameters, mechanisms, results) from millions of research papers, converting them into structured formats like Knowledge Graphs.
- Hypothesis Generation: Analyzes synthesized data to identify “knowledge gaps” and propose novel, testable theories grounded in existing evidence.
- Agentic Reasoning: Specialized agentic AI systems can plan research workflows, simulate natural processes (like protein folding), and refine experiments in real-time.
- Physics-Informed Modeling: Integrates physical laws directly into AI algorithms to ensure that generated designs for new materials or drugs are scientifically plausible.
How AI Engine Work for Scientific Discovery Platforms?
The AI scientific discovery engine functions as a recursive intelligence loop, autonomously synthesizing vast research data to generate hypotheses, simulate outcomes in digital twins, and execute robotic experiments for rapid, verified breakthroughs.
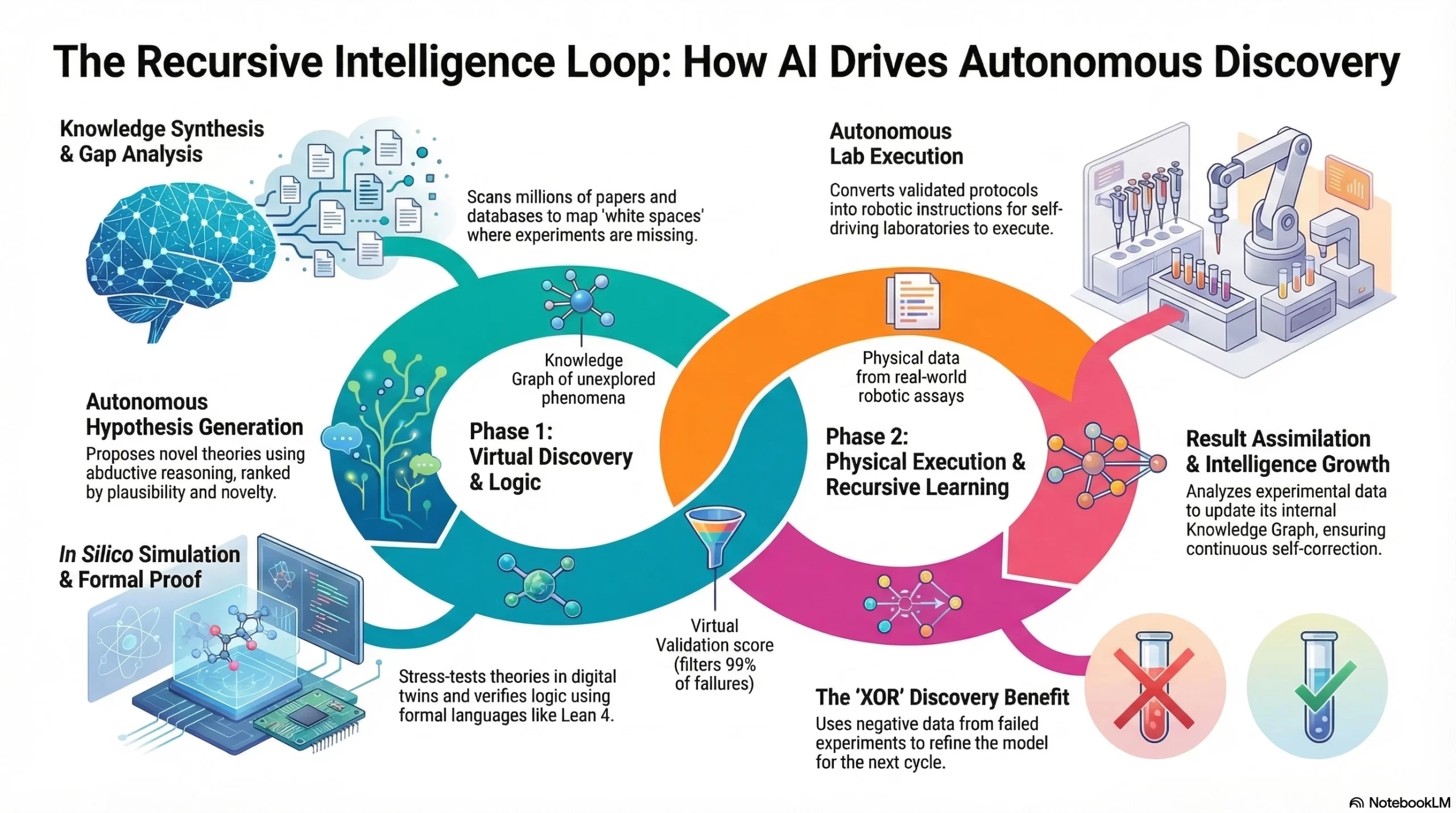
1. Knowledge Synthesis & Gap Analysis
The engine begins by ingesting millions of unstructured data points to build a “mental map” of the current scientific frontier.
- The Process: Multi-modal LLMs scan arXiv papers, patents, and “omics” databases. Using Semantic Search, the engine identifies contradictions between studies or “white spaces” where no experiments have been recorded.
- Result: A Knowledge Graph that highlights unexplored molecular structures or physical phenomena.
2. Autonomous Hypothesis Generation
Instead of waiting for a human prompt, the engine uses Abductive Reasoning to propose novel scientific theories.
- The Process: The engine uses agentic workflows to “brainstorm” potential solutions. For example, in drug discovery, it might hypothesize that a specific protein fold can inhibit a virus based on structural analogies in unrelated fields.
- Result: A list of prioritized, machine-readable hypotheses ranked by Plausibility and Novelty.
3. In Silico Simulation & Virtual Testing
Before entering a physical lab, the hypothesis is stress-tested in a high-fidelity digital environment.
- The Process: The engine triggers a Digital Twin or a Molecular Dynamics simulation. It uses Physics-Informed Neural Networks (PINNs) to ensure the hypothesis doesn’t violate the laws of thermodynamics or gravity.
- Result: A “Virtual Validation” score that filters out 99% of ideas that would fail in the real world.
4. Formal Verification & Proof
For theoretical or mathematical discoveries, the engine must prove that the logic is airtight.
- The Process: The engine translates its reasoning into a formal language like Lean 4. A symbolic “truth kernel” (SMT solver) checks the proof. If a logical gap is found, the engine backtracks and self-corrects the hypothesis.
- Result: A Verified Proof or a logically sound experimental protocol.
5. Autonomous Lab Execution (The “Closed Loop”)
The AI scientific discovery engine moves from “thinking” to “doing” by communicating directly with Self-Driving Laboratories (SDLs).
- The Process: The engine converts the validated protocol into robotic instructions (e.g., liquid handling commands). Robotic arms execute the chemical synthesis or biological assay without human intervention.
- Result: Physical data generated from a real-world experiment.
6. Result Assimilation & Recursive Learning
The final stage of the AI scientific discovery engine is where the “intelligence” actually grows.
- The Process: The engine analyzes the lab results. If the experiment failed (an XOR discovery), the engine uses that “negative data” to update its Knowledge Graph, ensuring it never makes the same mistake again.
- Result: A refined model that is smarter for the next discovery cycle.
How AI Is Reshaping Scientific Discovery Platforms?
The AI scientific discovery engine has moved beyond simple data analysis toward autonomous reasoning and execution. AI is no longer just a tool for scientists; it has become a collaborative partner capable of navigating the vast complexities of biology, chemistry, and physics.
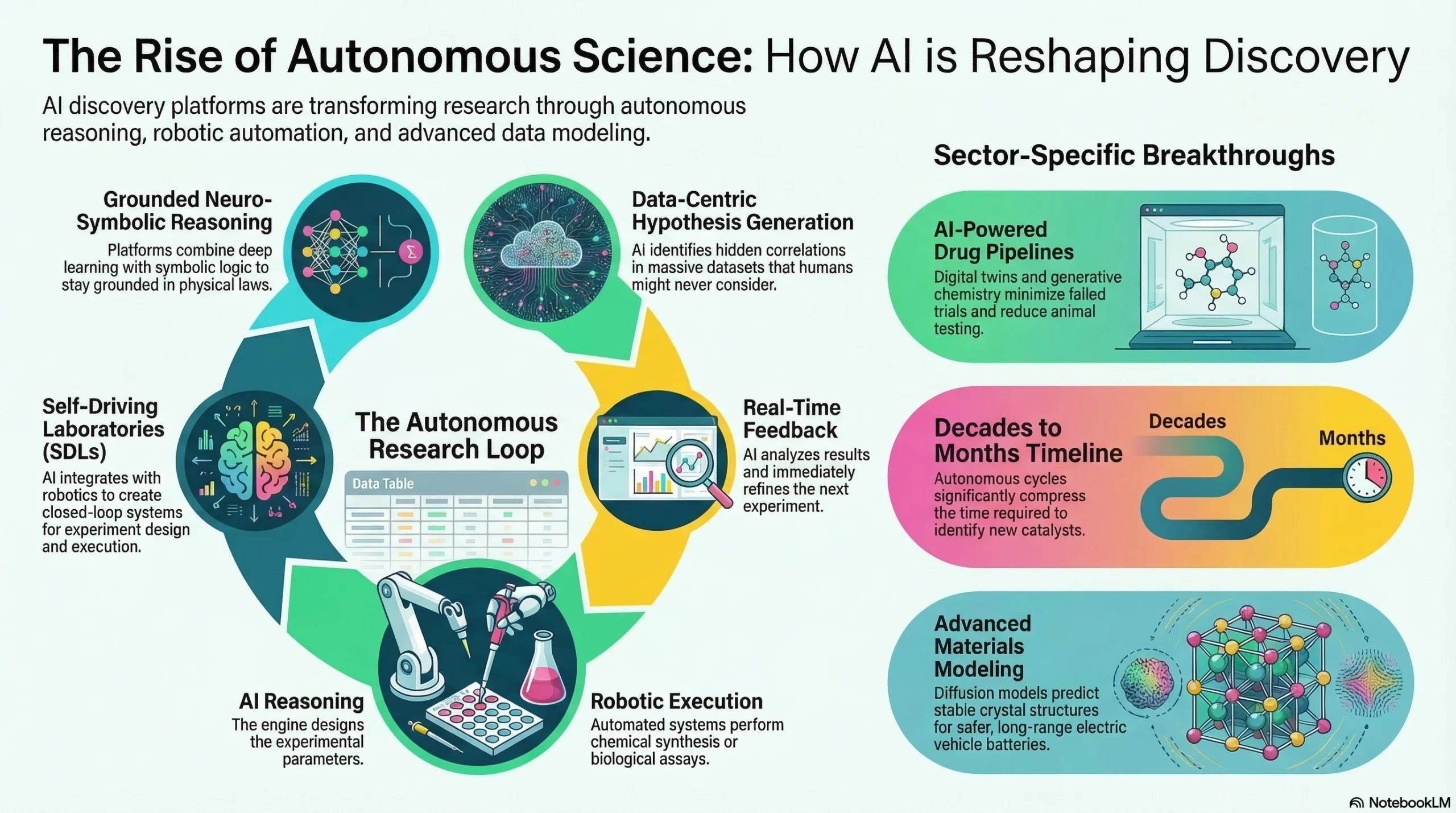
1. Data-Centric Hypothesis Generation
Traditional science relies on humans forming a hypothesis and testing it. Modern discovery platforms have inverted this model. AI now scans massive datasets to generate novel hypotheses that humans might never consider, identifying hidden correlations in genomics, climate patterns, and particle physics.
2. The Rise of Self-Driving Laboratories (SDLs)
One of the most transformative shifts is the emergence of Self-Driving Labs. These platforms integrate AI with advanced robotics to create a closed-loop system:
- AI Plans: The reasoning engine designs an experiment.
- Robots Execute: Automated systems perform chemical synthesis or biological assays.
- Real-Time Feedback: The AI analyzes the results and immediately refines the next set of parameters.
Impact: This cycle reduces discovery timelines from decades to months, particularly in identifying new catalysts for sustainable energy.
3. AI-Powered Drug Discovery Pipelines
AI has moved into Phase III clinical validation. Discovery platforms are now optimized for:
- Target Identification: AI models analyze “omics” data (genomics, proteomics) to find precise protein targets for diseases like Alzheimer’s.
- Generative Chemistry: Platforms like GENTRL design entirely new molecules with optimal safety profiles, bypassing thousands of failed wet-lab trials.
- Digital Twins: Virtual patient models simulate how a specific drug will react in a human body, significantly reducing the reliance on animal testing.
4. Materials Science and the “Materials Project”
AI-ready datasets are fueling a revolution in battery technology and semiconductors. Platforms like the Materials Project provide curated data that allows AI to predict the stability of millions of new crystal structures.
Real-World Example: Researchers are using Diffusion Models (similar to those used in AI art) to “generate” new solid-state electrolytes for safer, long-range electric vehicle batteries.
5. Neuro-Symbolic Reasoning in Pure Science
The latest platforms combine Deep Learning with Symbolic Logic. This ensures that while the AI is creative in its suggestions, it remains grounded in the “laws of the universe.” In 2026, these neuro-symbolic systems are being used to formalize complex mathematical proofs and decode the “language” of proteins.
Why are AI Scientific Discovery Platforms Gaining Popularity?
The global AI for scientific discovery market was valued at USD 4.80 billion in 2025, expected to grow from USD 5.85 billion in 2026 to about USD 34.78 billion by 2035, with a CAGR of 21.90% from 2026 to 2035. This growth highlights the need for scalable AI engine architectures for scientific discovery platforms to accelerate research and complex data analysis.

A notable example is Insilico Medicine, which reduced the target-to-preclinical-candidate timeline to 12–18 months compared to the traditional 2.5–4 years and achieved a 100% success rate in advancing 22 candidates from the preclinical stage to the Investigational New Drug (IND)-enabling stage.
AI-discovered molecules also show Phase I success rates of 80–90%, compared to the industry average of 40–65%, while AI-guided screening achieves hit rates of 22–46%, far higher than the ~2% from traditional random screening.
Google DeepMind’s GNoME has accelerated materials discovery by predicting 2.2 million new stable crystalline materials, a task that would have taken nearly 800 years using traditional trial-and-error experimentation.

What Datasets are required to train AI Scientific Discovery Models?
Training a robust AI scientific discovery engine requires more than just raw text; it demands a multi-modal approach that blends structured empirical data with high-level human reasoning. The focus has shifted toward high-fidelity, “physics-informed” datasets that ground AI in the laws of the universe.
| Dataset Category | Contents & Data Types | Primary Purpose & Utility |
| Scientific Literature & Patents | Multi-million academic papers, full-text patents, and technical reports in LaTeX/PDF. | Enables the model to understand the current “state of the art,” synthesize research, and perform autoformalization. |
| Structural & Omics Data | 3D protein structures, genomic sequences, metabolic pathways, and small molecule interactions. | Essential for drug discovery, protein engineering, and understanding biological functions. |
| Physical Properties & Simulations | Material crystal structures, fluid dynamics parameters (velocity, pressure), and stress-test telemetry. | Trains the model on the “basis of physical processes,” allowing it to predict material stability and engineering outcomes. |
| Formal Logic & Proof Packs | Verified proof chains in Lean 4, Coq, or Isabelle, including informal-to-formal pairs. | Grounds the engine in absolute mathematical truth, preventing logical hallucinations during complex derivations. |
| Autonomous Lab Feedbacks | Real-time sensor logs from Self-Driving Labs (SDLs), including “negative results” from failed trials. | Facilitates Reinforcement Learning from Verifiable Rewards (RLVR) to train autonomous research agents. |
The 2026 Data Strategy: “Quality Over Quantity”
- The “Small Data” Revolution: Unlike general LLMs that thrive on the broad internet, scientific models in 2026 prioritize curated, high-signal data. A single terabyte of verified fluid dynamics data (like the Walrus dataset) is more valuable than petabytes of unverified web text.
- Closing the Loop: The most advanced models now train on synthetic data generated by simulators (Digital Twins) and then validated by real-world robotic labs, creating a self-improving cycle of scientific accuracy.
Core Layers of AI Scientific Discovery Platforms
To transition from general-purpose AI to a specialized AI scientific discovery engine, the architecture must balance high-performance computing with rigorous logical verification. This layered approach ensures that the engine can move from raw data to verified scientific breakthroughs.

1. Inference & Reasoning Layer
This layer serves as the system’s“Brain” and handles high-level cognitive tasks including hypothesis generation and strategic planning. It employs multi-step logical deduction to navigate complex scientific variables and coordinate the discovery process autonomously.
Key Technologies & Frameworks: Neuro-Symbolic LLMs (e.g., GPT-4o, Claude 3.5), Chain-of-Thought (CoT), and Monte Carlo Tree Search (MCTS) for pathfinding.
2. Verification & Formal Logic Layer
This layer acts as a digital “Scientific Peer Reviewer” and ensures every discovery is grounded in reality. It validates AI-generated outputs against rigid physical laws, mathematical axioms, and chemical constraints to eliminate hallucinations.
Key Technologies & Frameworks: Lean 4, Z3 SMT Solvers, AlphaFold (for biological verification), and Physics-Informed Neural Networks (PINNs).
3. Knowledge & Context Layer
This layer functions as the platform’s “Library,” providing the engine with structured access to billions of scientific data points. It integrates research papers, experimental results, and curated databases into a searchable, high-fidelity knowledge base.
Key Technologies & Frameworks: Graph Databases (Neo4j), Vector Databases (Milvus/Pinecone) for RAG, and Knowledge Graphs (BioKG, Materials Project).
4. Simulation & Digital Twin Layer
The “Digital Sandbox” allows for risk-free experimentation by running virtual tests in physics or chemistry. It predicts how new materials or molecules behave under various conditions before committing resources to physical laboratory trials.
Key Technologies & Frameworks: NVIDIA Modulus, Molecular Dynamics software (GROMACS, LAMMPS), and high-fidelity physics engines for real-time simulation.
5. Data Acquisition & Orchestration Layer
Operating as the “Nervous System,” this layer manages the massive flow of information from IoT sensors and robotic labs. It handles the scaling of GPU resources and ensures data integrity across the entire discovery pipeline.
Key Technologies & Frameworks: Kubernetes for GPU orchestration, Apache Kafka for real-time data streaming, and LIMS (Laboratory Information Management Systems).
Strategic Integration Points
- The Logic-Simulation Loop: When the Reasoning Layer suggests a new material, the Simulation Layer tests its thermal stability. The results are fed back to the Knowledge Layer, refining the model’s understanding for the next iteration.
- Physics-Informed Inference: Unlike standard AI, the Inference Layer in these platforms is often constrained by PINNs, meaning it literally cannot suggest a solution that violates the laws of thermodynamics or conservation of energy.
AI Engine Architecture Behind Scientific Discovery Platforms
Modern AI scientific discovery engines integrate symbolic logic with high-dimensional data pipelines to automate the scientific method. This modular architecture prioritizes verifiability, multi-step reasoning, and rigorous reproducibility over simple generative output.

1. Data Ingestion for Scientific Data Pipelines
This foundational layer automates the extraction of complex insights from fragmented sources, transforming unstructured research papers and raw laboratory instrument data into high-fidelity, machine-ready computational assets.
| Feature | Technical Implementation | Research Impact |
| Multimodal Parsing | OCR and encoders for chemical structures and LaTeX. | Converts “dark data” (PDFs/lab notes) into machine-readable assets. |
| Provenance Tracking | Metadata tagging with cryptographic hashing. | Ensures 100% auditability for regulatory and patent filings. |
| Normalization | Unified schema mapping for heterogeneous sources. | Enables cross-silo analysis of disparate dataset types. |
2. Research Knowledge Graph Architecture
The Knowledge Graph creates a structured relational memory by mapping intricate relationships between biological entities that allow the AI to navigate the vast interconnected landscape of scientific literature.
| Component | Role in Discovery | Strategic Value |
| Entity Resolution | Identifying proteins, compounds, and genes. | Eliminates manual data cross-referencing. |
| Relational Mapping | Building “Subject-Predicate-Object” triples. | Reveals “hidden” links between distant research fields. |
| Ontology Sync | Alignment with MeSH, GO, and ChEMBL. | Standardizes scientific vocabulary across global teams. |
3. AI Model Layer for Scientific Reasoning
This layer of the AI scientific discovery engine utilizes specialized ensemble models grounded in factual data, ensuring that every cognitive output is cross-verified against established scientific laws to eliminate the risk of generative hallucinations.
| Logic Type | Execution Method | Benefit |
| Expert Mixture | Routing queries to specialized models (e.g., ChemBERTa). | Maximizes accuracy for domain-specific tasks. |
| RAG Anchoring | Grounding LLM outputs in the Knowledge Graph. | Virtually eliminates AI hallucinations in research. |
| Constraint Logic | Hard-coding physical and chemical laws. | Ensures outputs are scientifically plausible, not just statistical. |
4. Hypothesis Generation and AI Agent Layer
Autonomous agents proactively explore unexplored data intersections to propose novel research directions, employing adversarial logic to validate the strength and feasibility of new hypotheses before lab testing begins.
| Agent Type | Primary Responsibility | Outcome |
| Proposer Agent | Latent space exploration for novel interactions. | Generates non-obvious leads for drug repurposing. |
| Critic Agent | Adversarial debunking using existing literature. | Filters out weak hypotheses before they reach the lab. |
| Ranking Agent | Scoring leads by ROI and feasibility. | Prioritizes high-probability research avenues. |
5. Simulation and Experiment Modeling Layer
This layer predicts molecular interactions by creating digital twins of physical environments and reaction kinetics in-silico, significantly reducing the cost and time associated with traditional wet-lab trial and error.
| Simulation Type | Technical Tooling | Efficiency Gain |
| Molecular Dynamics | Predicting binding affinity and protein docking. | Reduces “trial and error” in the physical lab. |
| In-Silico Modeling | Running virtual experiments on “Digital Twins.” | Optimizes reaction parameters without wasting reagents. |
| Structure Prediction | Integration of AlphaFold-style folding models. | Accelerates the identification of druggable targets. |
6. Scientific Workflow Orchestration Layer
This brain of the system manages complex dependencies and computational schedules, ensuring that every step of the discovery lifecycle is automated, scalable, and meticulously logged for full scientific reproducibility.
| Layer | Functional Scope | Reliability Factor |
| Task Scheduling | Dependency management via Airflow or Prefect. | Prevents bottlenecks in multi-stage discovery cycles. |
| Version Control | Snapshots of models, data, and parameters. | Ensures every discovery is fully reproducible. |
| Resource Scaling | Dynamic GPU/CPU allocation for peak loads. | Minimizes downtime during intensive simulation runs. |
7. Research Interface and Visualization Layer
Translating complex backend computations into intuitive visual workspaces, this layer enables researchers to manipulate molecular structures and interact with AI leads, maintaining a critical “Human-in-the-Loop” for strategic decision-making.
| Toolset | Visual Capability | Human Integration |
| 3D Rendering | Interactive molecular and protein viewers. | Allows researchers to inspect “AI-suggested” bonds. |
| Clustering Maps | High-dimensional data heatmaps (t-SNE/UMAP). | Simplifies complex relationship patterns for humans. |
| Feedback Loop | Manual “override” or validation buttons. | Keeps the expert in the loop for final decision-making. |
8. Infrastructure Layer for High Performance Computing
The physical backbone of the AI scientific discovery engine provides the massive parallel processing power necessary to handle extreme data throughput, utilizing high-speed interconnects and GPU clusters to sustain real-time scientific modeling.
| Infrastructure Piece | Specification Focus | Operational Necessity |
| GPU Clusters | H100/A100 clusters with NVLink. | Handles the massive throughput of model inference. |
| Data Fabric | InfiniBand for low-latency node communication. | Critical for large-scale parallel simulations. |
| Storage Tiering | NVMe-based hot storage for active projects. | Accelerates data retrieval for training and reasoning. |
AI Scientific Discovery Platform Development Process
Building an AI scientific discovery engine platform requires a multi-layered engineering approach that integrates high-fidelity scientific datasets with formal reasoning engines and automated laboratory interfaces for accelerated, verifiable research breakthroughs.
1. Define the Scientific Research Domain
Consult with an experienced development company like IdeaUsher and select a specific scientific field like drug discovery or materials science. Establish clear research goals and identify the physical constraints and regulatory standards that will govern the engine’s logical boundaries.
2. Design the Data and Knowledge Graph Architecture
Construct a robust repository by integrating structured databases and unstructured literature. Build a multi-layered knowledge graph to map complex relationships between entities, ensuring high-fidelity data retrieval for the reasoning engine.
3. Develop the AI Reasoning and Modeling Engine
Engineer the core “brain” using LLMs integrated with formal logic kernels. Implement search algorithms like Monte Carlo Tree Search to enable the system to navigate complex, multi-step scientific problem-solving paths.
4. Integrate Simulation and Experimentation Tools
Connect the engine to digital twins and molecular dynamics software. Create an automated pipeline that allows the AI to trigger virtual experiments, validating theoretical hypotheses before moving to physical trials.
5. Build Research Collaboration Interfaces
Develop intuitive dashboards that allow human scientists to monitor AI agents, visualize complex data, and intervene in the discovery process. Prioritize transparency by providing clear audit trails for every deduction.
6. Launch the Platform and Iterate With Researchers
Deploy the MVP to a controlled research group to gather feedback. Use reinforcement learning from human feedback to refine the engine’s accuracy, ensuring the platform evolves alongside real-world scientific breakthroughs.
Real-World Use Cases of AI Discovery Platforms
AI scientific discovery engine platforms have moved from theoretical potential to practical application, delivering measurable breakthroughs across diverse scientific fields. By combining reasoning with high-performance computing, these platforms solve problems that were previously computationally impossible.

1. AI Drug Discovery Platforms in Biotech
AI accelerates the identification of therapeutic targets and the design of novel molecules. It reduces drug development timelines from years to months by predicting molecular interactions and preclinical safety with high accuracy.
Real-World Platform:
- PandaOmics – Uses multi-omics data and AI models to identify disease targets and generate potential drug candidates.
- AtomNet – Applies deep convolutional neural networks to predict binding between small molecules and proteins.
- Exscientia AI Platform – Designs drug molecules using AI and has produced several candidates that entered clinical trials.
2. AI Materials Science Research Platforms
These platforms utilize generative models to design inorganic materials with specific properties, such as high conductivity or magnetic density. They replace slow trial-and-error laboratory methods with high-speed, physics-informed digital simulations.
Real-World Platform:
- NOMAD AI Toolkit – Uses machine learning to analyze large materials datasets and discover new compounds and semiconductors.
- A-Lab – Combines AI models and robotics to autonomously design and synthesize new materials.
3. AI Climate Modeling and Environmental Research
AI-powered emulators provide weather and climate projections up to 1,000 times faster than traditional physics-based models. These systems help scientists predict rainfall extremes and track deforestation in near real-time.
Real-World Platform:
- GraphCast – An AI weather forecasting system capable of predicting global weather patterns faster and often more accurately than traditional numerical models.
- ClimateNet – Uses machine learning to detect and analyze extreme weather patterns from climate simulation data.
4. Space and Physics Research
In astrophysics, AI platforms process massive sky surveys to identify exoplanets and classify distant galaxies. In physics, “foundational” models learn universal physical laws to simulate complex fluid dynamics or star mergers.
Real-World Platform:
- CERN AI discovery systems – Use machine learning models to analyze data from particle collisions at the Large Hadron Collider to identify rare events and new particles.
- Astroinformatics Platforms – Used in projects analyzing telescope data to detect galaxies, exoplanets, and cosmic phenomena.
5. Genomics and Precision Medicine
AI integrates multi-omics data to decode the human genome and identify disease-causing mutations. This enables “precision medicine,” where treatments are tailored to an individual’s unique genetic profile to maximize efficacy.
Real-World Platform:
- AlphaFold – Predicts the 3D structure of proteins, helping researchers understand disease mechanisms and accelerate drug design.
- Deep Genomics platform – Uses AI to discover RNA-targeted therapies by analyzing genetic variation and biological pathways.
Conclusion
The integration of a specialized AI scientific discovery engine marks a paradigm shift in how we approach the unknown. By unifying symbolic reasoning with high-speed computation, these architectures do more than just process data; they synthesize meaning. As these engines evolve to handle increasingly complex multi-modal inputs, the distance between hypothesis and breakthrough will continue to shrink. Future-proofing your platform with such robust reasoning capabilities ensures that the next great scientific milestone is not just a possibility, but a mathematical certainty.
Why Choose IdeaUsher for Scientific AI Engine Development?
Building AI architecture for scientific discovery requires moving beyond consumer-grade models into the realm of research-grade accuracy, high-performance computing, and rigorous data validation.
We build AI-driven products across industries, specializing in performance systems, model integration, and scalable infrastructure. Our expertise helps us create scientific AI engines that balance computational intensity, result reproducibility, and long-term research sustainability.
Our ex-FAANG and MAANG engineers bring over 500,000+ hours of hands-on AI development experience, allowing us to architect discovery platforms aligned with research workflows, hypothesis testing, and publication-ready validation.
Why Hire Us:
- HPC & AI Expertise: We build high-performance computing systems, deploy advanced AI models, and ensure data integrity, even at petabyte scale across distributed systems.
- Custom Research Solutions: We fine-tune models on proprietary scientific data for platforms with superior analytical precision and a unique edge over general AI solutions.
- Full-Cycle Ownership: We manage infrastructure, ensure research data compliance, and build scalable HPC architectures so your scientific platform is advanced and ready for launch.
FAQs
A.1. A high-performance stack combines Python for model orchestration with C++ or Rust for computational kernels. Specialized libraries like PyTorch or JAX enable the engine to handle the massive parallel processing required for deep scientific simulations.
A.2. Strict data validation pipelines and versioning protocols ensure reliability. Immutable storage solutions and automated metadata extraction make every experimental result reproducible, traceable, and compliant with peer-reviewed research standards.
A.3. The architecture supports horizontal scaling with containerization and microservices. The engine distributes heavy workloads across multiple GPU clusters, maintaining high throughput as the research scope grows and avoiding performance bottlenecks.
A.4. Generative chemistry models and molecular dynamics simulations enable the engine to screen millions of compounds in seconds. This targeted approach identifies high-affinity candidates early, reducing the time and cost of traditional laboratory testing and validation.




















