Today, Large Language Models (LLMs) have emerged as a transformative force, reshaping the way we interact with technology and process information. These models, such as ChatGPT, BARD, and Falcon, have piqued the curiosity of tech enthusiasts and industry experts alike. They possess the remarkable ability to understand and respond to a wide range of questions and tasks, revolutionizing the field of language processing.
As businesses, from tech giants to CRM platform developers, increasingly invest in LLMs and generative AI, the significance of understanding these models cannot be overstated. LLMs are the driving force behind advanced conversational AI, analytical tools, and cutting-edge meeting software, making them a cornerstone of modern technology.
In this blog, we will embark on an enlightening journey to demystify these remarkable models. You will gain insights into the current state of LLMs, exploring various approaches to building them from scratch and discovering best practices for training and evaluation. In a world driven by data and language, this guide will equip you with the knowledge to harness the potential of LLMs, opening doors to limitless possibilities. So, let’s explore the future of AI-powered language processing.
Understanding Large Language Models (LLMs)
A Large Language Model (LLM) is an extraordinary manifestation of artificial intelligence (AI) meticulously designed to engage with human language in a profoundly human-like manner. LLMs undergo extensive training that involves immersion in vast and expansive datasets, brimming with an array of text and code amounting to billions of words. This intensive training equips LLMs with the remarkable capability to recognize subtle language details, comprehend grammatical intricacies, and grasp the semantic subtleties embedded within human language.
The versatile applications of LLMs span a multitude of domains, including:
1. Question Resolution
LLMs excel in addressing an extensive spectrum of queries, irrespective of their complexity or unconventional nature, showcasing their exceptional problem-solving skills.
2. Content Generation
These models possess the prowess to craft text across various genres, undertake seamless language translation tasks, and offer cogent and informative responses to diverse inquiries.
3. Language Transmutation
LLMs adeptly bridge language barriers by effortlessly translating content from one language to another, facilitating effective global communication.
4. Text Condensation
LLMs prove invaluable in condensing lengthy and elaborate textual compositions into concise and digestible formats, facilitating easier comprehension.
5. Chatbot Prowess
These AI marvels empower the development of chatbots that engage with humans in an entirely natural and human-like conversational manner, enhancing user experiences.
6. Virtual Assistants
LLMs serve as the foundation for the creation of virtual assistants, capable of efficiently aiding users in tasks ranging from setting reminders and scheduling appointments to swiftly retrieving pertinent information.
Despite their already impressive capabilities, LLMs remain a work in progress, undergoing continual refinement and evolution. Their potential to revolutionize human-computer interactions holds immense promise. In the foreseeable future, LLMs could potentially elevate computers to the status of highly competent, reliable, and even creatively inventive companions, fundamentally transforming the way we engage with technology.
The Evolution Of Large Language Models
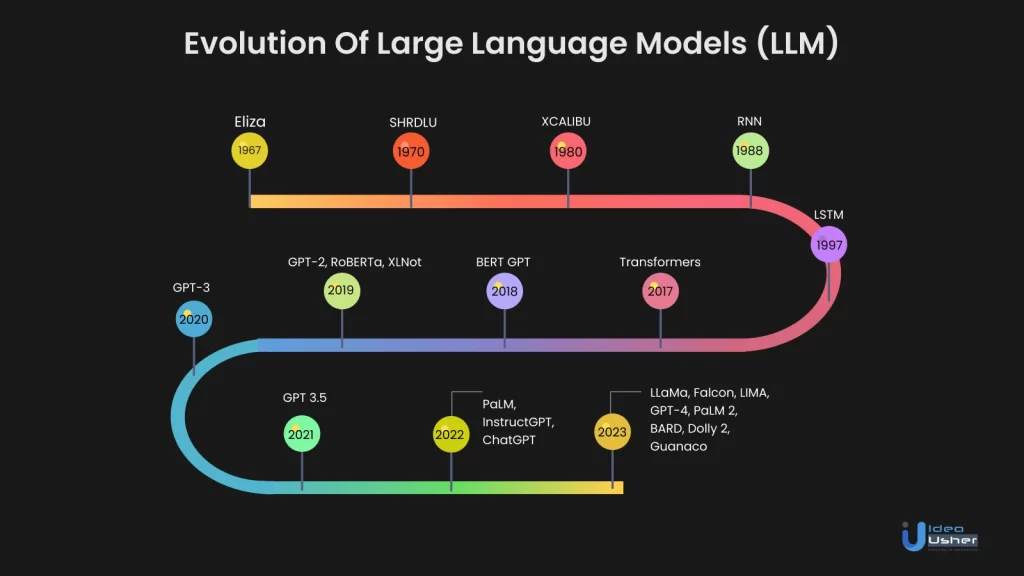
The journey of Large Language Models (LLMs) has been nothing short of remarkable, shaping the landscape of artificial intelligence and natural language processing (NLP) over the decades. Let’s delve into the riveting evolution of these transformative models.
The Birth Of NLP: 1960s
We begin from the 1960s when the first sparks of LLMs were ignited. In 1967, MIT unveiled Eliza, the pioneer in NLP, designed to comprehend natural language. Eliza employed pattern-matching and substitution techniques to engage in rudimentary conversations. This primitive chatbot marked the dawn of NLP. A few years later, in 1970, MIT introduced SHRDLU, another NLP program, further advancing human-computer interaction.
Rise Of RNNs And LSTM: 1980s-1990s
The late 1980s witnessed the emergence of Recurrent Neural Networks (RNNs), designed to capture sequential information in text data. However, RNNs struggled with lengthy sentences. The turning point arrived in 1997 with the introduction of Long Short-Term Memory (LSTM) networks. LSTMs alleviated the challenge of handling extended sentences, laying the groundwork for more profound NLP applications. During this era, attention mechanisms began their ascent in NLP research.
The Transformer Revolution: 2010s
Moving forward to the 2010s, when NLP was poised for a paradigm shift: In 2010, Stanford’s CoreNLP suite equipped researchers with tools to tackle intricate NLP tasks like sentiment analysis and named entity recognition. Google Brain’s 2011 launch provided powerful computing resources and advanced features like word embeddings, enhancing NLP’s contextual understanding. The pivotal moment arrived in 2017 with the inception of the Transformer architecture. Transformers unlocked the potential for larger, more sophisticated LLMs.
GPT And Beyond: 2020s
The subsequent decade witnessed explosive growth in LLM capabilities. OpenAI’s GPT-3 (Generative Pre-Trained Transformer 3), based on the Transformer model, emerged as a milestone. GPT-3’s versatility paved the way for ChatGPT and a myriad of AI applications. User-friendly frameworks like Hugging Face and innovations like BARD further accelerated LLM development, empowering researchers and developers to craft their LLMs.
Applications Of Large Language Models
LLMs are powerful AI algorithms trained on vast datasets encompassing the entirety of human language. Their significance lies in their ability to comprehend human languages with remarkable precision, rivaling human-like responses. These models delve deep into the intricacies of language, grasping syntactic and semantic structures, grammatical nuances, and the meaning of words and phrases. Unlike conventional language models, LLMs are deep learning models with billions of parameters, enabling them to process and generate complex text effortlessly. Their applications span a diverse spectrum of tasks, pushing the boundaries of what’s possible in the world of language understanding and generation.
1. Text Generation
LLMs shine in the art of text generation. These models can effortlessly craft coherent and contextually relevant textual content on a multitude of topics. From generating news articles to producing creative pieces of writing, they offer a transformative approach to content creation. GPT-3, for instance, showcases its prowess by producing high-quality text, potentially revolutionizing industries that rely on content generation.
2. Conversational AI
LLMs are the driving force behind the evolution of conversational AI. They excel in generating responses that maintain context and coherence in dialogues. A standout example is Google’s Meena, which outperformed other dialogue agents in human evaluations. LLMs power chatbots and virtual assistants, making interactions with machines more natural and engaging. This technology is set to redefine customer support, virtual companions, and more.
3. Sentiment Analysis
Understanding the sentiments within textual content is crucial in today’s data-driven world. LLMs have demonstrated remarkable performance in sentiment analysis tasks. They can extract emotions, opinions, and attitudes from text, making them invaluable for applications like customer feedback analysis, brand monitoring, and social media sentiment tracking. These models can provide deep insights into public sentiment, aiding decision-makers in various domains.
4. Efficient Machine Translation
LLMs have ushered in a new era of machine translation. Traditionally, rule-based systems require complex linguistic rules, but LLM-powered translation systems are more efficient and accurate. Google Translate, leveraging neural machine translation models based on LLMs, has achieved human-level translation quality for over 100 languages. This advancement breaks down language barriers, facilitating global knowledge sharing and communication.
5. Code Interpretation
LLMs extend their utility to simplifying human-to-machine communication. For instance, ChatGPT’s Code Interpreter Plugin enables developers and non-coders alike to build applications by providing instructions in plain English. This innovation democratizes software development, making it more accessible and inclusive.
Types And Variants Of LLMs
Large Language Models (LLMs) are redefining how we interact with and understand text-based data. If you are seeking to harness the power of LLMs, it’s essential to explore their categorizations, training methodologies, and the latest innovations that are shaping the AI landscape.
1. Categorization Based On Task
1.1. Continuing the Text LLMs
Examples: Transformers, BERT, XLNet, GPT, GPT-2, GPT-3, GPT-4
Continuing the Text LLMs are designed to predict the next sequence of words in a given input text. Their primary function is to continue and expand upon the provided text. These models can offer you a powerful tool for generating coherent and contextually relevant content.
1.2. Dialogue-optimized LLMs
Examples: InstructGPT, ChatGPT, BARD, Falcon-40B-instruct
Dialogue-optimized LLMs are engineered to provide responses in a dialogue format rather than simply completing sentences. They excel in interactive conversational applications and can be leveraged to create chatbots and virtual assistants.
2. Training Methodologies
The process of developing LLMs involves two fundamental training methodologies:
2.1. Pre-training Models
Examples: GPT-3/GPT-3.5, T5, XLNet
Pre-training models serve as the foundation for LLMs. They are trained on extensive datasets, enabling them to grasp diverse language patterns and structures. You can utilize pre-training models as a starting point for creating custom LLMs tailored to their specific needs.
2.2. Fine-tuning Models
Examples: BERT, RoBERTa, ALBERT
Fine-tuning models built upon pre-trained models by specializing in specific tasks or domains. They are trained on smaller, task-specific datasets, making them highly effective for applications like sentiment analysis, question-answering, and text classification.
3. Architectural Diversity
In LLMs, various architectural choices have been explored to address different types of data, tasks, and objectives. These architectural designs greatly influence an LLM’s performance and suitability for specific applications. Here’s a deeper look into each architectural category:
3.1. Autoencoder-Based Models
This model represents a class of LLMs that operate on the principle of encoding input text into a lower-dimensional representation and then decoding it to generate new text. The key components include an encoder network responsible for capturing essential features from the input and a decoder network that transforms these features into meaningful output. Here are some of the use cases:
- Text Summarization: Autoencoder-based models excel at summarizing lengthy text documents by extracting the most salient information and generating concise summaries.
- Content Generation: They are also used to generate content, which is particularly valuable for tasks like article writing or creative text generation.
3.2. Sequence-to-Sequence Models
Sequence-to-sequence models, often referred to as Seq2Seq models, are designed to process sequences of data, such as sentences or paragraphs, and generate corresponding output sequences. They consist of two primary components: an encoder network that processes the input sequence and a decoder network that generates the output sequence. Here are some of the use cases:
- Machine Translation: Seq2Seq models are widely employed for translating text from one language to another. They take an input sentence in one language and produce a translated sentence in another language.
- Text Summarization: These models are also effective for text summarization tasks, where they take a lengthy document as input and generate a concise summary.
3.3. Transformer-Based Models
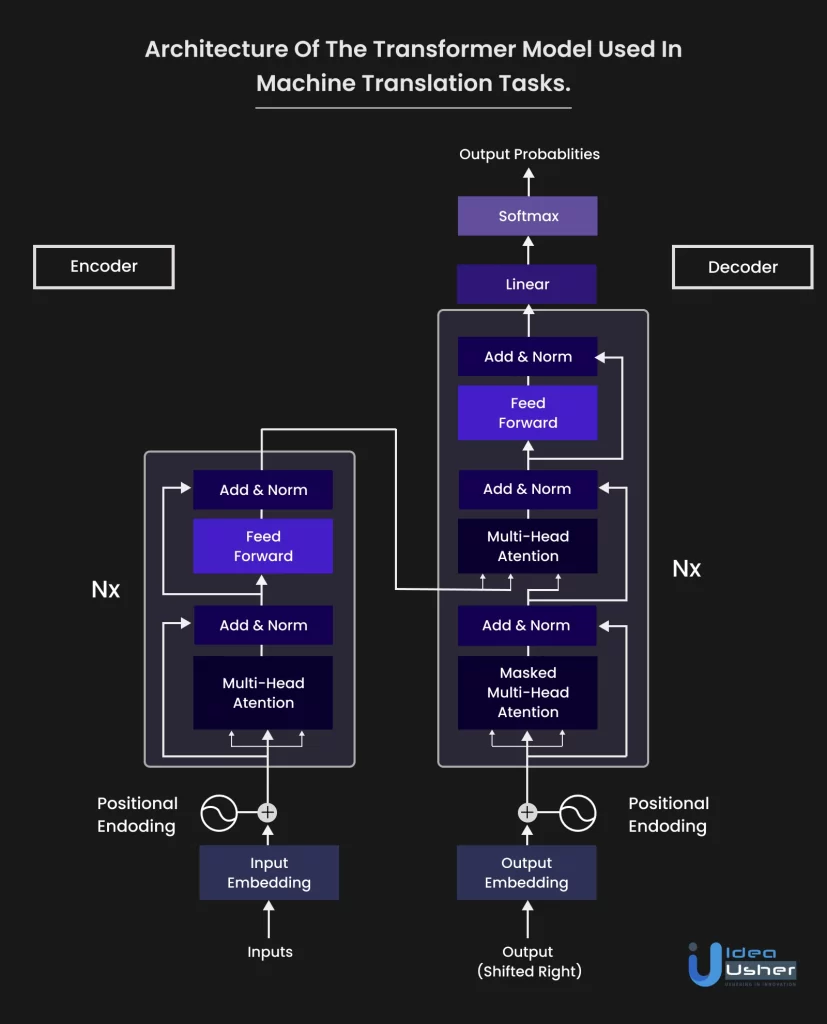
Transformer-based models represent a pivotal breakthrough in LLM architecture. They employ a self-attention mechanism that enables the model to weigh the significance of different words in the input sequence, considering long-range dependencies. The transformer architecture has significantly improved the performance of LLMs. Here are some of the use cases:
- Text Generation: Transformers are known for their excellence in text generation tasks, including creative writing, content generation, and story generation.
- Language Translation: They are widely used for machine translation tasks due to their ability to handle context effectively.
- Question-Answering: Transformers are also employed in question-answering systems, where they understand the context of the question and provide contextually relevant answers.
3.4. Recursive Neural Network Models
These models are designed to handle structured data, such as parse trees that represent the syntactic structure of a sentence. These models process data recursively, which allows them to capture hierarchical relationships within the input. Here are some of the use cases:
- Sentiment Analysis: RNN models are often used for sentiment analysis tasks, where they analyze the sentiment expressed in a piece of text, taking into account the hierarchical structure of language.
- Natural Language Inference: They are suitable for tasks that involve reasoning about relationships between sentences, making them valuable for natural language inference and textual entailment tasks.
3.5. Hierarchical Models
These models are designed to handle text at different levels of granularity, ranging from individual words and phrases to sentences, paragraphs, and entire documents. These models capture information hierarchically, allowing them to understand and process text in context. Here are
some of the use cases:
- Document Classification: Hierarchical models are well-suited for document classification tasks, where they can categorize entire documents into specific topics or categories.
- Topic Modeling: They are valuable for identifying and extracting topics from large volumes of text, making them useful for content analysis and recommendation systems.
How Do Large Language Models Work?
Understanding the intricate workings of Large Language Models (LLMs) is pivotal as these AI marvels continue to transform industries.
1. Foundation of Data
LLMs are the result of extensive training on colossal datasets, typically encompassing petabytes of text. This data forms the bedrock upon which LLMs build their language prowess. The training process primarily adopts an unsupervised learning approach.
2. Word Learning
At the core of LLMs lies the ability to comprehend words and their intricate relationships. Through unsupervised learning, LLMs embark on a journey of word discovery, understanding words not in isolation but in the context of sentences and paragraphs.
3. Transformer Architecture
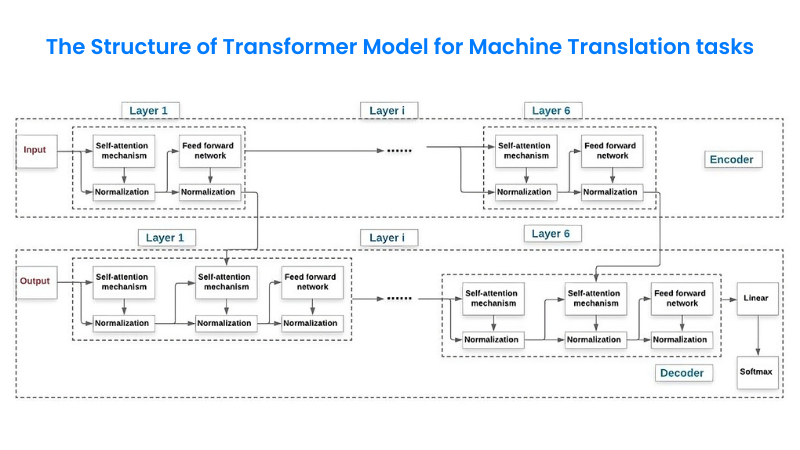
The pivotal Transformer architecture empowers LLMs to excel. It processes entire input sequences holistically, replacing sequential data processing. This architecture comprises two crucial components: the self-attention mechanism and the feedforward neural network.
3.1. Self-Attention Mechanism
This mechanism assigns relevance scores, or weights, to words within a sequence, irrespective of their spatial distance. It enables LLMs to capture word relationships, transcending spatial constraints.
3.2. Feedforward Neural Network
Operating position-wise, this layer independently processes each position in the input sequence. It transforms input vector representations into more nuanced ones, enhancing the model’s ability to decipher intricate patterns and semantic connections.
4. Word Embedding
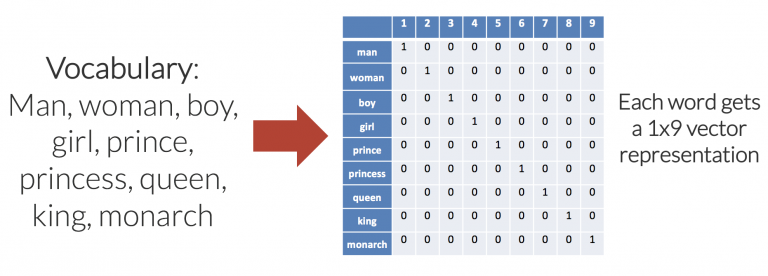
LLMs kickstart their journey with word embedding, representing words as high-dimensional vectors. This transformation aids in grouping similar words together, facilitating contextual understanding.
5. Positional Encoding
Ensuring the model recognizes word order and positional encoding is vital for tasks like translation and summarization. It doesn’t delve into word meanings but keeps track of sequence structure.
6. Customization
LLMs are adaptable. Fine-tuning and prompt engineering allow tailoring them for specific purposes. For instance, Salesforce Einstein GPT personalizes customer interactions to enhance sales and marketing journeys.
7. Text Generation
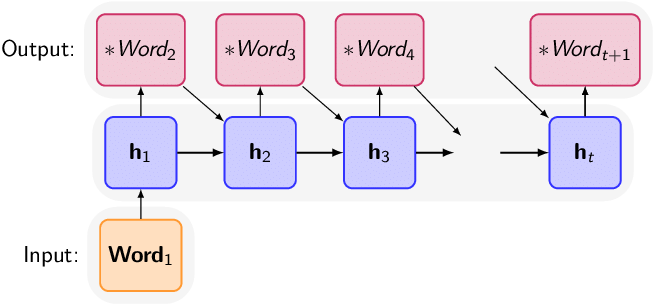
The culmination of LLMs’ prowess lies in text generation. After rigorous training and fine-tuning, these models can craft intricate responses based on prompts. Autoregression, a technique that generates text one word at a time, ensures contextually relevant and coherent responses.
8. Ethical Concerns
LLMs are not without challenges. Ethical considerations, including bias mitigation and interpretability, remain areas of ongoing research. Bias, in particular, arises from the training data and can lead to unfair preferences in model outputs.
Key Terms Of Large Language Models (LLMs)
These key terms serve as the building blocks for unraveling the world of LLMs. Mastery of these concepts empowers AI developers, researchers, and users to navigate the capabilities, challenges, and ethical considerations surrounding Large Language Models effectively. As LLM technology continues to advance, a firm grasp of these terms becomes indispensable in harnessing their potential for diverse applications. Here are the key terms that illuminate the workings and subtle details of LLMs:
1. Word Embedding
At the core of LLMs, word embedding is the art of representing words numerically. It translates the meaning of words into numerical forms, allowing LLMs to process and comprehend language efficiently. These numerical representations capture semantic meanings and contextual relationships, enabling LLMs to discern nuances.
2. Attention Mechanisms
LLMs leverage attention mechanisms, algorithms that empower AI models to focus selectively on specific segments of input text. For example, when generating output, attention mechanisms help LLMs zero in on sentiment-related words within the input text, ensuring contextually relevant responses.
3. Transformers
The backbone of most LLMs, transformers, is a neural network architecture that revolutionized language processing. Unlike traditional sequential processing, transformers can analyze entire input data simultaneously. Comprising encoders and decoders, they employ self-attention layers to weigh the importance of each element, enabling holistic understanding and generation of language.
4. Fine-tuning
This process involves adapting a pre-trained LLM for specific tasks or domains. By training the model on smaller, task-specific datasets, fine-tuning tailors LLMs to excel in specialized areas, making them versatile problem solvers.
5. Prompt Engineering
Crafting input prompts skillfully is an art in itself. LLMs require well-designed prompts to produce high-quality, coherent outputs. These prompts serve as cues, guiding the model’s subsequent language generation, and are pivotal in harnessing the full potential of LLMs.
6. Bias
An inherent concern in AI, bias refers to systematic, unfair preferences or prejudices that may exist in training datasets. LLMs can inadvertently learn and perpetuate biases present in their training data, leading to discriminatory outputs. Mitigating bias is a critical challenge in the development of fair and ethical LLMs.
7. Interpretability
Understanding and explaining the outputs and decisions of AI systems, especially complex LLMs, is an ongoing research frontier. Achieving interpretability is vital for trust and accountability in AI applications, and it remains a challenge due to the intricacies of LLMs.
Build Vs. Buy Pre-Trained LLM Models
When embarking on the journey of leveraging Large Language Models (LLMs), you face a pivotal decision: should you build your own LLM from scratch or opt for pre-trained models that are readily available? There are three fundamental approaches to consider:
Option 1: Utilize a Commercial LLM API
Suppose your team lacks extensive technical expertise, but you aspire to harness the power of LLMs for various applications. Alternatively, you seek to leverage the superior performance of top-tier LLMs without the burden of developing LLM technology in-house. In such cases, employing the API of a commercial LLM like GPT-3, Cohere, or AI21 J-1 is a wise choice.
This option is also valuable when you possess limited training datasets and wish to capitalize on an LLM’s ability to perform zero or few-shot learning. Furthermore, it’s an ideal route for swiftly prototyping applications and exploring the full potential of LLMs.
Option 2: Leverage an Existing Open-Source LLM
When you don’t intend to modify the model architecture significantly, it is generally more advantageous to either adopt an existing pre-trained LLM and fine-tune it or initiate pre-training with the weights of an established pre-trained LLM as your starting point. This approach is highly beneficial because well-established pre-trained LLMs like GPT-J, GPT-NeoX, Galactica, UL2, OPT, BLOOM, Megatron-LM, or CodeGen have already been exposed to vast and diverse datasets.
You can harness the wealth of knowledge they have accumulated, particularly if your training dataset lacks diversity or is not extensive. Additionally, this option is attractive when you must adhere to regulatory requirements, safeguard sensitive user data, or deploy models at the edge for latency or geographical reasons.
Option 3: Self-Preliminary Training or Collaboration with LLM Experts
If you have specific requirements that necessitate altering the model’s architecture or training dataset, then embarking on the journey of self-pre-training or collaborating with LLM consultants and platforms becomes paramount. For example, if you intend to utilize a different tokenizer, modify vocabulary size, or adjust parameters like the number of hidden dimensions, attention heads, or layers, this option provides the flexibility to tailor the LLM to your unique needs.
Typically, this path is chosen when the LLM forms a central element of your business strategy and technological advantage. It signifies your commitment to innovation in LLM training and your readiness to invest in the ongoing development and maintenance of sophisticated models. Additionally, if you anticipate having proprietary data associated with your LLM, this approach facilitates the creation of a continuous model improvement loop, fostering sustainable competitive advantages.
The decision to build or buy pre-trained LLM models hinges on factors like your team’s technical expertise, the scale and diversity of your training data, regulatory constraints, deployment requirements, and your long-term business strategy. Each option has its merits, and the choice should align with your specific goals and resources.
Understanding The Scaling Laws
The path to harnessing the full potential of LLM is paved with crucial questions, primarily centered around the size of the dataset and the model itself. When embarking on the journey of training LLMs from scratch, it’s imperative to ponder these fundamental questions:
1. How Much Data is Required?
The answers to these critical questions can be found in the realm of scaling laws. Scaling laws are the guiding principles that unveil the optimal relationship between the volume of data and the size of the model.
In 2022, DeepMind unveiled a groundbreaking set of scaling laws specifically tailored to LLMs. Known as the “Chinchilla” or “Hoffman” scaling laws, they represent a pivotal milestone in LLM research.
2. The Token-Parameter Symbiosis
At the bottom of these scaling laws lies a crucial insight – the symbiotic relationship between the number of tokens in the training data and the parameters in the model.
According to the Chinchilla scaling laws, the number of tokens used for training should be approximately 20 times greater than the number of parameters in the LLM. For example, to train a data-optimal LLM with 70 billion parameters, you’d require a staggering 1.4 trillion tokens in your training corpus. This ratio of 20 text tokens per parameter emerges as a key guideline.

3. Practical Implications
Understanding these scaling laws empowers researchers and practitioners to fine-tune their LLM training strategies for maximal efficiency. These laws also have profound implications for resource allocation, as it necessitates access to vast datasets and substantial computational power.
It also helps in striking the right balance between data and model size, which is critical for achieving both generalization and performance. Oversaturating the model with data may not always yield commensurate gains.
4. Beyond DeepMind’s Revelation
While DeepMind’s scaling laws are seminal, the landscape of LLM research is ever-evolving. Researchers continue to explore various aspects of scaling, including transfer learning, multitask learning, and efficient model architectures.
Beyond the theoretical underpinnings, practical guidelines are emerging to navigate the scaling terrain effectively. These encompass data curation, fine-grained model tuning, and energy-efficient training paradigms.
By embracing these scaling laws and staying attuned to the evolving landscape, we can unlock the true potential of Large Language Models while treading responsibly in the age of AI.
How Do You Train LLMs from Scratch?
The success of LLMs hinges on two critical factors: the quality of the dataset and the choice of model architecture. Here is the step-by-step process of training LLMs from scratch, covering both text continuation and dialogue-optimized models.
Section 1: Training LLMs for Text Continuation
Text continuation LLMs, often referred to as pre-training LLMs, are trained in a self-supervised learning fashion to predict the next word in a given text. Here are the key steps involved in training them:
1.1. Dataset Collection
The initial step in training text continuation LLMs is to amass a substantial corpus of text data. The dataset’s quality is paramount for LLM performance. Recent successes, like OpenChat, can be attributed to high-quality data, as they were fine-tuned on a relatively small dataset of approximately 6,000 examples.
Datasets are typically created by scraping data from the internet, including websites, social media platforms, academic sources, and more. The diversity of the training data is crucial for the model’s ability to generalize across various tasks.
For example, datasets like Common Crawl, which contains a vast amount of web page data, were traditionally used. However, new datasets like Pile, a combination of existing and new high-quality datasets, have shown improved generalization capabilities.
1.2. Dataset Preprocessing
Cleaning and preprocessing the dataset are crucial steps to eliminate noise and ensure high-quality training data. Common preprocessing tasks include:
- Removing HTML code.
- Correcting spelling mistakes.
- Filtering out toxic or biased content.
- Converting emojis into their text equivalents.
- Deduplicating data to prevent the model from memorizing redundant information.
Data deduplication is especially significant as it helps the model avoid overfitting and ensures unbiased evaluation during testing.
1.3. Dataset Preparation
Creating input-output pairs is essential for training text continuation LLMs. During pre-training, LLMs learn to predict the next token in a sequence. Typically, each word is treated as a token, although subword tokenization methods like Byte Pair Encoding (BPE) are commonly used to break words into smaller units.
For example, given the sentence: “I am a DHS Chatbot,” input-output pairs can be created as follows:
Input: “I am a DHS”
Output: “Chatbot”
Each input-output pair serves as a training example for the model.
1.4. Model Architecture
Choosing an appropriate model architecture is a critical step. Researchers often start with existing large language models like GPT-3 and adjust hyperparameters, model architecture, or datasets to create new LLMs. For example, Falcon is inspired by the GPT-3 architecture with specific modifications.
1.5. Hyperparameter Search
Hyperparameter tuning is a resource-intensive process. Researchers typically use existing hyperparameters, such as those from GPT-3, as a starting point. Fine-tuning on a smaller scale and interpolating hyperparameters is a practical approach to finding optimal settings. Key hyperparameters include batch size, learning rate scheduling, weight initialization, regularization techniques, and more.
Section 2: Training Dialogue-Optimized LLMs
Dialogue-optimized LLMs build upon the pre-training process and are further fine-tuned on dialogue-specific datasets. Here’s how you can train them:
2.1. Pre-training
Dialogue-optimized LLMs undergo the same pre-training steps as text continuation models. They are trained to complete text and predict the next token in a sequence.
2.2. Supervised Fine-Tuning
After pre-training, these models are fine-tuned on supervised datasets containing questions and corresponding answers. This fine-tuning process equips the LLMs to generate answers to specific questions.
2.3. Recent Advancements
Recent research, exemplified by OpenChat, has shown that you can achieve remarkable results with dialogue-optimized LLMs using fewer than 1,000 high-quality examples. The emphasis is on pre-training with extensive data and fine-tuning with a limited amount of high-quality data.
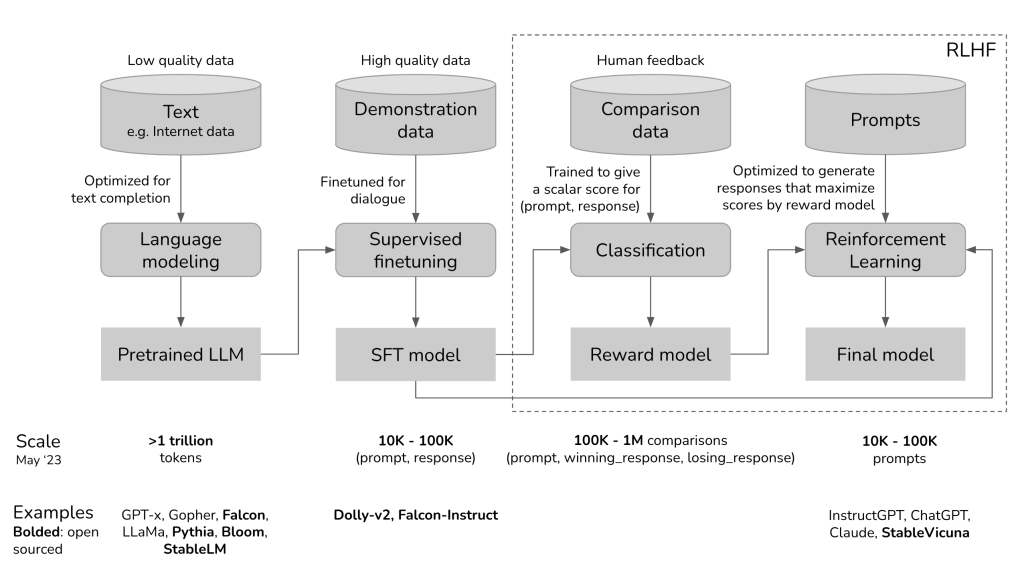
How To Build A Private LLM?
Building a private Large Language Model (LLM) is a complex undertaking that requires a deep understanding of natural language processing, access to significant computational resources, and expertise in training and fine-tuning machine learning models. Here is the step-by-step process of creating your private LLM, ensuring that you have complete control over your language model and its data.
Step 1: Define Your Objectives
Before embarking on the journey of building a private LLM, it’s crucial to define your specific objectives and use cases. Consider the following questions:
- What is the primary purpose of your LLM?
- What tasks or domains do you want your model to excel in?
- What size and scale of data do you have access to for training?
- What privacy and security measures do you need to implement to protect sensitive information?
Answering these questions will help you shape the direction of your LLM project and make informed decisions throughout the process.
Step 2: Select The Training Data
The quality and diversity of your training data are paramount to the success of your LLM. Your training data should ideally cover a wide range of text sources relevant to your objectives. Consider the following aspects:
- Data Collection: Decide whether you will collect data from scratch, use existing datasets, or curate a custom dataset.
- Data Sources: Identify authoritative sources and ensure they align with your objectives.
- Data Preprocessing: Implement tokenization and subword encoding techniques to prepare your data for training.
- Data Augmentation: Consider using paraphrasing models to generate additional training data and improve model robustness.
Step 3: Choose Your Base Model
Selecting the right base model is a critical decision in LLM development. Depending on your objectives and resources, you might choose a different base model. Key considerations include:
- Model Size: Decide on the size and complexity of your base model, considering factors like the number of parameters.
- Pretrained Models: Explore available pretrained models, such as GPT-3, BERT, or RoBERTa, and evaluate their suitability for your use case.
- Specialized Architectures: Assess whether specialized architectures are needed for your tasks.
Step 4: Data Processing And Tokenization
To prepare your data for training, you must implement data processing and tokenization procedures. Key steps include:
- Load Libraries: Import the necessary libraries for data processing, including tokenization, batching, and model training.
- Load Training Dataset: Load your training dataset, ensuring it adheres to the structure required by your chosen model.
- Tokenization: Use a tokenizer tied to your base model to tokenize and encode your text data.
- Data Collation: Combine sequences of input data into batches suitable for language model training.
Step 5: Model Training
Training your LLM involves several key components:
- Model and Tokenizer: Instantiate your chosen base model and its corresponding tokenizer.
- Training Data: Utilize your preprocessed and tokenized training dataset.
- Training Configuration: Define training parameters such as batch size, learning rate, and the number of training epochs.
- Training Process: Employ a deep learning framework or library (e.g., PyTorch or TensorFlow) to train your model.
- Optimization Techniques: Consider techniques like gradient checkpointing and mixed-precision training to enhance training efficiency.
Step 6: Model Evaluation
Assessing the performance of your LLM is crucial. Consider the following evaluation methods:
- Perplexity: Calculate perplexity scores to measure your model’s predictive capabilities. Lower perplexity indicates better performance.
- Human Evaluation: Engage human evaluators to assess the coherence, fluency, and overall quality of the generated text.
- Benchmarking: Compare your LLM’s performance with other state-of-the-art models in relevant tasks.
Step 7: Feedback And Iteration
Building a private LLM is an iterative process that involves continuous improvement. Gather feedback through various means, including:
- User Surveys: Collect user feedback on the model’s performance and user experience.
- Usage Metrics: Monitor usage metrics to understand how users interact with your LLM.
- Error Analysis: Analyze model errors to identify areas for improvement.
Based on feedback, you can iterate on your LLM by retraining with new data, fine-tuning the model, or making architectural adjustments.
Evaluate LLMs
Evaluating Large Language Models (LLMs) is a crucial step in their development and deployment, ensuring that they meet the desired standards of performance and reliability. The evaluation process involves assessing various aspects of the LLM’s capabilities, including text generation and response to input. There are two primary methods for evaluating LLMs: intrinsic and extrinsic.
1. Intrinsic Methods
Intrinsic methods focus on evaluating the LLM’s ability to predict the next word in a sequence. These methods utilize traditional metrics such as perplexity and bits per character.
- Perplexity: Perplexity is a commonly used metric that measures how well an LLM predicts the next word in a sequence of words. Lower perplexity scores indicate better predictive performance.
- Bits per Character: This metric assesses the efficiency of the language model in encoding text. It measures how many bits are needed to represent each character, with lower values indicating more efficient encoding.
2. Extrinsic Methods
Extrinsic methods evaluate the LLM’s performance on specific tasks, such as problem-solving, reasoning, mathematics, and competitive exams. These methods provide a practical assessment of the LLM’s utility in real-world applications.
Frameworks like the Language Model Evaluation Harness by EleutherAI and Hugging Face’s integrated evaluation framework are invaluable tools for comparing and evaluating LLMs. These frameworks facilitate comprehensive evaluations across multiple datasets, with the final score being an aggregation of performance scores from each dataset.
The datasets used for evaluation play a critical role in assessing LLMs’ capabilities. Some notable evaluation datasets include:
- AI2 Reasoning Challenge: This dataset comprises science questions designed for elementary school students. It tests the LLM’s ability to answer questions based on scientific knowledge.
- HellaSwag: HellaSwag is a test that challenges LLMs to make common-sense inferences. It assesses the model’s capacity to reason and make logical conclusions.
- MMLU: The MMLU dataset is a comprehensive evaluation test that measures the multitask accuracy of a text model. It covers a wide range of subjects, including basic math, U.S. history, computer science, law, and more.
- TruthfulQA: TruthfulQA is specifically designed to assess a model’s ability to generate accurate answers and avoid reproducing false information commonly found online. It evaluates the model’s reliability in providing truthful responses.
Evaluating LLMs is a multidimensional process that demands a comprehensive performance evaluation framework. This framework considers various features, including:
- Language Fluency: Assessing how smoothly and naturally the LLM generates text.
- Coherence: Evaluating the logical flow and organization of the generated text.
- Context Comprehension: Measuring the LLM’s ability to understand and respond appropriately to context.
- Speech Recognition: If applicable, evaluate the model’s performance in converting spoken language to text.
- Fact-Based Accuracy: Ensuring that the LLM provides accurate and factually correct information.
- Relevance: Assessing the model’s capacity to generate responses that are pertinent and contextually significant.
To quantify and compare LLM performance, various metrics come into play, including perplexity, BLEU score (which measures the quality of machine-generated text), and human evaluations, where human assessors provide judgments on the quality and appropriateness of LLM-generated responses.
Evaluating LLMs is a multifaceted process that relies on diverse evaluation datasets and considers a range of performance metrics. This rigorous evaluation ensures that LLMs meet the high standards of language generation and application in real-world scenarios.
What Are The Challenges Of Training LLM?
Training Large Language Models (LLMs) is fraught with multifaceted challenges that span infrastructure, cost, computational resources, data collection and preprocessing, toxicity mitigation, training time, overfitting, and environmental impact. Here are these challenges and their solutions to propel LLM development forward.
1. Infrastructure And Scalability
Training LLMs necessitates colossal infrastructure, as these models are built upon massive text corpora exceeding 1000 GBs. They encompass billions of parameters, rendering single GPU training infeasible. To overcome this challenge, organizations leverage distributed and parallel computing, requiring thousands of GPUs.
Solutions:
- Employ advanced parallelism methods, such as tensor parallelism (TP), pipeline parallelism (PP), and data parallelism (DP), in conjunction with ZeRO optimization techniques.
- Collaborate with cloud providers like AWS, Google Cloud, or Microsoft Azure to access scalable computing resources.
- Optimize the model architecture to reduce unnecessary complexity and parameters, enhancing training efficiency.
- Explore model compression techniques such as pruning, quantization, and knowledge distillation to reduce the model size and computational requirements.
- Optimize the model architecture by reducing the number of layers, including essential features, and eliminating redundancy, ultimately reducing the need for extensive computational resources.
2. Cost Considerations
The exorbitant cost of setting up and maintaining the infrastructure needed for LLM training poses a significant barrier. GPT-3, with its 175 billion parameters, reportedly incurred a cost of around $4.6 million dollars.
Solutions:
- Seek funding from research institutions or organizations with access to high-performance hardware.
- Implement resource allocation optimization techniques to minimize expenditure.
- Consider energy-efficient GPUs and TPUs to reduce long-term operational costs.
- Further, optimize resource allocation strategies to minimize costs through methods like spot instances or co-training with other projects.
- Explore knowledge distillation techniques to transfer knowledge from larger models to smaller, more cost-effective ones.
3. Data Collection and Preprocessing
Acquiring and preprocessing diverse, high-quality training datasets is labor-intensive, and ensuring data represents diverse demographics while mitigating biases is crucial.
Solutions:
- Leverage publicly available datasets relevant to the task to expedite data collection.
- Employ data augmentation techniques such as back-translation, word replacement, and sentence shuffling to enrich training data.
- Enhance diversity and quality through crowdsourcing data collection and annotation, ensuring a broad representation.
- Implement active learning techniques to focus data collection efforts on instances where the model performs poorly, reducing the overall data collection burden.
- Deploy advanced techniques like adversarial debiasing and fairness-aware training to address biases more effectively.
- Establish robust data quality metrics to assess the representativeness and diversity of the dataset effectively.
4. Toxic or Wrong Data Generation
Models may inadvertently generate toxic or offensive content, necessitating strict filtering mechanisms and fine-tuning on curated datasets.
Solutions:
- Implement strict content filtering mechanisms to remove offensive or harmful content during generation.
- Train models to recognize and reject toxic inputs through adversarial training, enhancing content safety.
- Employ human reviewers to actively monitor and moderate the outputs generated by the model, ensuring ethical usage.
- Highlight the importance of ethical considerations in data filtering and moderation, emphasizing the responsible use of AI models.
- Encourage users to provide feedback on problematic outputs to improve the model’s behavior iteratively.
- Collaborate with the community to establish guidelines and best practices for the responsible use of large language models.
5. Training Time And Iterations
LLM training is time-consuming, hindering rapid experimentation with architectures, hyperparameters, and techniques.
Solutions:
- Utilize distributed computing frameworks and hardware to parallelize training across multiple GPUs or machines.
- Employ powerful hardware accelerators like GPUs or TPUs to accelerate training speed.
- Implement early stopping techniques to avoid unnecessary iterations and save intermediate model checkpoints.
- Explore transfer learning techniques that enable quicker fine-tuning on pre-trained models, reducing training time.
- Utilize efficient hyperparameter optimization methods like Bayesian optimization to expedite model convergence.
6. Overfitting And Generalization
Overfitting is a persistent challenge, demanding increased training data, data augmentation, and regularization techniques like dropout.
Solutions:
- Generate additional training examples using techniques like back-translation and word replacement to improve data diversity.
- Implement regularization techniques such as dropout to reduce over-reliance on specific features.
- Perform cross-validation to assess the model’s generalization ability.
- Describe recent advances in regularization techniques, such as mixup, cutmix, and label smoothing, to mitigate overfitting more effectively.
- Introduce continual learning methods that enable models to adapt to new data while retaining knowledge from previous training, improving generalization.
7. Environmental Impact
Large language model training consumes substantial energy, contributing to environmental concerns. Strategies for energy efficiency are essential.
Solutions:
- Use energy-efficient hardware solutions like GPUs or TPUs to reduce energy consumption.
- Highlight research on energy-efficient training algorithms that prioritize energy conservation.
- Ensure data centers hosting the training infrastructure are optimized for energy efficiency.
- Explain how model quantization and weight pruning can significantly reduce energy requirements during inference without sacrificing performance.
- Optimize the scheduling of training jobs to take advantage of periods with lower energy demand or cleaner energy sources.
Why Are LLMs Becoming Important To Businesses?
Businesses are witnessing a remarkable transformation, and at the forefront of this transformation are Large Language Models (LLMs) and their counterparts in machine learning. As organizations embrace AI technologies, they are uncovering a multitude of compelling reasons to integrate LLMs into their operations.
1. Enhanced Efficiency
LLMs empower businesses to streamline their operations. These models excel at automating tasks that were once time-consuming and labor-intensive. From data analysis to content generation, LLMs can handle a wide array of functions, freeing up human resources for more strategic endeavors.
2. Heightened Effectiveness
The effectiveness of LLMs in understanding and processing natural language is unparalleled. They can rapidly analyze vast volumes of textual data, extract valuable insights, and make data-driven recommendations. This ability translates into more informed decision-making, contributing to improved business outcomes.
3. Enhanced User Experience
LLMs are instrumental in enhancing the user experience across various touchpoints. Chatbots and virtual assistants powered by these models can provide customers with instant support and personalized interactions. This fosters customer satisfaction and loyalty, a crucial aspect of modern business success.
4. Business Evolution
To thrive in today’s competitive landscape, businesses must adapt and evolve. LLMs facilitate this evolution by enabling organizations to stay agile and responsive. They can quickly adapt to changing market trends, customer preferences, and emerging opportunities.
5. Innovative Solutions
LLMs are at the forefront of innovation. Their natural language processing capabilities open doors to novel applications. For instance, they can be employed in content recommendation systems, voice assistants, and even creative content generation. This innovation potential allows businesses to stay ahead of the curve.
6. Data-Driven Decision-Making
In the era of big data, data-driven decision-making is paramount. LLMs can ingest and analyze vast datasets, extracting valuable insights that might otherwise remain hidden. These insights serve as a compass for businesses, guiding them toward data-driven strategies.
7. Competitive Advantage
Early adoption of LLMs can confer a significant competitive advantage. Businesses that harness the power of these models can differentiate themselves in the market, offering superior customer experiences, more efficient processes, and innovative solutions that competitors struggle to match.
8. Scaling Operations
LLMs facilitate scalable operations. As business volumes grow, these models can handle increased workloads without a linear increase in resources. This scalability is particularly valuable for businesses experiencing rapid growth.
9. Cost Savings
Automation through LLMs can lead to substantial cost savings. By automating repetitive tasks and improving efficiency, organizations can reduce operational costs and allocate resources more strategically.
10. Global Reach
Language is no longer a barrier for businesses. LLMs can assist in language translation and localization, enabling companies to expand their global reach and cater to diverse markets.
Case Study: The Defining Force of Large Language Models
In artificial intelligence, large language models (LLMs) have emerged as the driving force behind transformative advancements. The recent public beta release of ChatGPT has ignited a global conversation about the potential and significance of these models. To delve deeper into the realm of LLMs and their implications, we interviewed Martynas Juravičius, an AI and machine learning expert at Oxylabs, a leading provider of web data acquisition solutions. Joining the discussion were Adi Andrei and Ali Chaudhry, members of Oxylabs’ AI advisory board.
Understanding Large Language Models
Adi Andrei explained that LLMs are massive neural networks with billions to hundreds of billions of parameters trained on vast amounts of text data. Their unique ability lies in deciphering the contextual relationships between language elements, such as words and phrases. For instance, understanding the multiple meanings of a word like “bank” in a sentence poses a challenge that LLMs are poised to conquer. Recent developments have propelled LLMs to achieve accuracy rates of 85% to 90%, marking a significant leap from earlier models.
Shaping The Future Of Technology
As LLMs continue to evolve, they are poised to revolutionize various industries and linguistic processes. The shift from static AI tasks to comprehensive language understanding is already evident in applications like ChatGPT and Github Copilot. These models will become pervasive, aiding professionals in content creation, coding, and customer support.
Applications In Business And Individual Use
Ali Chaudhry highlighted the flexibility of LLMs, making them invaluable for businesses. E-commerce platforms can optimize content generation and enhance work efficiency. Moreover, LLMs may assist in coding, as demonstrated by Github Copilot. They also offer a powerful solution for live customer support, meeting the rising demands of online shoppers.
Impact On The Economy And Businesses
The far-reaching effects of LLMs on the economy are undeniable. As they become more independent from human intervention, LLMs will augment numerous tasks across industries, potentially transforming how we work and create. The emergence of new AI technologies and tools is expected, impacting creative activities and traditional processes.
Potential Flaws And Biases
Adi Andrei pointed out the inherent limitations of machine learning models, including stochastic processes and data dependency. LLMs, dealing with human language, are susceptible to interpretation and bias. They rely on the data they are trained on, and their accuracy hinges on the quality of that data. Biases in the models can reflect uncomfortable truths about the data they process.
Optimizing Data Gathering For Llms
Martynas Juravičius emphasized the importance of vast textual data for LLMs and recommended diverse sources for training. Digitized books provide high-quality data, but web scraping offers the advantage of real-time language use and source diversity. Web scraping, gathering data from the publicly accessible internet, streamlines the development of powerful LLMs.
Large language models, like ChatGPT, represent a transformative force in artificial intelligence. Their potential applications span across industries, with implications for businesses, individuals, and the global economy. While LLMs offer unprecedented capabilities, it is essential to address their limitations and biases, paving the way for responsible and effective utilization in the future.
Conclusion
Large Language Models (LLMs) such as GPT-3 are reshaping the way we engage with technology, owing to their remarkable capacity for generating contextually relevant and human-like text. Their indispensability spans diverse domains, ranging from content creation to the realm of voice assistants. Nonetheless, the development and implementation of an LLM constitute a multifaceted process demanding an in-depth comprehension of Natural Language Processing (NLP), data science, and software engineering. This intricate journey entails extensive dataset training and precise fine-tuning tailored to specific tasks.
In collaboration with our team at Idea Usher, experts specializing in LLMs, businesses can fully harness the potential of these models, customizing them to align with their distinct requirements. Our unwavering support extends beyond mere implementation, encompassing ongoing maintenance, troubleshooting, and seamless upgrades, all aimed at ensuring the LLM operates at peak performance.
Embark on a journey of discovery and elevate your business by embracing tailor-made LLMs meticulously crafted to suit your precise use case. Connect with our team of AI specialists, who stand ready to provide consultation and development services, thereby propelling your business firmly into the future.


Contact Idea Usher at [email protected]
FAQ
Q. What are the training parameters in LLMs?
Training parameters in LLMs consist of various factors, including learning rates, batch sizes, optimization algorithms, and model architectures. These parameters are crucial as they influence how the model learns and adapts to data during the training process.
Q. What does setting up the training environment involve?
Setting up the training environment is a multifaceted process. It entails configuring the hardware infrastructure, such as GPUs or TPUs, to handle the computational load efficiently. Additionally, it involves installing the necessary software libraries, frameworks, and dependencies, ensuring compatibility and performance optimization.
Q. How is the performance of a trained LLM evaluated?
The evaluation of a trained LLM’s performance is a comprehensive process. It involves measuring its effectiveness in various dimensions, such as language fluency, coherence, and context comprehension. Metrics like perplexity, BLEU score, and human evaluations are utilized to assess and compare the model’s performance. Additionally, its aptitude to generate accurate and contextually relevant responses is scrutinized to determine its overall effectiveness.
Q. How long does it take to train an LLM from scratch?
Training a Large Language Model (LLM) from scratch is a resource-intensive endeavor. The time required varies significantly based on several factors. For example, training GPT-3 from scratch on a single NVIDIA Tesla V100 GPU would take approximately 288 years, highlighting the need for distributed and parallel computing with thousands of GPUs. The exact duration depends on the LLM’s size, the complexity of the dataset, and the computational resources available. It’s important to note that this estimate excludes the time required for data preparation, model fine-tuning, and comprehensive evaluation.